
用Python和OpenCV實現照片馬賽克拼圖(蒙太奇照片)
馬賽克拼圖介紹:
相片馬賽克(Photomosaic),或稱蒙太奇照片、蒙太奇拼貼,是一種影像處理的藝術技巧,利用這個方式做出來的圖片,近看時是由許多張小照片合在一起的,但遠看時,每張照片透過光影和色彩的微調,組成了一張大圖的基本畫素,就叫做相片馬賽克技巧。最先是由一個美國大學生髮明的,但當時限於計算機效能,無法大量應用。(來源於維基百科相片相片馬賽克)
這是最終得到的效果,如果你的圖片集不同,或者引數設定不同,效果也會有差別。
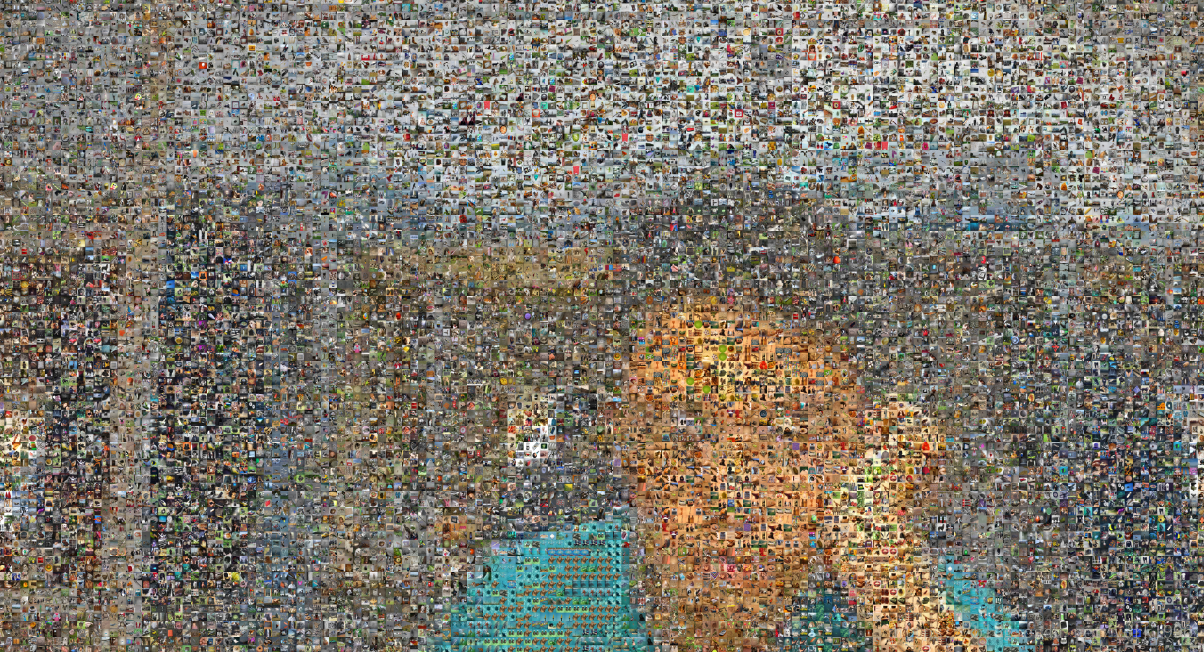
目錄
基本原理:
對於要繪製的圖的每一個畫素,都在影象集中找和這個畫素RGB值最接近的影象,然後放在這個位置。
下面是我的實現整個工程的步驟:
1,收集圖片素材
要做出上述的效果來,首先就需要大量的圖片,圖片少了,效果肯定不好,容易重複,需要的畫素值找不到相近的等等弊端。人工收集圖片的話肯定是非常慢的,如果要手工下載圖片,那至少要找圖片找很多天了。這個時候一般有兩個解決途徑:
- 爬取圖片
用網路爬蟲從別的網站上爬取圖片是個不錯的選擇,也可以用python來實現。
- 下載圖片資料集
網路上有別人已經整理好的影象資料集,我使用的是斯坦福大學李飛飛製作的ImageNet資料集。這個資料集是計算機視覺領域常用的一種資料集,它的訓練集大概有100多個G,測試集有10多個G,只是測試集就有10萬張圖片,夠本工程使用了。所以我下載的是他的測試集。網速快的話可以十來分鐘就下載下來。
2,圖片預處理
由於每張圖片的大小不一致,拼圖的時候不好處理,所以首先用OpenCV讀取每個圖片,再把它們的大小都改為100*100。一次更改,使用多次。程式碼如下:
#coding=utf-8 import os#和檔案有關的模組 import cv2#OpenCV #這裡是10萬張圖片所在的資料夾,你可以按照你的路徑改下面的程式碼。另外路徑好像不支援中文字元。 readPath=r"f:\ILSVRC2012_img_test" #這裡是改變大小之後的圖片,要儲存的路徑。save是一個資料夾 savePath=r"f:\save" #用一個列表儲存所有的圖片的檔名字 files=os.listdir(readPath) #n變數用來看到10萬張圖片的處理進度。 n=0 #遍歷所有圖片檔案們 for file in files: n+=1 imgPath=readPath+ "\\" + file#構造圖片路徑 img=cv2.imread(imgPath)#讀取圖片到記憶體img變數 img=cv2.resize(img,(100,100))#更改圖片的大小 # 更改之後寫入檔案,方便以後使用。否則你生成一張馬賽克就要處理一次10萬張圖片 cv2.imwrite(savePath+ "\\"+file,img) print(n) cv2.waitKey()
3,建立索引
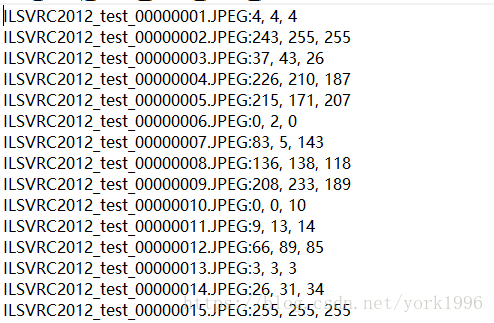
建立索引就是儲存每張圖片出現次數最多的畫素值然後儲存到檔案中。格式為:
檔名稱:B,G,R
建立好索引檔案之後,就可以知道每個圖片和他們最常見的顏色。在使用這些圖片的時候,就可以讀取整個索引檔案,然後定位到圖片檔案本身。試想一下,如果沒有這些索引檔案,那麼生成一次馬賽克拼圖就要求一次所有圖片的最多畫素,太多冗餘了。下面是程式碼:
import cv2
import os
import collections
readPath=r"f:\save"
files=os.listdir(readPath)
n=0
s=''
for file in files :
li=[]
n+=1
