
anyproxy批量自動採集微信公眾號文章
本篇文章將持續更新,你所看到的內容將保證在看到的時間是可用的。
首先我們來看一個微信公眾號歷史訊息頁面的連結地址:
http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=MjM5MzczNjY2NA==#wechat_webview_type=1&wechat_redirect
=========2017年1月11日更新=========
現在根據不同的微信個人號,會出現兩種不同的歷史訊息頁面地址,下面是另一種歷史訊息頁的地址,第一種地址的連結會在anyproxy中顯示302跳轉:
https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzA3NDk5MjYzNg==&scene=124#wechat_redirect
第一種連結地址的頁面樣式:
第二種連結地址的頁面樣式:
 第二種連結地址的頁面樣式:
第二種連結地址的頁面樣式:根據目前掌握的資訊,兩種頁面形式無規律的出現在不同的微訊號中,有的微訊號始終是第一種頁面形式,有的就始終是第二種頁面形式。
 根據目前掌握的資訊,兩種頁面形式無規律的出現在不同的微訊號中,有的微訊號始終是第一種頁面形式,有的就始終是第二種頁面形式。
根據目前掌握的資訊,兩種頁面形式無規律的出現在不同的微訊號中,有的微訊號始終是第一種頁面形式,有的就始終是第二種頁面形式。
上面這個連結是一個微信公眾號歷史訊息頁面的真實連結,但是我們把這個連結輸入到瀏覽器中會顯示:請從微信客戶端訪問。這是因為實際上這個連結地址還需要幾個引數才能正常顯示內容。下面我們就來看看可以正常顯示內容的完整連結是什麼樣的:
//第一種連結
http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=MjM5NTM1NjczMw==&uin=NzM4MTk1ODgx&key=a226a081696afed0d9dfa0972fa431e116e5c4572ce52343178ad4e9a2b94aeaad6ac4dd87de3e56f72209a73a32e9cc2052f68aca4884e36cf726e99f2671630c741d8e4c29abe4a049d1a71eeb2be5&devicetype=android-17&version=2605033c&lang=zh_CN&nettype=WIFI&ascene=1&pass_ticket=zbA7PswOPKySRpyEYI5kDCjRiljxcpzdbTuVMauFGemgdp8R1DY1uQY49srehWab&wx_header=1 這個地址是通過微信客戶端開啟歷史訊息頁面之後,再使用後面介紹的代理伺服器軟體獲取到的。這裡面有幾個引數:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
其中重要的引數是:__biz;uin=;key=;pass_ticket=;這4個引數。
__biz是公眾號的一個類似id的引數,每個公眾號擁有一個微信的biz,目前極小概率會發生公眾號的biz會變化的事件;
剩下的3個引數是有關使用者的id和令牌票據之類的意思,這3個引數的值是通過微信的客戶端生成後自動補充到位址列中的。所以我們想採集公眾號就必須通過一個微信客戶端app。在以前的微信版本中這3個引數還可以獲取一次之後在有效期之內多個公眾號通用。現在的版本已經是每次訪問一個公眾號都會更換引數值。
我現在所使用的方法只需要關注__biz這個引數就可以了。
我的採集系統由以下幾部分組成:1、一個微信客戶端:可以是一臺手機安裝了微信的app,或者是用電腦中的安卓模擬器。經過實測ios的微信客戶端在批量採集過程中崩潰率高於安卓系統。為了降低成本,我使用的是安卓模擬器。

2、一個微信個人號:為了採集內容不僅需要微信客戶端,還要有一個微信個人號專門用於採集,因為這個微訊號就幹不了其它事情了。
3、本地代理伺服器系統:目前使用的方法是通過Anyproxy代理伺服器將公眾號歷史訊息頁面中的文章列表傳送到自己的伺服器上。具體安裝設定方法在後面詳細介紹。
