
運動目標跟蹤(十四)--MIL跟蹤
原文:
http://blog.csdn.net/ikerpeng/article/details/19235391
文章:Robust object tracking with on-line multiple instance learning
Boris Babenko, Student Member, IEEE, Ming-Hsuan Yang, Senior Member, IEEE and Serge Belongie, Member, IEEE ;PAMI ,2011.
文章開頭就說的明瞭:本文的tracking只給定了第一幀目標的位置,沒有其餘的資訊了(上一篇論文是拿了前10幀的圖片來訓練的)。本文解決的問題同樣是on-line tracking出現的漂移的問題(Slight inaccuracies in the tracker can therefore lead to incorrectly labeled sample)。使用的方法是:MIL。特點是:調節的引數少。(BTW:其中提到了一個叫做bootstrap的概念,通俗的將就是對已有的觀測樣本反覆的有放回抽樣,通過多次計算這些放回抽樣的結果,獲取統計量的分佈。)
接下來,文章介紹了跟蹤中當前存在的主要挑戰: 1、形變所產生的巨烈的表觀的變化;2、平面外的旋轉;3、場景光照度的變化。 同時,介紹了典型的跟蹤系統的三個組成部分:1、appearance model,估計跟蹤目標在特定位置的可能性; 2、 motion model ,同跟蹤物體隨時間改變的位置有關;3、a search strategy for finding,找到當前幀中目標最有可能的位置。本文重點放在第一部分,作者想達到的目標是能夠跟蹤到部分遮擋的物體而不出現明顯的漂移,並且只有較少的引數。
對於appearance model的設計,一般有兩種考慮。一種是隻model 目標;另一種是將目標和背景都model。而後者其他領域已經取得了成功。參見後者,在on-line tracking中,常用的更新自適應appearance model的方法是:將當前tracker的位置作為正樣本(有的時候也擴充套件非常鄰近的位置作為正樣本),將這個位置周圍的位置作為負樣本來更新appearance
model。這也使得漂移的產生成為可能。為了解決這個問題,引入了半監督的方法。如Grabner et al.提出的semi-supervised的方法,將tracker得到的目標都認為是無標籤的樣本,而只有第一幀中的樣本是有標籤的。然後通過聚類的方法給定這些無標籤樣本一個偽標籤,在繼續使用有標籤的方法進行跟蹤。這個方法沒有充分的利用到視訊中有用資訊
對於tracker得到的或是擴充套件得到的影象patch塊,計算出每個patch塊的Harr-like特徵,對於每一個影象patch塊x,都由Harr-like特徵的feature vector表示。對於每一幀待檢測的影象,提取一個patch塊的集合,這個集合滿足: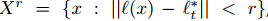
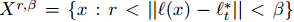
同時也可以考慮引入尺度變換引數,這樣的好處是結果可以更加的準確;壞處是增加了引數的空間維度。可根據需求決定。
所以問題的關鍵是要求得使得概率最高時的那個bag(集合X),即:argmax(L),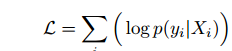
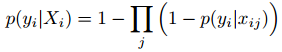
於是,仿造on-line boosting的方法,構造on-line MIL演算法。
首先,由第一幀得到的資訊,擴充套件正負樣本,形成一組由patch塊集合組成的資料集bags(帶標籤的);
然後,計算各個patch塊的harr-like特徵向量,用它來表示每一個image patch 塊。樣本的特徵的條件概率分佈滿足高斯分佈,均值和方差分別通過新得到樣本更新,再由貝葉斯法則得到它的概率;
然後,構造一組M個弱分類;通過公式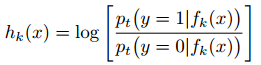
接下來,(用motion model 根據上一幀目標的位置,擴充套件目標的可能位置;根據公式: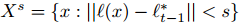
然後,計算上面得到的目標位置集合中樣本的似然概率的最大值,並將這個樣本作為當前幀目標的位置;概率可以由sigmoid函式表示,又根據NOR model知道
最後,由上面更新的目標的位置,跟新分類器,如此在迭代上述過程。
個人覺得這篇文章的思想非常的新穎。漂移問題是on-line tracking最主要的問題。引起漂移最主要的原因就是,分類器更新時使用的樣本本身的準確率存在問題。為了解決這個問題。有的作者採取的方式是放棄掉tracker得到的結果。將這些得到的patch塊認為是無標籤的,再通過聚類的方式得到一個偽標籤,再通過有標籤的方式來訓練分類器。很顯然這樣的結果可以很好的解決目標跑出視訊的情況。當目標再一次出現的時候可以繼續跟蹤到。但是,這樣浪費掉了很多的有用資訊。同時,增加了偽標籤的求解過程,速度應該比on-line boosting方法還要慢。而本文作者處理的方式是:既然所得到的樣本標籤的準確率有問題,那麼對得到的樣本進行擴充套件,作為一個事件集。選出裡面錯誤率最低的時間來更新目標的位置,也由此來更新分類器。準確率和速度都會好很多。