
python解析json檔案
最近專案資料用的是json格式,學習了一下python解析json格式的方式,總結一下備忘。
文章參考連結:
http://liuzhijun.iteye.com/blog/1859857
http://www.cnblogs.com/coser/archive/2011/12/14/2287739.html
首先簡單瞭解一下什麼是json格式:
JSON(JavaScript Object Notation):一種輕量級資料交換格式,相對於XML而言更簡單,也易於閱讀和編寫,機器也方便解析和生成,Json是JavaScript中的一個子集。
JSON建構於兩種結構:
“名稱/值”對的集合(A collection of name/value pairs)。不同的語言中,它被理解為物件(object),紀錄(record),結構(struct),字典(dictionary),雜湊表(hash table),有鍵列表(keyed list),或者關聯陣列 (associative array)。
值的有序列表(An ordered list of values)。在大部分語言中,它被理解為陣列(array)。
這些都是常見的資料結構。事實上大部分現代計算機語言都以某種形式支援它們。這使得一種資料格式在同樣基於這些結構的程式語言之間交換成為可能。
下面是json格式的簡單例子(來自百度百科):
按照最簡單的形式,可以用下面這樣的 JSON 表示”名稱 / 值對”:
{"firstName":"Brett"}這個示例非常基本,而且實際上比等效的純文字”名稱 / 值對”佔用更多的空間:
但是,當將多個”名稱 / 值對”串在一起時,JSON 就會體現出它的價值了。首先,可以建立包含多個”名稱 / 值對”的 記錄,比如:
{"firstName":"Brett","lastName":"McLaughlin","email":"aaaa"}從語法方面來看,這與”名稱 / 值對”相比並沒有很大的優勢,但是在這種情況下 JSON 更容易使用,而且可讀性更好。例如,它明確地表示以上三個值都是同一記錄的一部分;花括號使這些值有了某種聯絡。
表示陣列
當需要表示一組值時,JSON 不但能夠提高可讀性,而且可以減少複雜性。例如,假設您希望表示一個人名列表。在XML中,需要許多開始標記和結束標記;如果使用典型的名稱 / 值對(就像在本系列前面文章中看到的那種名稱 / 值對),那麼必須建立一種專有的資料格式,或者將鍵名稱修改為 person1-firstName這樣的形式。
如果使用 JSON,就只需將多個帶花括號的記錄分組在一起:
{
"people":[
{"firstName":"Brett","lastName":"McLaughlin","email":"aaaa"},
{"firstName 這不難理解。在這個示例中,只有一個名為 people的變數,值是包含三個條目的陣列,每個條目是一個人的記錄,其中包含名、姓和電子郵件地址。上面的示例演示如何用括號將記錄組合成一個值。當然,可以使用相同的語法表示多個值(每個值包含多個記錄):
{
"programmers": [{
"firstName": "Brett",
"lastName": "McLaughlin",
"email": "aaaa"
}, {
"firstName": "Jason",
"lastName": "Hunter",
"email": "bbbb"
}, {
"firstName": "Elliotte",
"lastName": "Harold",
"email": "cccc"
}],
"authors": [{
"firstName": "Isaac",
"lastName": "Asimov",
"genre": "sciencefiction"
}, {
"firstName": "Tad",
"lastName": "Williams",
"genre": "fantasy"
}, {
"firstName": "Frank",
"lastName": "Peretti",
"genre": "christianfiction"
}],
"musicians": [{
"firstName": "Eric",
"lastName": "Clapton",
"instrument": "guitar"
}, {
"firstName": "Sergei",
"lastName": "Rachmaninoff",
"instrument": "piano"
}]
}這裡最值得注意的是,能夠表示多個值,每個值進而包含多個值。但是還應該注意,在不同的主條目(programmers、authors 和 musicians)之間,記錄中實際的名稱 / 值對可以不一樣。JSON 是完全動態的,允許在 JSON 結構的中間改變表示資料的方式。
在處理 JSON 格式的資料時,沒有需要遵守的預定義的約束。所以,在同樣的資料結構中,可以改變表示資料的方式,甚至可以以不同方式表示同一事物。
表示object
{
"name":"test",
"type":{
"name":"seq",
"parameter":["1","2"]
}
}其中type屬性是一個object,也就是屬性巢狀。
以上是json格式的簡單介紹,下面就總結寫python解析json格式和檔案的方法。
Python操作json的標準api庫參考:http://docs.python.org/library/json.html