4、文章列表分析與入庫系統:我用的是php語言編寫的,後文將詳細介紹如何分析文章列表和建立採集佇列實現批量採集內容。
步驟
一、安裝模擬器或使用手機安裝微信客戶端app,申請微信個人號並登入到app上面。這一點就不過多介紹了,大家都會。
二、代理伺服器系統安裝
目前我使用的是Anyproxy,AnyProxy 。這個軟體的特點是可以獲取到https連結的內容。在2016年年初的時候微信公眾號和微信文章開始使用https連結。並且Anyproxy可以通過修改rule配置實現向公眾號的頁面中插入指令碼程式碼。下面開始介紹安裝與配置過程。
2、在命令列或者終端執行 npm install -g anyproxy,mac系統需要加上sudo;
3、生成RootCA,https需要這個證書:執行命令sudo anyproxy --root(windows可能不需要sudo);
4、啟動anyproxy執行命令:sudo anyproxy -i;引數-i是解析HTTPS的意思;
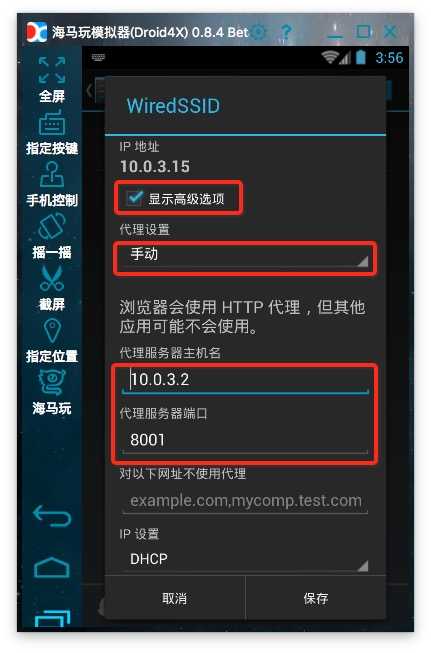
5、安裝證書,在手機或安卓模擬器中安裝證書:
6、設定代理:安卓模擬器的代理伺服器地址是wifi連結的閘道器,可以通過吧dhcp設定為靜態後看到閘道器地址,看完後別忘了再設定為自動。手機中的代理伺服器地址就是執行anyproxy的電腦的ip地址。代理伺服器預設埠是8001;
現在開啟微信,點選到任意一個公眾號歷史訊息或文章中,在終端都可以看到響應的程式碼滾動。如果沒有出現,請檢查手機的代理設定是否正確。
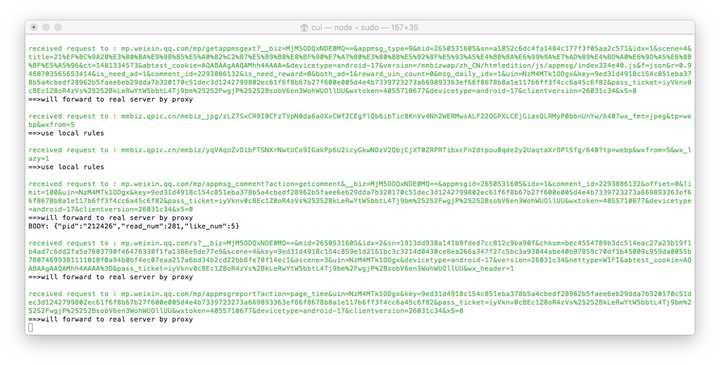
現在開啟瀏覽器地址http://localhost:8002 可以看到anyproxy的web介面。從微信中點開一個歷史訊息頁面,然後再看瀏覽器的web介面,會滾動出現歷史訊息頁面的地址。
以/mp/getmasssendmsg開頭的網址就是微信歷史訊息頁面。左邊一個小鎖頭表示這個頁面是https加密的。現在我們點選一下這一行;
 以/mp/getmasssendmsg開頭的網址就是微信歷史訊息頁面。左邊一個小鎖頭表示這個頁面是https加密的。現在我們點選一下這一行;
以/mp/getmasssendmsg開頭的網址就是微信歷史訊息頁面。左邊一個小鎖頭表示這個頁面是https加密的。現在我們點選一下這一行;
=========2017年1月11日更新=========
部分微訊號以/mp/getmasssendmsg開頭的網址會出現302跳轉,跳轉到了/mp/profile_ext?action=home開頭的地址。所以點開這個地址才可以看到內容。
右邊如果出現了html的檔案內容則表示解密成功。如果沒有內容,請檢查anyproxy的執行模式是否有引數i,是否生成了ca證書,手機是否正確安裝證書。
 右邊如果出現了html的檔案內容則表示解密成功。如果沒有內容,請檢查anyproxy的執行模式是否有引數i,是否生成了ca證書,手機是否正確安裝證書。
右邊如果出現了html的檔案內容則表示解密成功。如果沒有內容,請檢查anyproxy的執行模式是否有引數i,是否生成了ca證書,手機是否正確安裝證書。現在我們的手機中的所有內容都已經可以明文通過代理伺服器了。下面我們要修改配置代理伺服器,使公眾號內容被獲取到。
一、找到配置檔案:
mac系統中配置檔案的位置在/usr/local/lib/node_modules/anyproxy/lib/;windows系統請原諒我暫時不知道。應該可以根據類似mac的資料夾地址找到這個目錄。
二、修改檔案rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函式
修改函式內容(請注意詳細閱讀註釋,這裡只是介紹原理,理解後根據自己的條件修改內容):
=========2017年1月11日更新=========
因為出現了兩種頁面形式,且在不同的微訊號中始終顯示同一種頁面形式,但為了能相容兩種頁面形式,以下的程式碼會保留兩種頁面形式的判斷,你也可以根據自己的頁面形式去掉li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//當連結地址為公眾號歷史訊息頁面時(第一種頁面形式)
