
【推薦系統】基於內容的推薦系統和基於知識的推薦系統
1、基於內容的推薦系統
(1)基於內容的推薦演算法概述
基於內容的推薦演算法(Content-based Recommendations, CB)也是一種工業界應用比較廣的一種推薦演算法。由於協同過濾推薦演算法中僅僅基於使用者對於商品的評分進行推薦,所以有可能出現冷啟動的問題,如果可以根據物品的特性和使用者的特殊偏好等特徵屬性進行比較直觀的推薦就可以解決這個冷啟動的問題。
CB演算法雖然需要依賴物品和使用者偏好的額外資訊,但是不需要太多的使用者評分或者群體記錄,也就是說,就是隻有一個使用者也可以完成推薦功能,產生一個物品推薦列表。
CB演算法的初始設計的目標是推薦有意思的文字文件,現階段也會將該演算法應用到其它推薦領域中。
(2)基於內容的推薦演算法結構
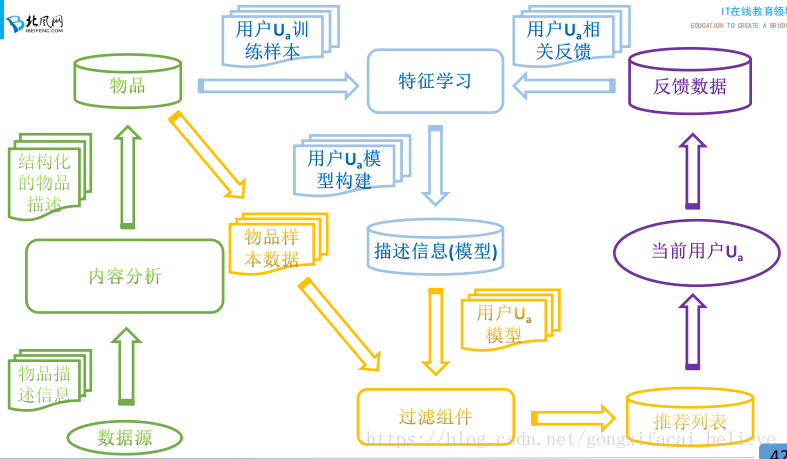
CB演算法主要包含三個步驟:
1. Item Representation: 為每一個item抽取一些特徵屬性出來,也就是結構化物品的描述操作,對應的處理過程叫做: Content Analyzer(內容分析);
2. Profile Learning:利用一個使用者過去喜歡(不喜歡)的item特徵資料,來學習該使用者的喜好特徵(profile);對應的處理過程叫做:Profile Learning(特徵學習);
3. Recommendation Generation:通過比較上一步得到的使用者profile於特徵item的特徵,為此使用者推薦一組相關性最大的item即可;對應的處理過程叫做:Filtering Component(過濾元件)。
1. CB-Item Representation
對於物品特徵屬性的抽取型別機器學習中採用的方式,主要包括對數值型資料的處理和對非數值型資料的處理,主要處理方式如下:
a. 數值型資料歸一化;
b. 數值型資料二值化;
c. 非數值型資料詞袋法轉換為特徵向量;
d. TF-IDF;
e. Word2Vec。
2. CB-Profile Learning
假設使用者u對於一些item已經給出了喜好判斷,喜歡其中的一部分item,不喜歡其中的另外一部分,那麼該過程就是通過使用者u過去的這些喜好判斷,構建一個判別模型,最後可以根據這個模型判斷使用者u對於一個新的item是否會喜好。所以說這是一個比較典型的有監督學習問題,理論上可以使用機器學習的分類演算法求解出所需要的判別模型。
常用的演算法有:
a. 最近鄰方法(K-Nearest Neighbor, KNN);
b. 決策樹演算法(Decision Tree, DT);
c. 線下分類演算法(Linear Classifer, LC);
d. 樸素貝葉斯演算法(Naive Bayes, NB)。
(3)CB和CF的區別
CB(基於內容的推薦演算法)的推薦系統會試圖推薦給給定使用者過去喜歡的相似物品。CB不需要使用者-物品評分矩陣。
CF(協同過濾的推薦演算法)的推薦系統會試圖識別出具有相同愛好的使用者,並推薦他們喜歡過的物品。CF演算法是基於使用者-物品評分矩陣來進行推薦的。
(4)演算法流程
(5)CB演算法的優缺點
1. 優點:
使用者獨立性: 在構建模型的過程中,僅僅只需要考慮當前使用者資訊即可;
透明度:通過顯示地列出使得物品出現在推薦列表中的內容特徵或者描述,可以比較明確的解釋推薦系統是如何工作的;
新物品:在沒有任何評分的情況下,也可以進行推薦。
2. 缺點:
可分析的內容有限/特徵抽取比較難:與推薦物件相關的特徵數量和型別上是有限制的,而且依賴於領域知識;