Python2.6開始加入了json模組,無需另外下載,Python的Json模組序列化與反序列化的過程分別是 encoding和 decoding
encoding(編碼):把一個Python物件編碼轉換成Json字串
decoding(解碼):把Json格式字串解碼轉換成Python物件
對於簡單資料型別(string、unicode、int、float、list、tuple、dict),可以直接處理。
Encoding
python提供了兩種函式來實現編碼過程:
json.dump()和json.dumps(),其中dump()函式是用作檔案操作,將在後面介紹,這裡僅介紹dumps()。
下面看一個例子:
import json as js
obj = [{'aa': 1, 'bb': 2, 'cc': 3},
(1, 2, 3, 4), 'hello world', 0.5, 100, None, True]
print obj
print js.dumps(obj)
#output
[{'aa': 1, 'cc': 3, 'bb': 2}, (1, 2, 3, 4), 'hello world', 0.5, 100, None, True]
[{"aa": 1, "cc": 3, "bb": 2}, [1, 2, 3, 4], "hello world", 0.5, 100, null, true]我們可以看到得到的輸出原資料和類似,但是還是有些細微的不同,例如上例中的元組則轉換為了列表。在json的編碼過程中,會存在從python原始型別向json型別的轉化過程,具體的轉化對照如下:
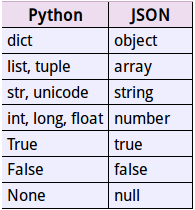
Decoding
同樣,json模組提供了json.load和json.loads兩個函式來實現解碼,load()函式一般用來讀取json檔案,下面先介紹json.loads函式。、
import json as js
obj = [{'aa': 1, 'bb': 2, 'cc': 3},
(1, 2, 3, 4), 'hello world', 0.5, 100, None, True]
tmp = js.dumps(obj)
x = js.loads(tmp)
print tmp
print x
print type(x)
#output
[{"aa": 1, "cc": 3, "bb": 2}, [1, 2, 3, 4], "hello world", 0.5, 100, null, true]
[{u'aa': 1, u'cc': 3, u'bb': 2}, [1, 2, 3, 4], u'hello world', 0.5, 100, None, True]
<type 'list'>loads方法返回了原始的物件,但是仍然發生了一些資料型別的轉化。比如,上例中‘aa’轉化為了unicode型別。從json到python的型別轉化對照如下:
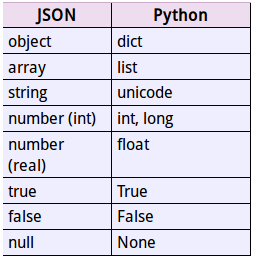
以上是對簡單型別的編碼解碼過程。另外需要注意的是,在編碼過程中,預設的設定下,編碼產生的json字串過於緊湊導致可讀性不高,另外也沒有順序,為了提高可讀性,dumps函式提供其他一些可選引數,下面介紹一些常用的引數:
dumps函式的定義為:
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding="utf-8", default=None, sort_keys=False, **kw)1) skipkeys:布林型,預設為False,如果設為True的話,在dict中的key值如果出現非 (str, unicode, int, long, float, bool, None)物件,則跳過該key而不是丟擲 ValueError。
2) indent:非負整數,表示編碼後的字串的縮排方式,預設為None表示無縮排,一般設為4,如果設為0則只會新增換行符。
3) separators:元組,預設為None,如果設定的話,一般設為(’,’,’:’),表示把’,’和‘:’後面的空格去掉,用來精簡輸出字串。
4) sort_keys: 布林型,預設為False,如果設為True,則輸出的dict會按照key值排序。
import json as js
obj = [{'aa': 1, 'bb': 2, 'cc': 3},
(1, 2, 3, 4), 'hello world', 0.5, 100, None, True]
print 'Original:', js.dumps(obj)
print 'Sort Keys:', js.dumps(obj, sort_keys=True)
print 'Indent:', js.dumps(obj, indent=4)
print 'Separators:', js.dumps(obj, separators=(',', ':'))
#Output
Original: [{"aa": 1, "cc": 3, "bb": 2}, [1, 2, 3, 4], "hello world", 0.5, 100, null, true]
Sort Keys: [{"aa": 1, "bb": 2, "cc": 3}, [1, 2, 3, 4], "hello world", 0.5, 100, null, true]
Indent:
[
{
"aa": 1,
"cc": 3,
"bb": 2
},
[
1,
2,
3,