if(serverResData.toString() !== ""){
try {//防止報錯退出程式
var reg = /msgList = (.*?);/;//定義歷史訊息正則匹配規則
var ret = reg.exec(serverResData.toString());//轉換變數為string
HttpPost(ret[1],req.url,"getMsgJson.php");//這個函式是後文定義的,將匹配到的歷史訊息json傳送到自己的伺服器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//這個地址是自己伺服器上的一個程式,目的是為了獲取到下一個連結地址,將地址放在一個js指令碼中,將頁面自動跳轉到下一頁。後文將介紹getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//將返回的程式碼插入到歷史訊息頁面中,並返回顯示出來
})
});
}catch(e){//如果上面的正則沒有匹配到,那麼這個頁面內容可能是公眾號歷史訊息頁面向下翻動的第二頁,因為歷史訊息第一頁是html格式的,第二頁就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//這個函式和上面的一樣是後文定義的,將第二頁歷史訊息的json傳送到自己的伺服器
}
}catch(e){
console.log(e);//錯誤捕捉
}
callback(serverResData);//直接返回第二頁json內容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//當連結地址為公眾號歷史訊息頁面時(第二種頁面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定義歷史訊息正則匹配規則(和第一種頁面形式的正則不同)
var ret = reg.exec(serverResData.toString());//轉換變數為string
HttpPost(ret[1],req.url,"getMsgJson.php");//這個函式是後文定義的,將匹配到的歷史訊息json傳送到自己的伺服器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//這個地址是自己伺服器上的一個程式,目的是為了獲取到下一個連結地址,將地址放在一個js指令碼中,將頁面自動跳轉到下一頁。後文將介紹getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//將返回的程式碼插入到歷史訊息頁面中,並返回顯示出來
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二種頁面表現形式的向下翻頁後的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//這個函式和上面的一樣是後文定義的,將第二頁歷史訊息的json傳送到自己的伺服器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//當連結地址為公眾號文章閱讀量和點贊量時
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函式是後文定義的,功能是將文章閱讀量點贊量的json傳送到伺服器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//當連結地址為公眾號文章時(rumor這個地址是公眾號文章被闢謠了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//這個地址是自己伺服器上的另一個程式,目的是為了獲取到下一個連結地址,將地址放在一個js指令碼中,將頁面自動跳轉到下一頁。後文將介紹getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面這段程式碼是利用anyproxy可以修改返回頁面內容的功能,向頁面注入指令碼,和將頁面內容傳送到伺服器上。使用這個原理來批量採集公眾號內容和閱讀量。這段指令碼中自定義了一個函式,下面詳細介紹:
