
hadoop學習之路(一)---叢集環境搭建(2.7.3版本)
三:下載解壓 hadoop 到某個目錄(例如 /usr/loacl/hadoop)
四:賬號建立:
即為hadoop叢集專門設定一個使用者組及使用者,這部分比較簡單,參考示例如下:
groupadd hadoop //設定hadoop使用者組
useradd –s /bin/bash –d /home/hadoop –m hadoop –g hadoop –G admin
//新增一個hadoop 使用者,此使用者屬於hadoop使用者組,且具有admin許可權。
passwd xxxxx//設定使用者hadoop登入密碼
su hadoop //切換到hadoop
五:配置hosts
配置hosts檔案的作用:用於確定每個結點的IP地址,方便後續master結點能快速查到並訪問各個結點。
配置hosts需要確定每個結點的IP地址,可以使用ifconfig命令進行檢視當前虛機結點的IP地址,例如: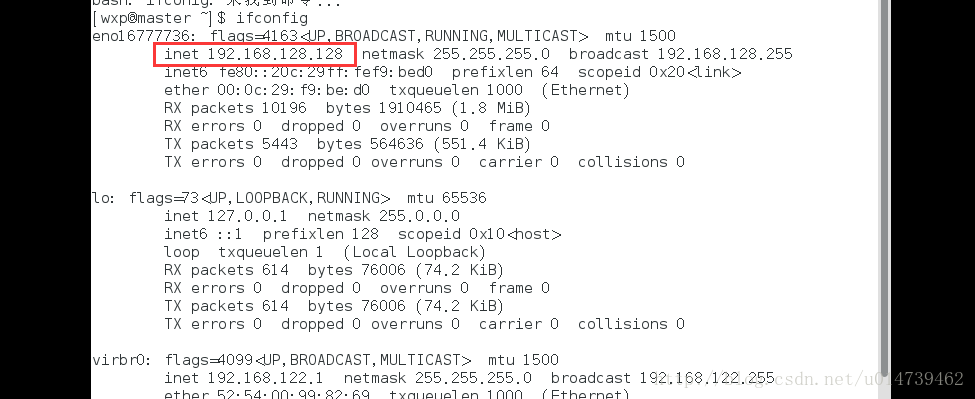
