
池化方法總結(Pooling)
在卷積神經網路中,我們經常會碰到池化操作,而池化層往往在卷積層後面,通過池化來降低卷積層輸出的特徵向量,同時改善結果(不易出現過擬合)。
為什麼可以通過降低維度呢?
因為影象具有一種“靜態性”的屬性,這也就意味著在一個影象區域有用的特徵極有可能在另一個區域同樣適用。因此,為了描述大的影象,一個很自然的想法就是對不同位置的特徵進行聚合統計,例如,人們可以計算影象一個區域上的某個特定特徵的平均值 (或最大值)來代表這個區域的特徵。[1]
1. 一般池化(General Pooling)
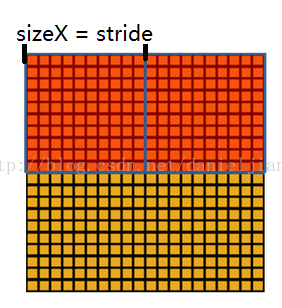
池化作用於影象中不重合的區域(這與卷積操作不同),過程如下圖。
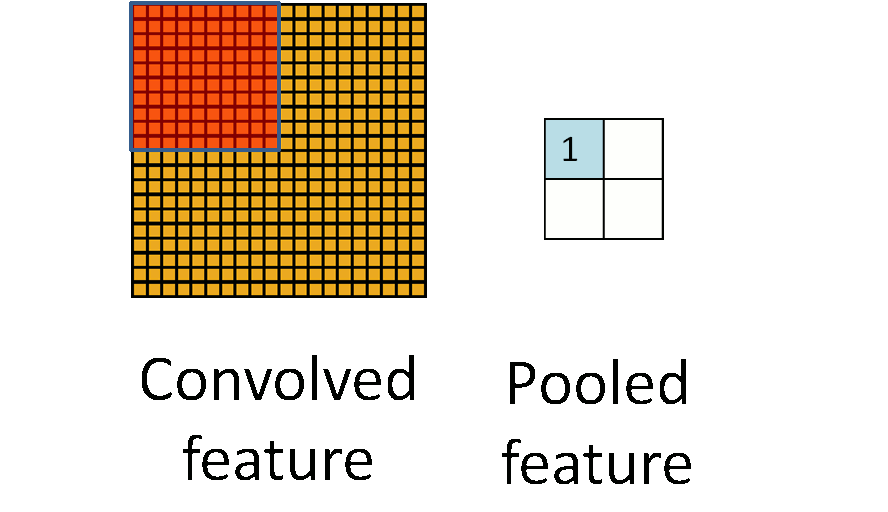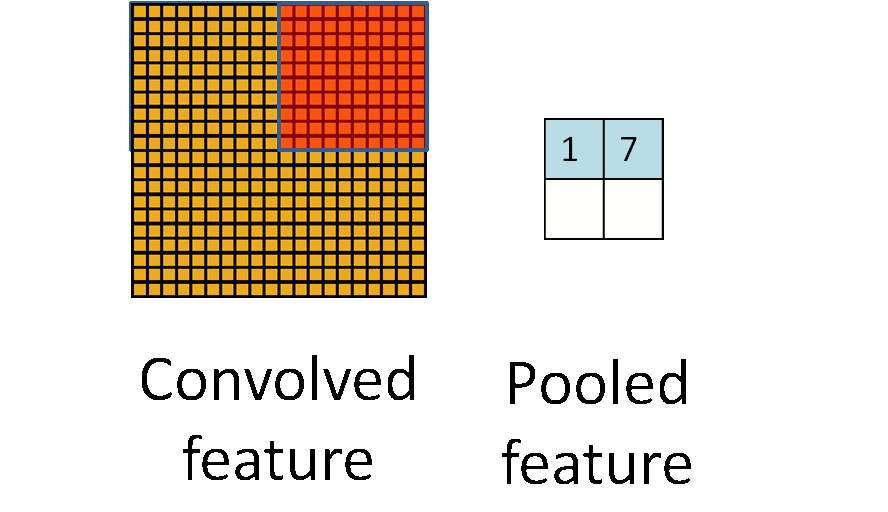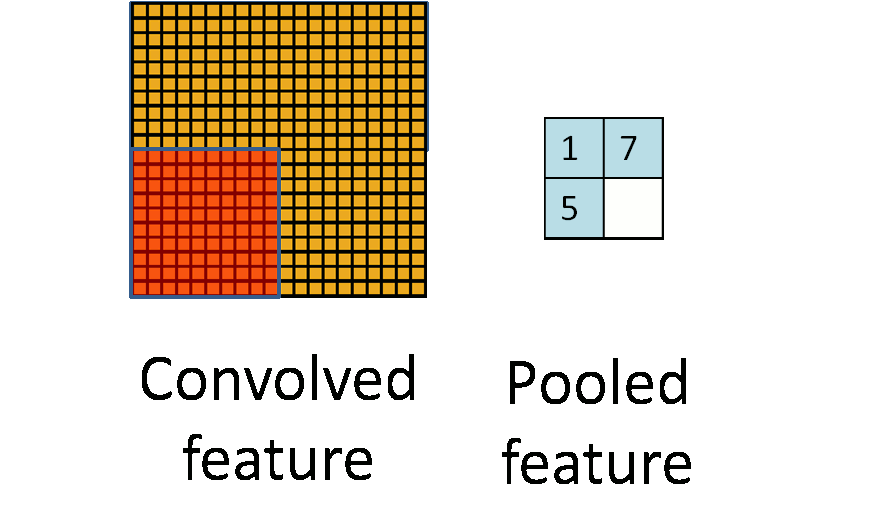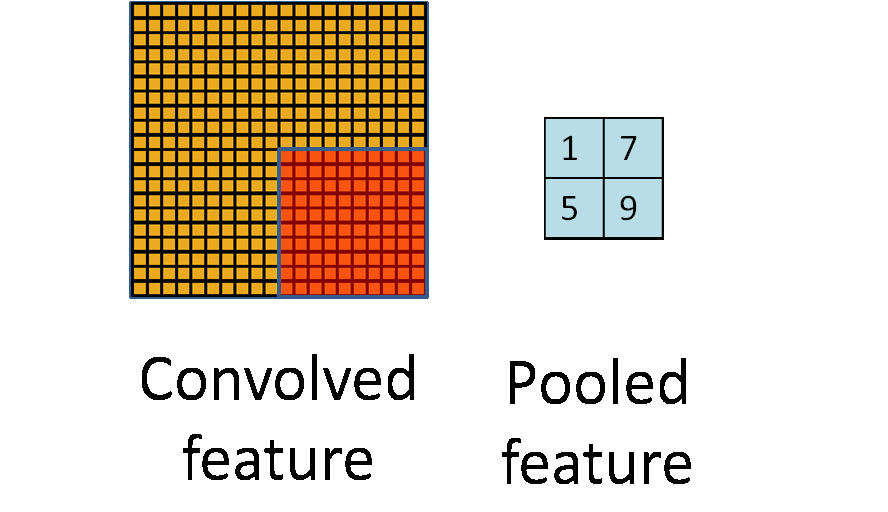
我們定義池化視窗的大小為sizeX,即下圖中紅色正方形的邊長,定義兩個相鄰池化視窗的水平位移/豎直位移為stride。一般池化由於每一池化視窗都是不重複的,所以sizeX=stride。
最常見的池化操作為平均池化mean pooling和最大池化max pooling:
平均池化:計算影象區域的平均值作為該區域池化後的值。
最大池化:選影象區域的最大值作為該區域池化後的值。
2. 重疊池化(OverlappingPooling)[2]
重疊池化正如其名字所說的,相鄰池化視窗之間會有重疊區域,此時sizeX>stride。論文中[2]中,作者使用了重疊池化,其他的設定都不變的情況下, top-1和top-5 的錯誤率分別減少了0.4% 和0.3%。
3. 空金字塔池化(Spatial Pyramid Pooling)[3]
空間金字塔池化可以把任何尺度的影象的卷積特徵轉化成相同維度,這不僅可以讓CNN處理任意尺度的影象,還能避免cropping和warping操作,導致一些資訊的丟失,具有非常重要的意義。