在rule_default.js檔案末尾新增以下程式碼:
function HttpPost(str,url,path) {//將json傳送到伺服器,str為json內容,url為歷史訊息頁面地址,path是接收程式的路徑和檔名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意沒有http://,這是伺服器的域名。
port: 80,
path: path,//接收程式的路徑和檔名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
上面就是rule規則修改的主要部分,需要將json內容傳送到自己的伺服器,還要從伺服器獲取到下一頁的跳轉地址。這就涉及到了四個php檔案:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在詳細介紹這4個php檔案之前,為了提高採集系統性能和降低崩潰率,我們還可以進行一些修改:
安卓模擬器經常會訪問一些http://google.com的地址,這樣會導致anyproxy宕機,找到函式replaceRequestOption : function(req,option),修改函式內容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上就是針對anyproxy的rule檔案的修改配置,配置修改完成之後,重新啟動anyproxy。mac系統裡按control+c中斷程式,再輸入命令sudo anyproxy -i啟動;如果啟動報錯,可能是程式沒有退出乾淨,埠被佔用。這時輸入命令ps -a檢視佔用的pid,再輸入命令“kill -9 pid”這裡將pid替換成查詢到的pid號碼。殺死程序之後就可以啟動anyproxy了。還是那句話windows的命令請原諒我不太熟悉。
接下來詳細介紹伺服器上接收程式的設計原理:
(以下程式碼並不是直接可以用的,只是介紹原理,其中一部分需要根據自己的伺服器資料庫框架進行編寫)
1、getMsgJson.php:這個程式負責接收歷史訊息的json並解析後存入資料庫
<?
$str = $_POST['str'];
$url = $_POST['url'];//先獲取到兩個POST變數
//先針對url引數進行操作
parse_str(parse_url(htmlspecialchars_decode(urldecode($url)),PHP_URL_QUERY ),$query);//解析url地址
$biz = $query['__biz'];//得到公眾號的biz
//接下來進行以下操作
//從資料庫中查詢biz是否已經存在,如果不存在則插入,這代表著我們新添加了一個採集目標公眾號。
//再解析str變數
$json = json_decode($str,true);//首先進行json_decode
if(!$json){
$json = json_decode(htmlspecialchars_decode($str),true);//如果不成功,就增加一步htmlspecialchars_decode
}
foreach($json['list'] as $k=>$v){
$type = $v['comm_msg_info']['type'];
if($type==49){//type=49代表是圖文訊息
$content_url = str_replace("\\", "", htmlspecialchars_decode($v['app_msg_ext_info']['content_url']));//獲得圖文訊息的連結地址
$is_multi = $v['app_msg_ext_info']['is_multi'];//是否是多圖文訊息
$datetime = $v['comm_msg_info']['datetime'];//圖文訊息傳送時間
//在這裡將圖文訊息連結地址插入到採集佇列庫中(佇列庫將在後文介紹,主要目的是建立一個批量採集佇列,另一個程式將根據佇列安排下一個採集的公眾號或者文章內容)