imgPath = readPath + "\\" + file
img=cv2.imread(imgPath)
for i in range(100):
for j in range(100):
b=img[i,j,0]
g=img[i,j,1]
r=img[i,j,2]
li.append((b,g,r))
most=collections.Counter(li).most_common(1)
s += file
s += ":"
s += str(most[0][0]).replace("(","").replace(")","")
s += "\n"
print(n)
f = open('filename.txt','w')
f.write(s)
生成的索引檔案格式是這樣的:
4,畫圖
首先是讀取步驟3生成的索引檔案。然後可以選擇打亂它,以免一樣的圖片聚集出現在一個位置附近。
假設目標圖片是n*m的,那麼新建一個n*100,m*100的圖片(這裡是100的整數倍是因為剛才把圖片集中的每個圖片都更改為100*100大小的了)。這是一個很大的圖片。對於原圖片的每個畫素,都遍歷索引檔案,找到和BGR畫素值的歐式距離(你也可以採取其他度量方式,甚至可以找最相近的圖片,但這樣將導致同圖片的聚集,因為相鄰的畫素值很可能一樣的)不大於一個閾值的索引檔案中的值,然後根據找到的BGR定位到具體的檔案,由檔案再讀取圖片,把圖片放到大圖上的具體位置。下面是具體程式碼:
import cv2
import numpy as np
readPath=r"f:\save"
def readIndex():
fs = open("filename.txt","r")
n=0
dic=[]
for line in fs.readlines():
n+=1
temp=line.split(":")
file=temp[0]
bgr=temp[1].split(",")
b=int(bgr[0])
g=int(bgr[1])
r=int(bgr[2])
dic.append((file,(b,g,r)))
return dic
img=cv2.imread("york.jpg")
s=np.shape(img)
big= np.zeros((100*s[0], 100*s[1], 3), dtype=np.uint8)
list=readIndex()#讀取索引檔案到變數中
for i in range(s[0]):#遍歷行和列
for j in range(s[1]):
print(i)
b = img[i, j, 0]
g = img[i, j, 1]
r = img[i, j, 2]#獲取影象當前位置的BGR值
np.random.shuffle(list)#打亂索引檔案
for item in list:
imgb=item[1][0]
imgg=item[1][1]
imgr=item[1][2]#獲取索引檔案的RGB值
distance=(imgb-b)**2+(imgg-g)**2+(imgr-r)**2#歐式距離
if distance<100:
filepath=readPath+"\\"+str(item[0])#定位到具體的圖片檔案
break
little=cv2.imread(filepath)#讀取整個最相近的圖片
big[i*100:(i+1)*100,j*100:(j+1)*100]=little#把圖片畫到大圖的相應位置
cv2.imwrite("bigYork.jpg",big)#輸出大圖到檔案中
大功告成。
下面是我的時間統計:
- 下載圖片用了三個多小時
- 圖片預處理用了一個多小時
- 建立索引大概需要一個多小時
- 之後畫每個一萬個畫素點左右的圖片大概需要三分鐘的時間