
Python中的併發程式設計(2): 並行與併發
並行與併發
很多人都會有一個問題,併發(Concurrency)和並行(Parallelism)是一個概念嗎?它們之間有什麼區別呢?只有在充分了解概念的情況下,才能在接下來的學習中,不被文獻中充斥的各種概念弄混淆;在實踐中,也能更好的選擇實現手段。
一般說來,併發,指的是多個任務能夠同時存在,是否同時執行並不重要,而並行,主要側重於多個任務之間能夠同時進行。所以,我們也可以理解為並行是併發的一個子集。

如上圖所示,大家分為兩隊去接飲料,這就是併發。大家分兩隊,同時分別去兩個飲料機接飲料,這就是並行。
併發系統的一些特性
- 包含多個操作
- 擁有共享的資源:記憶體,硬碟或者其他資源
- 遵從一些規則:只有所有的操作都嚴格的遵循一定的規則,整個系統才能按照期待的方向發展
效能瓶頸
併發程式設計一般都是用於解決一些效能問題,主要的效能問題有兩種,I/O效能瓶頸,CPU效能瓶頸。
I/O瓶頸
這種情況下,程式主要阻塞在輸入輸出等部分。例如網路爬蟲。
CPU瓶頸
這種情況下,程式主要阻塞在計算部分。主要由時鐘頻率和CPU的核心個數影響。
使用單核優點:
- 不需要很複雜的通訊協定
- 消耗電能更小,適合於物聯網。
使用單核缺點:
- 處理速度有限
反過來就是多核的優缺點了。就不一一說明。
任務排程
在這兒只是說明任務排程的複雜性和重要性,至於如何安排任務,在以後會進行詳細說明。 併發程式的多個執行緒之間的運作方式有很大的不確定性,如果不加以控制的話,程式執行的結果也會有很強的不確定性。這裡以一個經典的生產者,消費者模型/使用場景為例進行說明。
#!/usr/bin/env python # -*- coding: utf-8 -*- import threading import time import random counter = 1 def workerA(): global counter while counter < 1000: counter += 1 print("Worker A is incrementing counter to {}".format(counter)) sleepTime = random.randint(0,1) time.sleep(sleepTime) def workerB(): global counter while counter > -1000: counter -= 1 print("Worker B is decrementing counter to {}".format(counter)) sleepTime = random.randint(0,1) time.sleep(sleepTime) def main(): t0 = time.time() thread1 = threading.Thread(target=workerA) thread2 = threading.Thread(target=workerB) thread1.start() thread2.start() thread1.join() thread2.join() t1 = time.time() print("Execution Time {}".format(t1-t0)) if __name__ == '__main__': main()
系統架構
在正式程式設計之前,還是要介紹下目前的系統架構,主要分為 SISD, SIMD, MISD, MIMD四種。直接從wiki上搬運些資料吧。原地址:費林分類法
SISD
單指令流單資料流(英文:Single instruction, single data,縮寫:SISD),每個指令部件每次僅譯碼一條指令,而且在執行時僅為操作部件提供一份資料。符合馮·諾伊曼結構。
單指令流單資料流是費林分類法中4種計算機處理架構類別的一種。在這個分類系統中,分類根據是指令流和資料流的數量,以此根據來劃分計算機處理架構的類別。根據米高·J·費林的觀點,當指令、資料處理流水化/管線化時,單指令流單資料流也可以擁有平行計算的特點。管線化的指令讀取執行在當代的單指令流單資料流處理機種上很常見。

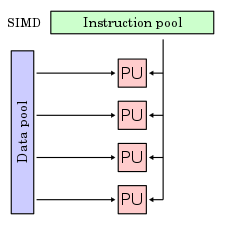
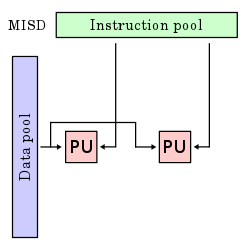
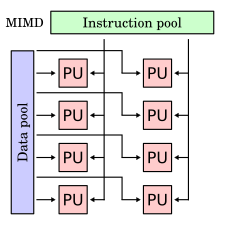
註明: PU 指的是程式單元(processing unit)
SIMD
單指令流多資料流(英語:Single Instruction Multiple Data,縮寫:SIMD)是一種採用一個控制器來控制多個處理器,同時對一組資料(又稱“資料向量”)中的每一個分別執行相同的操作從而實現空間上的並行性的技術。
在微處理器中,單指令流多資料流技術則是一個控制器控制多個平行的處理微元,例如Intel的MMX或SSE,以及AMD的3D Now!指令集。
圖形處理器(GPU)擁有強大的併發處理能力和可程式設計流水線,面對單指令流多資料流時,運算能力遠超傳統CPU。OpenCL和CUDA分別是目前最廣泛使用的開源和專利通用圖形處理器(GPGPU)運算語言。
MISD
多指令流單資料流(Multiple Instruction stream Single Datastream, MISD)是平行計算機的一種結構。MISD具有n個處理單元,按n條不同指令的要求對同一資料流及其中間結果進行不同的處理。一個處理單元的輸出又作為另一個處理單元的輸入。
嚴格意義上,採用這種結構的計算機至今沒有出現,但是已經有了近似的例子。在流水線結構中,一條指令的執行過程被分為多個步驟,並且交給不同的硬體處理單元,以加快指令的執行速度。
MIMD
多指令流多資料流(Multiple Instruction Stream Multiple Data Stream,縮寫:MIMD),是使用多個控制器來非同步地控制多個處理器,從而實現空間上的並行性的技術。
計算機的記憶體模式
在正式開始程式設計之前,計算機的記憶體模式也是需要做了解的概念。
均勻訪存模型(UMA)
均勻訪存模型(Uniform Memory Access)通常簡稱UMA,指所有的物理儲存器被均勻共享,即處理器訪問它們的時間是一樣的。UMA亦稱作統一定址技術或統一記憶體存取。
這種系統因為高度的資源共享也被稱為緊耦合系統(Tightly Coupled System)。

這種模式的好處是,快取都是一致的,硬體也容易設計,但是不利於擴充套件。
非統一記憶體訪問架構(NUMA)
非統一記憶體訪問架構(英語:Non-uniform memory access,簡稱NUMA)是一種為多處理器的電腦設計的記憶體,記憶體訪問時間取決於記憶體相對於處理器的位置。在NUMA下,處理器訪問它自己的本地記憶體的速度比非本地記憶體(記憶體位於另一個處理器,或者是處理器之間共享的記憶體)快一些。
非統一記憶體訪問架構的特點是:被共享的記憶體物理上是分散式的,所有這些記憶體的集合就是全域性地址空間。所以處理器訪問這些記憶體的時間是不一樣的,顯然訪問本地記憶體的速度要比訪問全域性共享記憶體或遠端訪問外地記憶體要快些。另外,NUMA中記憶體可能是分層的:本地記憶體,群內共享記憶體,全域性共享記憶體。

這種模式利於擴充套件,但是處理器對於不同位置的記憶體的訪問速度不一致,並且多個處理器之間需要識別並維護記憶體內容的一致性。
總結
本節也只是對一般的概念做介紹,即使不需要使用python,但是對併發感興趣的同學也可以瞭解下相關的概念。