//在這裡根據$content_url從資料庫中判斷一下是否重複
if('資料庫中不存在相同的$content_url') {
$fileid = $v['app_msg_ext_info']['fileid'];//一個微信給的id
$title = $v['app_msg_ext_info']['title'];//文章標題
$title_encode = urlencode(str_replace(" ", "", $title));//建議將標題進行編碼,這樣就可以儲存emoji特殊符號了
$digest = $v['app_msg_ext_info']['digest'];//文章摘要
$source_url = str_replace("\\", "", htmlspecialchars_decode($v['app_msg_ext_info']['source_url']));//閱讀原文的連結
$cover = str_replace("\\", "", htmlspecialchars_decode($v['app_msg_ext_info']['cover']));//封面圖片
$is_top = 1;//標記一下是頭條內容
//現在存入資料庫
echo "頭條標題:".$title.$lastId."\n";//這個echo可以顯示在anyproxy的終端裡
}
if($is_multi==1){//如果是多圖文訊息
foreach($v['app_msg_ext_info']['multi_app_msg_item_list'] as $kk=>$vv){//迴圈後面的圖文訊息
$content_url = str_replace("\\","",htmlspecialchars_decode($vv['content_url']));//圖文訊息連結地址
//這裡再次根據$content_url判斷一下資料庫中是否重複以免出錯
if('資料庫中不存在相同的$content_url'){
//在這裡將圖文訊息連結地址插入到採集佇列庫中(佇列庫將在後文介紹,主要目的是建立一個批量採集佇列,另一個程式將根據佇列安排下一個採集的公眾號或者文章內容)
$title = $vv['title'];//文章標題
$fileid = $vv['fileid'];//一個微信給的id
$title_encode = urlencode(str_replace(" ","",$title));//建議將標題進行編碼,這樣就可以儲存emoji特殊符號了
$digest = htmlspecialchars($vv['digest']);//文章摘要
$source_url = str_replace("\\","",htmlspecialchars_decode($vv['source_url']));//閱讀原文的連結
//$cover = getCover(str_replace("\\","",htmlspecialchars_decode($vv['cover'])));
$cover = str_replace("\\","",htmlspecialchars_decode($vv['cover']));//封面圖片
//現在存入資料庫
echo "標題:".$title.$lastId."\n";
}
}
}
}
}
?>
再次強調程式碼只是原理,其中一部分注視的程式碼要自己編寫。
2、getMsgExt.php獲取文章閱讀量和點贊量的程式
<?
$str = $_POST['str'];
$url = $_POST['url'];//先獲取到兩個POST變數
//先針對url引數進行操作
parse_str(parse_url(htmlspecialchars_decode(urldecode($url)),PHP_URL_QUERY ),$query);//解析url地址
$biz = $query['__biz'];//得到公眾號的biz
$sn = $query['sn'];
//再解析str變數
$json = json_decode($str,true);//進行json_decode