如果IP地址不對,可以通過ifconfig命令更改結點的物理IP地址:ifconfig eth1 1912.168.xxx.xxx
(這裡可以使用VMware吧虛擬機器的Ip設定死,這樣比較方便)
hosts配置示例:
192.168.128.128 master
192.168.128.132 study_node_1
192.168.128.130 study_node_2
六:修改環境變數以及hadoop的配置檔案了,即各種site檔案,檔案存放在/hadoop/etc下(這個不同版本的hadoop目錄好像不一樣,我這邊是2.7.3是在etc下)。
修改 /etc/profile
export HADOOP_HOME=/xxx/xxx/hadoop-2.7.3
export PATH=
source /etc/profile
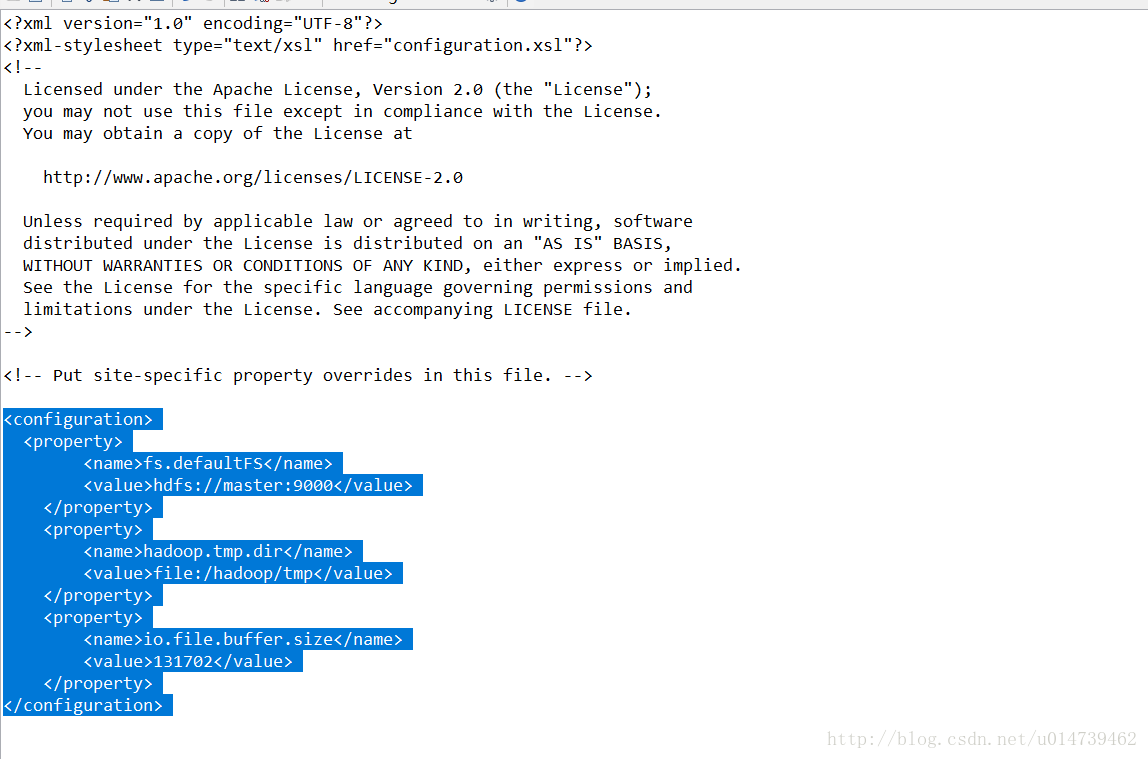
配置core-site.xml、hdfs-site.xml、mapred-site.xml這三個檔案。