無法發現使用者的潛在興趣/過度特化:由於CB中的推薦結果是和該使用者以前喜歡的item類似的,所以如果一個使用者在一個網站僅僅只對一個item表達出喜歡的情緒,那麼推薦系統也就無法發現這個人可能還喜歡其它物品;
無法為新使用者產生推薦:由於CB演算法需要依賴使用者的歷史資料,那麼對於新使用者而已就有可能無法產生一個比較可靠的推薦。
2、基於知識的推薦系統
(1)基於知識的推薦系統概述
傳統的推薦演算法(CB和CF)適用於推薦特性或者口味相似的物品,比如:書籍、電影或者新聞。但是在對某些產品進行推薦的過程中,就有可能不是特別適合的方法,比如汽車、電腦、房屋、或者理財產品等等。主要是兩個原因:很難在一個產品上獲取大量的使用者評分資訊以及獲得推薦的使用者不會對這些已經過時的產品產生一個滿意的回饋。
基於知識的推薦技術(Knowledge-based Recommendations, KB)是專門解決這類問題的一種新的推薦技術,高度重視知識源,不會存在冷啟動的問題,因為推薦的需求都是被直接引出的。缺點是:所謂的知識的獲取比較難,需要知識整理工程師將領域專家的知識整理成為規範的、可用的表達形式。
基於知識的推薦技術需要主動的詢問使用者的需求,然後返回推薦結果。
(2)會話式推薦系統互動形式
一般的互動過程如下:
a. 使用者指定自己的最初偏好,然後一次性問完所有問題,或者逐步問完問題;
b. 當收集到足夠多有關使用者需求和偏好的資訊後,會提供給使用者一組匹配產品;
c. 使用者可能會修改自己的需求;
d. 類似於搜尋過程,只是將搜尋過程中給定的引數輸入到基於知識的推薦系統中。
系統開發中需要考慮的問題:
a. 需要一些比較高精度的推薦結果;
b. 當沒有完全匹配物品的時候,需要給定解決方案,比如主動提供某些的候選結果。
(3)KB的分類
基於知識的推薦系統分為兩大類:基於樣列的推薦和基於約束的推薦;這兩種方法非常相似:先收集使用者需求,在找不到推薦方案的情況下,自動修復與需求的不一致性,並給出推薦的解釋。區別在於:推薦方案是如何被計算出來的。
1. 基於樣列的推薦方法通過相似度衡量標準從目錄中檢索物品。
2. 基於約束的推薦方式主要是利用預先定義好的推薦知識庫,即一些描述使用者需求以及與這些需求相關的產品資訊特徵的顯示關聯規則;也就是使用約束求解器解決的約束滿足問題或者通過資料庫引擎執行並解決的合取查詢形式。
基於知識的推薦系統一般情況下需要依賴物品特徵的詳細知識;簡單來講,推薦就是從物品特徵數量表中挑出能夠匹配使用者需求、偏好和硬體需求的物品;使用者的需求可能會表達成為:價格不超過在2200元的物品或者能夠防水等等
3、基於約束的推薦技術
(1)基本概念
基於約束的推薦技術可以使用一組(V,D,C)來描述,其中:
1. V:是一組變數集合,主要是:Vc和VPROD;
2. D:是一組這些變數的有限域;
3. C:是一組約束條件,描述了這些變數能夠同時滿足的取值的組合條件;主要是CR、CF、CPROD;
實際上基於約束的推薦技術就是在約束(V=Vc U VPROD, D, C = CR U CF U CPROD)情況下,給定一個需求REQ,給出一個最終的RES推薦結果。
使用者屬性(Vc):描述了客戶的潛在需求,即使用者需求的特徵屬性例項化。比如:max-price表示使用者能夠接受的最高價格。
4. 產品屬性(VPROD):描述了一個給定產品種類的特徵屬性,比如mpix表示解析度。一致性約束條件(CR):定義了允許範圍內的使用者例項物件,也就是對客戶需求可能的例項化的系統約束,比如:如果要去相機能夠大於大尺寸的照片,則最大可接受價格必須高於1500。
5. 過濾條件(CF):定義了在那種條件下應該選擇的哪種產品,也就是定義了使用者屬性和產品屬性之間的關係,比如:大尺寸照片列印功能要求相機的解析度至少大於5mpix。
6. 產品約束條件(CPROD):定義了當前有效的產品分類。
