
解決Python2的print中文在windows命令列亂碼問題
阿新 • • 發佈:2019-02-10
我們都知道如果想要在Python的程式碼中輸入中文,必須在import前加上# -*- coding: UTF-8 -*-,這樣我們就可以在程式碼中輸入中文了。當你用notepad++或者editplus寫程式碼時。在windows平臺下,如果輸出在命令列,經常會出現亂碼或者decode錯誤例如str='你好'print str這時通常會出現下圖這種情況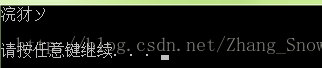
文字出現了亂碼,是什麼原因呢?你說那我這樣寫呢mes='你好'print u'%s' %(mes)你會發現如果是print u'你好' # 這樣寫沒問題但是上面的通常會出現下圖的情況
UnicodeDecodeError:ascii 編碼器不能解碼 位元組 0xe4 在位置0: 序號不在0到127裡為什麼呢?win+R,cmd回車開啟命令列,輸入chcp
936是我的window7中命令列的編碼解碼格式你可以修改預設的格式,通過首先輸入chcp 格式程式碼,然後在命令列窗體上右鍵
點選屬性
選中新出現的字型,確定就可以了。例如chcp 65001就是utf-8回到之前的話題,為什麼Python在命令列會輸出異常呢?首先我們分析以下輸出過程中編碼解碼的過程print str這裡str是字串引用,要想輸出對應的內容,先找到對應的值,它在記憶體裡面以位元組碼儲存,然後將值解碼成對應的字串,再編碼成你的命令列對應的格式的位元組(如gbk)bytes。然後命令列會將你的位元組碼根據命令列的格式轉化成字串顯示出來。注意:編碼成位元組格式可以省略,因為Python會自動完成找到你命令列解碼編碼格式,然後轉換成對應的位元組碼這個過程,使用的也是'ignore'。decode()用於將bytes解碼成指定格式字串,encode()將字串按指定格式編碼成bytes,encode()還有第二個引數它能幫助你解決那麼無法表達的字串,'ignore'用來拋棄任何不能被編碼的字串,'replace'用來用?代替那些字串。 
個過程,當你直接print u'你好'時,u會把'你好'編碼成uniocde對應的位元組再輸出,這時也就等價於print '你好'.decode('utf-8'),因此輸出正確。但是當你print u'%s' %(mes)時,Python的會將''裡的空字串轉變為unicode位元組,再用預設的ascii解碼器解碼mes的內容。mes='snow'print u'你好%s' %(mes)# 這樣可以正常執行也就是說u不能自動替變數解碼如果你一定要用u的話,可以使用下面的方法print u'你好%s' %(mes.decode('utf-8'))
文字出現了亂碼,是什麼原因呢?你說那我這樣寫呢mes='你好'print u'%s' %(mes)你會發現如果是print u'你好' # 這樣寫沒問題但是上面的通常會出現下圖的情況
UnicodeDecodeError:ascii 編碼器不能解碼 位元組 0xe4 在位置0: 序號不在0到127裡為什麼呢?win+R,cmd回車開啟命令列,輸入chcp
936是我的window7中命令列的編碼解碼格式你可以修改預設的格式,通過首先輸入chcp 格式程式碼,然後在命令列窗體上右鍵
點選屬性
選中新出現的字型,確定就可以了。例如chcp 65001就是utf-8回到之前的話題,為什麼Python在命令列會輸出異常呢?首先我們分析以下輸出過程中編碼解碼的過程print str這裡str是字串引用,要想輸出對應的內容,先找到對應的值,它在記憶體裡面以位元組碼儲存,然後將值解碼成對應的字串,再編碼成你的命令列對應的格式的位元組(如gbk)bytes。然後命令列會將你的位元組碼根據命令列的格式轉化成字串顯示出來。注意:編碼成位元組格式可以省略,因為Python會自動完成找到你命令列解碼編碼格式,然後轉換成對應的位元組碼這個過程,使用的也是'ignore'。decode()用於將bytes解碼成指定格式字串,encode()將字串按指定格式編碼成bytes,encode()還有第二個引數它能幫助你解決那麼無法表達的字串,'ignore'用來拋棄任何不能被編碼的字串,'replace'用來用?代替那些字串。
個過程,當你直接print u'你好'時,u會把'你好'編碼成uniocde對應的位元組再輸出,這時也就等價於print '你好'.decode('utf-8'),因此輸出正確。但是當你print u'%s' %(mes)時,Python的會將''裡的空字串轉變為unicode位元組,再用預設的ascii解碼器解碼mes的內容。mes='snow'print u'你好%s' %(mes)# 這樣可以正常執行也就是說u不能自動替變數解碼如果你一定要用u的話,可以使用下面的方法print u'你好%s' %(mes.decode('utf-8'))