core-site.xml:
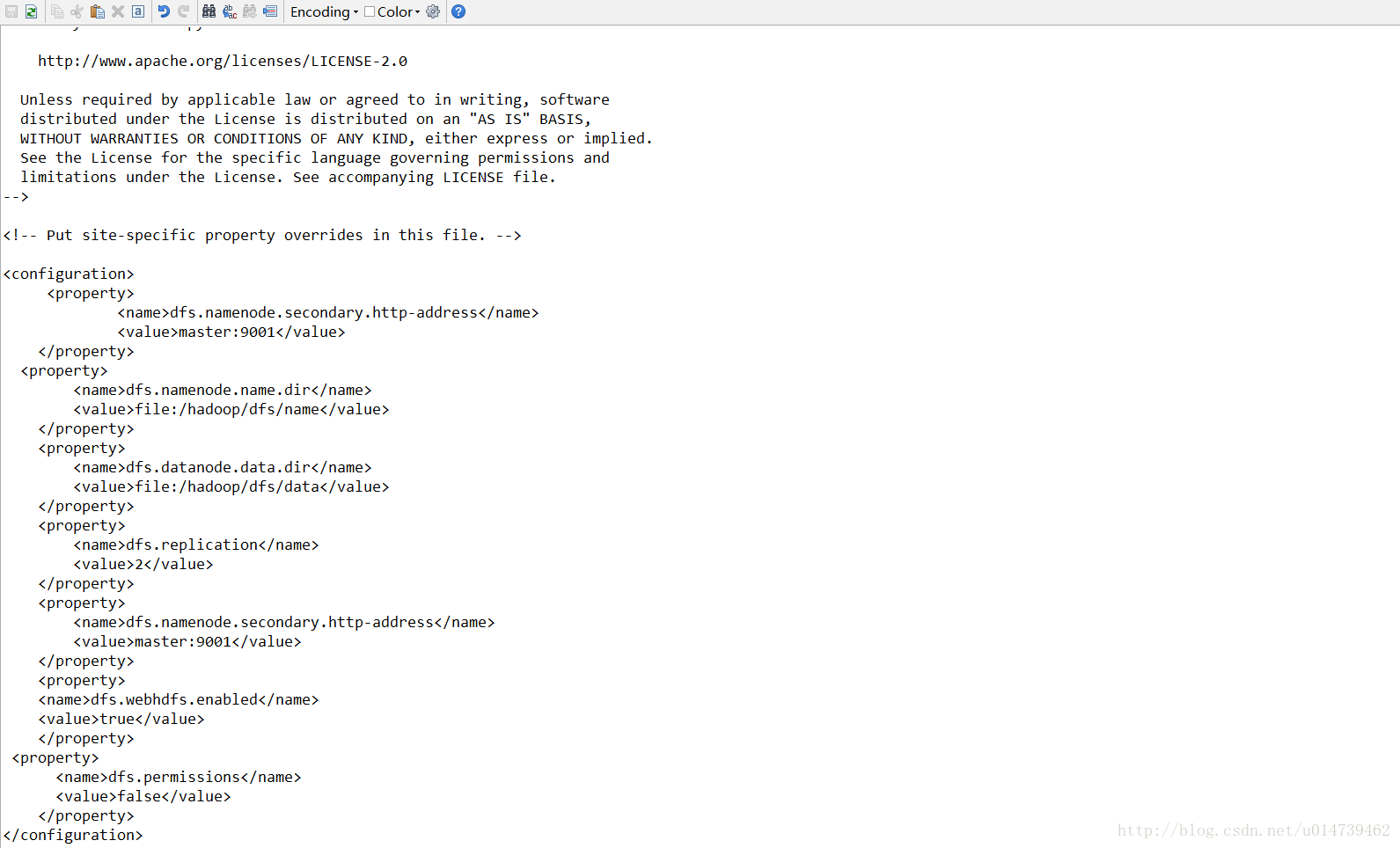
hdfs-site.xml:
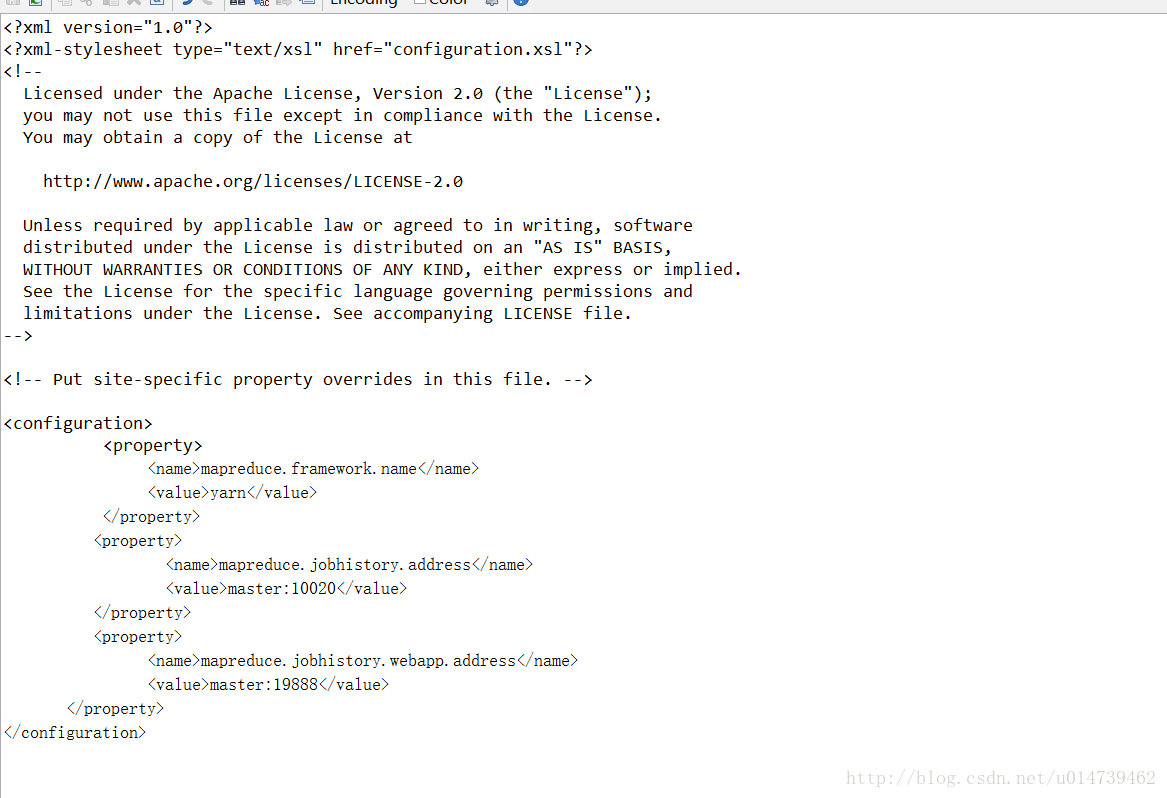
mapred-site.xml
更多配置參考相關文件或者文章
配置hadoop-env.sh檔案
這個需要根據實際情況來配置。
配置jdk目錄
export JAVA_HOME=/usr/java/jdk1.8.0_101
更多配置參考相關文件或者文章
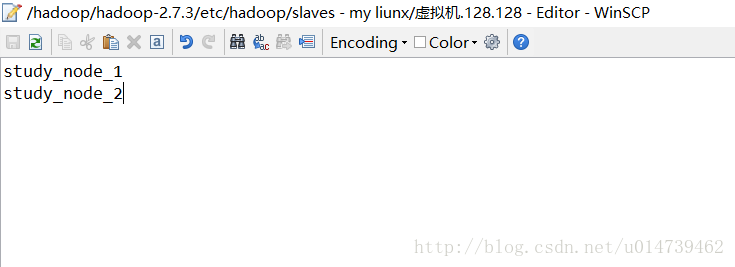
七:配置slaves檔案
八:啟動
第一次啟動得格式化
./bin/hdfs namenode -format
啟動dfs: ./sbin/start-dfs.sh
啟動yarn: ./sbin/start-yarn.sh
檢視:master

檢視 slave
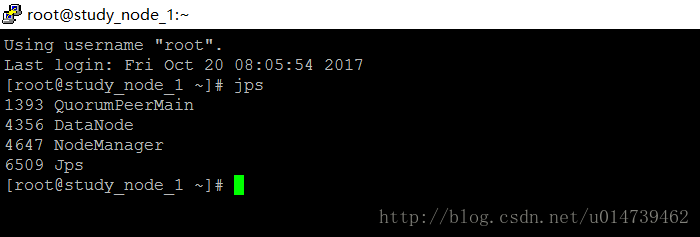