4
],
"hello world",
0.5,
100,
null,
true
]
Separators: [{"aa":1,"cc":3,"bb":2},[1,2,3,4],"hello world",0.5,100,null,true]以上都是json對簡單資料型別的編碼解碼,那麼如何對自定義的型別進行編碼呢。預設情況下,json是不認識使用者自己定義的型別的,這時會丟擲一個TypeError。如果要讓json能編碼自己定義的型別,需要自己定義一個轉化函式,將MyObj轉化成dict,然後在呼叫json.dumps函式的時候,需要將dumps的default引數設定為轉化函式:
import json as js
class MyObj(object):
def __init__(self, s):
self.s = s
def __repr__(self):
return '<MyObj(%s)>' % self.s
obj = MyObj(12)
try:
print js.dumps(obj)
except TypeError, err:
print err
def convert_to_builtin_type(obj):
print 'default(', repr(obj), ')'
d = {'__class__': obj.__class__.__name__,
'__module__': obj.__module__,
}
d.update(obj.__dict__)
return d
print js.dumps(obj, default=convert_to_builtin_type)
#Output
<MyObj(12)> is not JSON serializable
default( <MyObj(12)> )
{"s": 12, "__module__": "__main__", "__class__": "MyObj"}相反,如果要把json decode 成python物件,同樣也需要自定轉換函式,傳遞給json.loads方法的object_hook引數:
def dict_to_object(d):
if '__class__' in d:
class_name = d.pop('__class__')
module_name = d.pop('__module__')
module = __import__(module_name)
print "MODULE:", module
class_ = getattr(module, class_name)
print "CLASS", class_
args = dict((key.encode('ascii'), value) for key, value in d.items())
print 'INSTANCE ARGS:', args
inst = class_(**args)
else:
inst = d
return inst
encoded_object = '[{"s":"helloworld","__module__":"__main__","__class__":"MyObj"}]'
myobj_instance = js.loads(encoded_object, object_hook=dict_to_object)
print myobj_instance
#Output
MODULE: <module '__main__' from 'jsonIO.py'>
CLASS <class '__main__.MyObj'>
INSTANCE ARGS: {'s': u'helloworld'}
[<MyObj(helloworld)>]對json檔案進行讀寫
以上例子都是在程式碼中直接定義python型別和json字串,下面介紹如何對json檔案進行讀寫並進行編碼解碼。
前面已經提到,json模組中對檔案操作的函式分別為 json.load()和json.dump(),他們操作都和dumps和loads類似,下面舉兩個小例子,分別對應解碼和編碼。
1) 讀取json檔案並進行解碼。
假設檔案 ‘my.json’中的內容為:
#my.json
{
"name":"test",
"type":{
"name":"seq",
"parameter":["1","2"]
}
}下面的程式碼讀取‘my.json’檔案並進行解碼:
import json as js
f = file('my.json')
print js.load(f)
#Output
{u'type': {u'parameter': [u'1', u'2'], u'name': u'seq'}, u'name': u'test'}2)對python型別進行編碼並寫入檔案
編碼也基本類似,不多說了,直接上程式碼:
import json as js
out = file('output.json', 'w+')
obj = [{'aa': 1, 'bb': 2, 'cc': 3},
(1, 2, 3, 4), 'hello world', 0.5, 100, None, True]
js.dump(obj, out, indent=4)程式執行完之後可以看到 output.json檔案中的內容為:
[
{
"aa": 1,
"cc": 3,
"bb": 2
},
[
1,
2,
3,
4
],
"hello world",
0.5,
100,
null,
true
]python對json的解析總結就到這裡。
以上