一般的CNN都需要輸入影象的大小是固定的,這是因為全連線層的輸入需要固定輸入維度,但在卷積操作是沒有對影象尺度有限制,所有作者提出了空間金字塔池化,先讓影象進行卷積操作,然後轉化成維度相同的特徵輸入到全連線層,這個可以把CNN擴充套件到任意大小的影象。

空間金字塔池化的思想來自於Spatial Pyramid Model,它一個pooling變成了多個scale的pooling。用不同大小池化視窗作用於卷積特徵,我們可以得到1X1,2X2,4X4的池化結果,由於conv5中共有256個過濾器,所以得到1個256維的特徵,4個256個特徵,以及16個256維的特徵,然後把這21個256維特徵連結起來輸入全連線層,通過這種方式把不同大小的影象轉化成相同維度的特徵。
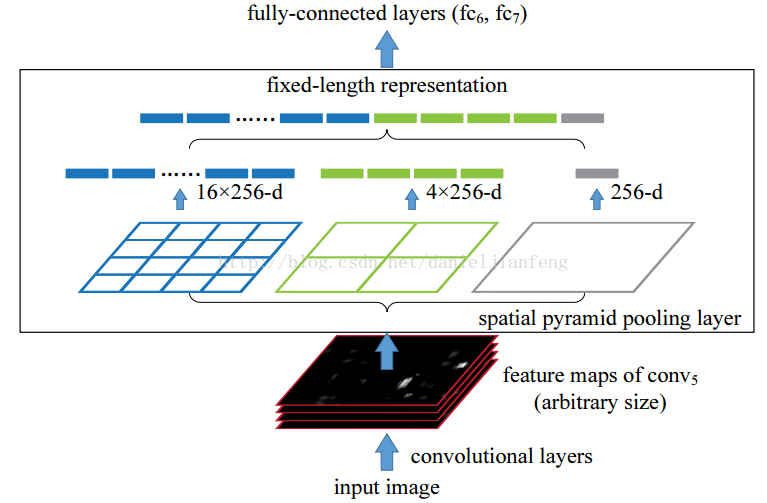
對於不同的影象要得到相同大小的pooling結果,就需要根據影象的大小動態的計算池化視窗的大小和步長。假設conv5輸出的大小為a*a,需要得到n*n大小的池化結果,可以讓視窗大小sizeX為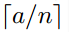
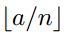

疑問:如果conv5輸出的大小為14*14,[pool1*1]的sizeX=stride=14,[pool2*2]的sizeX=stride=7,這些都沒有問題,但是,[pool4*4]的sizeX=5,stride=4,最後一列和最後一行特徵沒有被池化操作計算在內。
SPP其實就是一種多個scale的pooling,可以獲取影象中的多尺度資訊;在CNN中加入SPP後,可以讓CNN處理任意大小的輸入,這讓模型變得更加的flexible。
4. Reference
[2] Krizhevsky, I. Sutskever, andG. Hinton, “Imagenet classification with deep convolutional neural networks,”in NIPS,2012.
[3] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Su,Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition,LSVRC-2014 contest