
【hibernate】 hibernate 註解之 SequenceGenerator
當使用hibernate 連線 oracle 資料庫的時候,如果想使主鍵進行自增,那麼不可避免將會使用 SequenceGenerator 註解, 此註解有一個比較困惑的屬性: allocationSize,
1. hibernate 配置
@Id @SequenceGenerator(name = "T_USER_GENERATOR", sequenceName = "SEQ_USER_USERID_TEST",allocationSize = 100) @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "T_USER_GENERATOR") @DocumentHelper(documentation = "fpId", example = "0") private Long userId;
2. oracle 序列
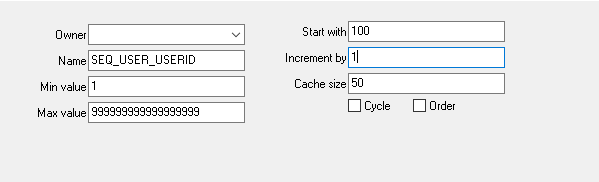
3. 分析:
1. oracle 序列配置: 序列開始為 100, 快取為50, 這是oracle 自身做的快取,因為查詢序列時,會加鎖,所以採用快取來提升效能。 如果查詢序列會發現,每查詢50次,star with 值跳一次,每次加50. 也就是說,oracle 每次快取50 個值,這50個值用完了,再進行一次快取。序列值應該為 100 , 101, 102 。。。。
2. hibernate配置: hibernate 中 allocationSize 的值為100, 這個相當於二級快取,用hibernate 的save 方法儲存,會發現id 會從 10000 開始, 10000,10001,10002...., 這是將 start with 的值 和 allocationSize 的值相乘之後得到的,每使用 hibernate save 方法 儲存100 個數據,sequence 中消耗 50 個快取中的一個, 這樣也就是說,每執行 5000 個save 方法,start with 才跳動且自增50, 注意是自增50 ,而不是自增5000. 這一點兒是尤其要注意的,一不小心就會容易導致主鍵衝突。
3. 推測: 個人感覺, hibernate allocationSize 邏輯如下: 第一次呼叫是,計算起始id, 即 oracle 序列 startwith * allocationSize , 然後自增獲取100個 ,進行快取, 當這100 個用完之後, 則再次進行獲取id,進行快取。
ps: 在負載均衡下,如果使用allocationSize 會導致一個新的問題, 就是如果按 id 排序,id 最大的則有可能不是最新插入的資料, 因此也就不能通過id 的大小,表示插入的順序,而需額外的時間欄位表示。 原因: 假如有3臺負載均衡A, B, C, 配置如上配置, 那麼A, B, C 第一次呼叫此物件的save 操作時,會各自計算開始id, ABC 開始id 分別為: A: 10001, B: 10101, B:10201 ,如果再次進行save 操作時,則在 各自起始id
上自增, 那麼如果B 上先呼叫,則id 為 10102, 然後A 再呼叫,id 則為 10002, 這樣雖然10102 先儲存,10002 後儲存,但是id 卻是 10102 <10002.