//$sql = "select * from `文章表` where `biz`='".$biz."' and `content_url` like '%".$sn."%'" limit 0,1;
//根據biz和sn找到對應的文章
$read_num = $json['appmsgstat']['read_num'];//閱讀量
$like_num = $json['appmsgstat']['like_num'];//點贊量
//在這裡同樣根據sn在採集隊列表中刪除對應的文章,代表這篇文章可以移出採集隊列了
//$sql = "delete from `隊列表` where `content_url` like '%".$sn."%'"
//然後將閱讀量和點贊量更新到文章表中。
exit(
相關推薦
anyproxy批量自動採集微信公眾號文章
我從2014年就開始做微信公眾號內容的批量採集,最開始的目的是為了做一個html5的垃圾內容網站。當時垃圾站採集到的微信公眾號的內容很容易在公眾號裡面傳播。當時批量採集特別好做,採集入口是公眾號的歷史訊息頁。這個入口到現在也是一樣,只不過越來越難採集了。採集的方式也更新換代
如何實現自動採集微信公眾號文章
微信公眾號運營最讓人頭疼的就是如何寫出好的文章。在這瞬息萬變又人才輩出的時代,各類微信公眾號如雨後春筍般湧現,如何讓自己的微信公眾號文章脫穎而出,真正抓住公眾眼球,獲得持久關注?優秀的微信公眾號都是相似的,平庸的微信公眾號各有各的平庸。喬老爺子說:“好的藝術家是抄襲,偉大的
如何採集微信公眾號文章|微信文章採集技巧
微信文章採集技巧用相關軟體就好了,推薦:痕夕軟體
推薦文章:微信營銷技巧:怎麼讓顧客主動找你
一、巧用二維碼
一般微信活動的分享,都會選擇通過連結、二維碼轉發來引流客戶,放大微信活動的營銷價值。除了微信朋友圈/微信群的轉發,還可以通過其他媒體平臺進行廣發“二維碼”,比如
Python快速搭建自動回覆微信公眾號
Python快速搭建自動回覆微信公眾號
在之前的一篇文章 Python利用 AIML 和 Tornado 搭建聊天機器人微信訂閱號 中用 aiml 實現了一個簡單的英文聊天機器人訂閱號。但是隻能處理英文訊息,現在用 圖靈機器人 來實現一箇中文的聊天機器人訂閱號。
這裡主要介紹如何
如何將微信公眾號文章同步匯入採集到WordPress網站中
現小蜜蜂公眾號文章助手已經上線,可以採集任意公眾號的歷史文章,支援點贊數、閱讀數、評論的採集,支援匯出PDF、Excel、HTML、TXT格式的匯出,支援關鍵詞的搜尋,可前往官網進行檢視
很多微信公眾號的作者(個人、組織、公司)不僅僅在微信公眾平臺上進行寫作,通常會在多
微信公眾號文章-閱讀點贊數-評論採集方案
微信公眾號文章採集來源無非就搜狗和微信自己的介面,網上資料工具五花八門。細心的人已經學到了套路,粗心的還在等待被套路。
先聊聊搜狗的方案。採公眾號文章第一個就是幹搜狗,入門者也是這麼玩的,GitHub上各種Demo很多都能直接使用。要求不高的繼續玩玩搜狗也能滿足需求,無
微信公眾號文章頁的分析與採集
前面的文章裡詳細介紹瞭如何通過公眾號歷史訊息頁面獲取到文章地址的列表,那麼得到列表之後下一步就是要將文章的內容採集到自己的資料庫中。最近又看了其它網站提供的一些公眾號文章的爬蟲,以前真沒關注過這些。觀察後發現目前還都是以傳統的網站採集器形式採集搜狗的微信搜尋。通過搜狗搜尋採
iframe顯示微信公眾號文章
origin replace dom節點 列表 charset string 請求 資料 domain 最近在做一個案例頁面,主要結構就是列表和內容,還有固定的頭部和底部(方便查看價格及購買),因為之前的案例詳情頁是很多的固定頁面,這樣不太方便維護,現在其他同事需要展示不同
python 多線程方法爬取微信公眾號文章
微信爬蟲 多線程爬蟲 本文在上一篇基礎上增加多線程處理(http://blog.51cto.com/superleedo/2124494 )執行思路:1,規劃好執行流程,建立兩個執行線程,一個控制線程2,線程1用於獲取url,並寫入urlqueue隊列3,線程2,通過線程1的url獲取文章內容,並保
微信PK10平臺開發與用python爬取微信公眾號文章