(2)預設值設定
預設值設定的主要目的是幫助使用者說明需求的一種方式,當用戶給定一個比較模糊、泛化的需求的時候,系統可以對該屬性指標進行解析轉換,得到更加豐富的需求條件列表。比如:當一個使用者需要的是一個可以列印大尺寸照片的時候,我們可以預設認為他需要的相機的畫素必須大於3兆;給定預設的方式如下:
1. 靜態預設設定:每一個屬性都具有一個預設值
2. 條件預設設定:根據使用者給定的需求條件,生產一個預設值
3. 派生預設設定:利用以前所有使用者的互動日誌和當前使用者給定的引數,進行分析建模,得到每一個屬性的預設值。最常用的方法為:1最近鄰和加權多數投票。
(3)處理空結果集
實際上,當用戶給定的需求太多的時候,就有可能產生沒有任何一個物品是符合給定需求的,也就會產生一個空推薦結果集,基本上所有的推薦系統都不能完全解決這種“無米之炊”的難題,常用的一種解決方案是:
給定使用者需求特徵屬性的優先級別,按照屬性的優先級別刪除原始需求中的需求,得到一個新的需求條件列表,重新獲取推薦資料,直到有結果產生。
(4)推薦結果排序
基於首位效應,使用者會更多的關注並選擇列表開頭的物品,並且這種根據物品對使用者的效用進行結果排序的方式會顯著提高推薦應用的信任度和使用者購買意願。
物品排序的根據是多屬性效用理論,也就是依據每個物品對使用者的效用來評價。每個物品會根據事先定義好的維度來進行評價,比如相機主要考慮的就是:質量和經濟實惠;金融領域可能主要考慮的就是:有效性、風險和利潤。結合使用者對各個維度的偏好數值(百分比),來計算出最終的對於這個商品的偏好程度。

4、基於樣列的推薦技術
基於樣列的推薦技術中主要問題就是求解使用者需求和物品之間的距離,也就是物品和需求之間的相似度。一種常用的計算相似度的公式如下:
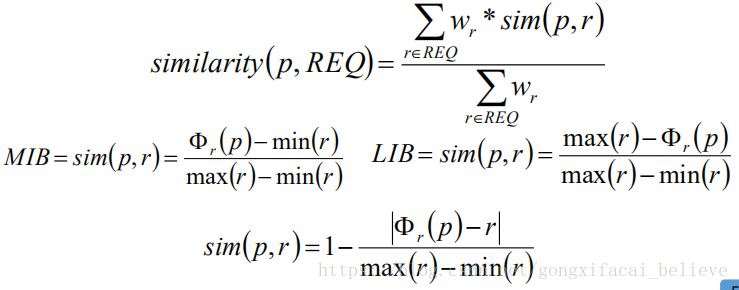
5、基於知識的推薦系統總結
基於知識的推薦系統在協同過濾或者基於內容的推薦技術有明顯缺點的時候十分有用,並且能夠很好的應用到大型的推薦系統中,但是基於知識的推薦系統還是存在著一系列的問題:
基於約束的推薦技術構建約束條件需要比較多的一個領域知識,比較難。
基於樣列的推進技術當計算物品和需求之間相似度公式效果不佳的時候,推薦的結構比較不好,而且結構化物品特徵數量以及構建特徵屬性和需求之間的相似度計算規則比較難,需要比較高的一個領域知識。
未來是一個發展方向,但是在當前推薦領域中實際應用的不多。
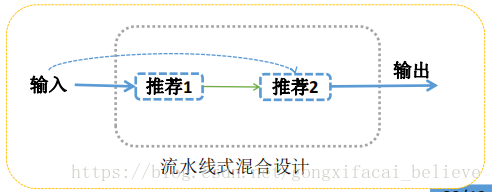
6、混合推薦系統
我們可以把推薦系統看成一個黑盒子,可以將輸入的資料轉換成為一個有序的物品列表再進行輸出,輸入的資料主要包含使用者記錄、上下文資訊、產品特徵、知識模型等等,但是沒有任何一個推薦演算法可以利用到這所有的輸入資料,所以可以考慮將多個推薦系統模型的結果混合到一起來作為最終的推薦結果。
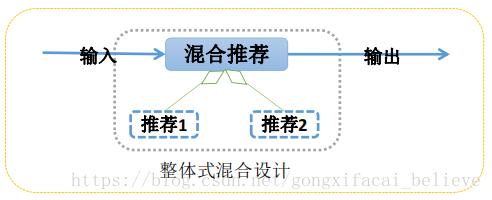
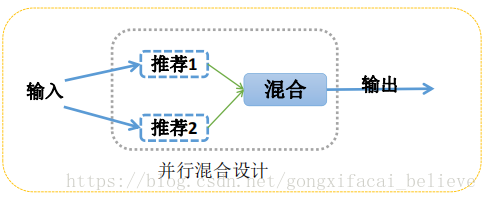
混合推薦系統的設計結構主要分為三大類,分別是:整體式混合設計、並行式混
合設計、流水線式混合設計。
7、推薦系統攻擊
在實際應用中,由於推薦系統的建議可能會影響使用者的購買行為,帶來經濟效益的時候,我們並不能假設所有的使用者都是誠實公平的,也就是說存在的惡意使用者有可能會影響推薦系統的執行效果,讓推薦列表經常(或者很少)包含某類商品,這種問題就叫做推薦系統攻擊。
解決方案:
1. 儘可能的提高“可信”朋友的評分權重;
2. 過濾異常資料,因為只有大量異常資料的存在才有可能對最終結果產生不好的影響,那麼只需要過濾這部分的異常資料就可以解決這個問題。