至此叢集環境搭建完成
10:開發環境搭建(idea,可以直接參考該文章:http://blog.csdn.net/uq_jin/article/details/52235121)
1:下載hadoop 解壓到本地目錄,並配置環境變數
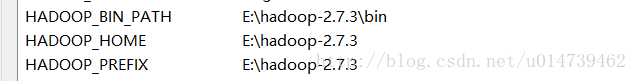
2:建立maven工程,加入hadoop原來
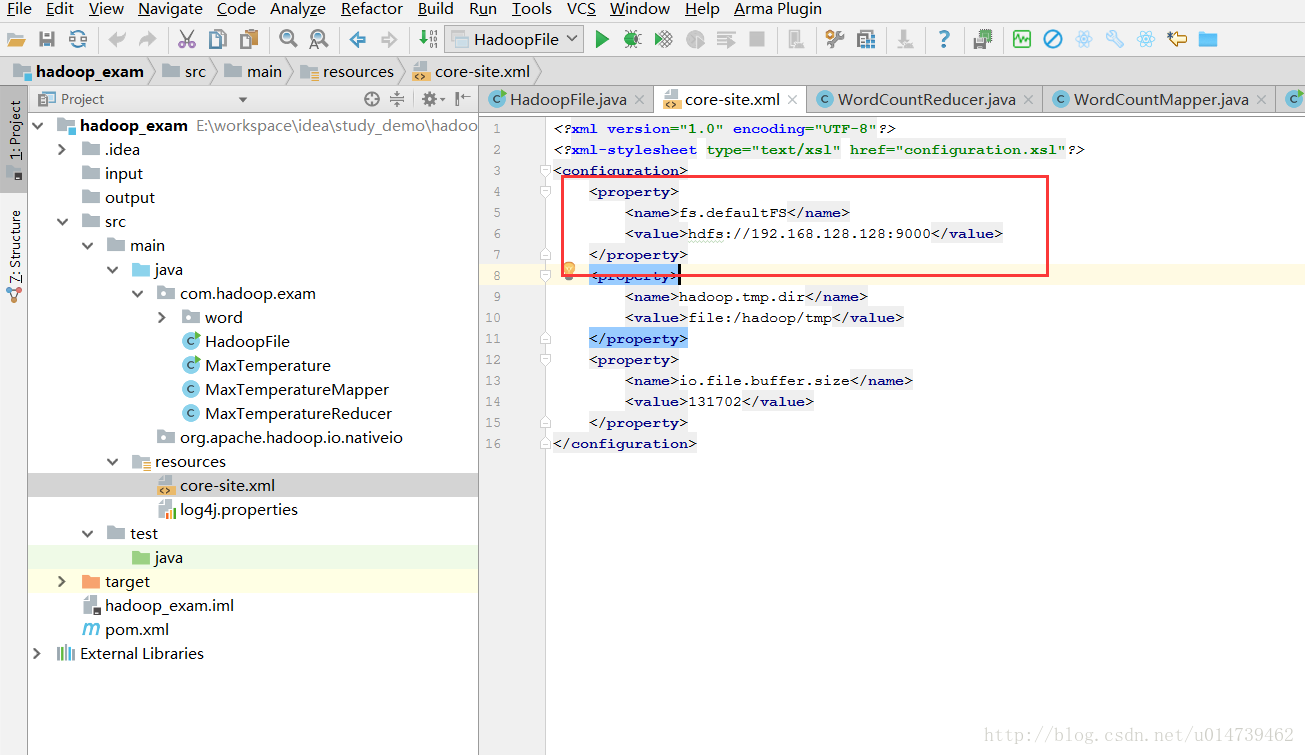
3:配置core-site.xml
備註:
1:如果使用克隆虛擬機器的方式生成slave節點,需要修改克隆機器名,編輯/etc/hostname,檔案內容改為剛才slaves檔案中配置的值。
2.在master上ssh連線slave1和slave2,測試免密碼登陸是否成功,執行
ssh study_node_1 (即主機名稱)
3.在master上啟動hadoop,執行
start-all.sh
注意事項:
1.hadoop使用者必須有/usr/local/hadoop資料夾讀寫許可權