網址 谷歌瀏覽器 pytho google http 開發 微信 安裝python rom 本文通過微信提供微信PK10平臺開發[q-21528-76294] 網址diguaym.com
的公眾號文章調用接口,實現爬取公眾號文章的功能。註意事項 1.需要安裝python s
微信文章抓取:微信公眾號文章抓取常識之臨時連結、永久連結
未經允許請勿轉載
曾經嘗試過抓取微信文章的小夥伴,一定很熟悉搜狗微信。搜狗微信是騰訊官方提供的搜尋引擎,專門用來搜尋微信公眾號發表的文章(不包含服務號)。
對於想要獲取微信文章進行研究學習的小夥伴,首先探索的途徑通常是搜狗微信。那麼關於搜狗微信以及微信相關的抓取,需
Python 爬蟲爬取指定微信公眾號文章
該方法是依賴於urllib2庫來完成的,首先你需要安裝好你的python環境,然後安裝urllib2庫
程式的起始方法(返回值是公眾號文章列表):
def openUrl():
print("啟動爬蟲,開啟搜狗搜尋微信介面")
# 載入頁面
url
微信公眾號文章的閱讀量和點贊數獲取指南
本文主要介紹“微信公眾號文章閱讀點贊API”的呼叫方法,以及呼叫前的準備工作和呼叫過程中可能出現的問題。
自打微信推出閱讀和點贊這一指標以來,網際網路上如何獲取、監控文章閱讀點讚的方法就層出不窮但卻不易實現,接下來,一起看看“微信公眾號文章閱讀點贊API”的呼叫。
在API測試頁,點
設定weixin://dl/business/?ticket=xxx喚起跳轉微信公眾號文章mp.weixin.qq.com/s/xxx的方法
很多人問我最近,怎麼樣外部手機瀏覽器才能開啟微信跳轉到公眾號文章連結,比如:
https://mp.weixin.qq.com/s/COlBhig2NJO5IXpDiTBhDA ,這樣的連結又是如何生成的?檢視原始碼是通過
類似weixin://dl/business/?ticket=xxx這樣的地址實現
分享一個可以提高微信公眾號文章閱讀率的小工具!公眾號運營者必備哦!
這個工具叫“閱讀紅包”。
“閱讀紅包”是個什麼東西?
閱讀紅包可以理解為文章的彩蛋。
也就是,當你的粉絲閱讀完了你群發的文章,在文章末尾驚喜的發現了一個“領取紅包”的連結,該粉絲點選連結,即可按設定的中獎概率獲得一個微信紅包。
有什麼用處?
1. 給自己的粉
關於微信公眾號文章抓取
今天公司要我抓取微信公眾號文章,我百度了半天得到的方法有三種:
具體內容我就不復制了請去下面這個連結去看,寫的挺好
微信公眾號文章採集方案
在三者中我選擇了比較穩妥的第二種:對手機微信進行中間人攻擊
因為之前被封過小號,所以感覺解封微信太麻煩
而關於如何中間人攻擊請參考下面的連結
【Python爬蟲】爬取微信公眾號文章資訊準備工作
有一天發現我關注了好多微信公眾號,那時就想有沒有什麼辦法能夠將微信公眾號的文章弄下來,而且還想將一些文章的精彩評論一起搞下來。參考了一些文章,通過幾天的研究基本上實現了自己的要求,現在記錄一下自己的一些心得。
整個研究過程如下: 1.瞭解微信公眾號文章連結的組成,歷史文章API組成,單個文章
python爬蟲(17)爬出新高度_抓取微信公眾號文章(selenium+phantomjs)(上)
抓取微信公眾號的文章
一.思路分析
目前所知曉的能夠抓取的方法有:
1、微信APP中微信公眾號文章連結的直接抓取(http://mp.weixin.qq.com/s?__biz=MjM5MzU4ODk2MA==&mid=2735446906&idx=1&am
python爬蟲(17)爬出新高度_抓取微信公眾號文章(selenium+phantomjs)(下)(windows版本)
前兩天在linux 上面寫了一版爬取微信公眾號的文章
今天重新修改一下,讓它在windows上面也能執行
執行下面的程式碼需要安裝以下內容:
pip install pyquery
pip install requests
pip install selenium
微信公眾號文章連結引數
https://mp.weixin.qq.com/s?src=3×tamp=1496819538&ver=1&signature=2Ui56lfdJ7txnkcz0Y0tXtfKXX8Dnh2Thra4pQ*iyV8afGJ7Z8umw