
Matlab 平行計算學習初步
Matlab 平行計算學習
1. 簡介
高效能運算(High Performance Computing,HPC)是電腦科學的一個分支,研究並行演算法和開發相關軟體,致力於開發高效能運算機。可見平行計算是高效能運算的不可或缺的重要組成部分。
1.1 平行計算
平行計算(Parallel Computing)是指同時使用多種計算資源解決計算問題的過程,是提高計算機系統計算速度和處理能力的一種有效手段。它的基本思想是用多個處理器來協同求解同一問題,即將被求解的問題分解成若干個部分,各部分均由一個獨立的處理機來平行計算。平行計算系統既可以是專門設計的、含有多個處理器的超級計算機,也可以是以某種方式互連的若干臺的獨立計算機構成的叢集。通過平行計算叢集完成資料的處理,再將處理的結果返回給使用者
1.2 平行計算平臺
平臺是平行計算的載體,它決定著你可以用或只能用什麼樣的技術來實現平行計算。
多核和叢集技術的發展,使得並行程式的設計成為提高數值計算效率的主流技術之一。常用的小型計算平臺大致分為:由多核和多處理器構建的單計算機平臺;由多個計算機組成的叢集(Cluster)。前者通過共享記憶體進行資料互動,後者通過網路進行資料通訊。
計算正在從 CPU(中央處理)向 CPU 與 GPU(協同處理)的方向發展。
GPU最早主要應用在圖形計算機領域,近年來,它在通用計算機領域得到了迅猛的發展,使用GPU做平行計算已經變得越來越重要和高效。
常用的平行計算技術包括多執行緒技術、基於共享記憶體的OpenMP技術,基於叢集的MPI技術等。但它們都需要使用者處理大量與平行計算演算法無關的技術細節,且不提供高效的演算法庫,與數值計算的關聯較為鬆散。
1.3 Matlab與平行計算
Matlab即是一款數值計算軟體,又是一門語言,它已經成為數值計算領域的主流工具。Matlab提供了大量高效的數值計算模組和豐富的資料顯示模式,便於使用者進行快速演算法的研究和科學建模模擬。自Matlab 2009 之後,Matlab推出了平行計算工具箱(Parallel ComputingToolbox,PCT)和平行計算服務(Distributed ComputingServer,DCS),通過PCT和DCS使用者可以實現基於多核平臺、多處理器平臺和叢集平臺的多種平行計算任務。利用PCT和DCS,使用者無需關心多核、多處理器以及叢集之間的底層資料通訊,而是將主要精力集中於並行演算法的設計。此外,PCT還增加了對GPU(Graphics ProcessingUnit)的支援。
2. Matlab平行計算初探
Matlab 平行計算工具箱,使用多核處理器,GPU和計算機叢集,解決計算和資料密集型問題。高層次的結構並行for迴圈,特殊陣列型別和並行數值演算法,讓你在沒有而CUDA或MPI程式設計基礎的條件下並行MATLAB應用程式。您可以使用帶有Simulink的工具箱並行執行一個模型的多個模擬。
該工具箱,通過在本地workers(MATLAB計算引擎)上執行應用程式,來使用多核桌上型電腦的全部處理能力。不用改變程式碼,就可以在計算機叢集或網格計算服務(使用MATLAB分散式計算伺服器™)上執行相同的應用程式。可以互動地或批處理地執行並行應用程式。
包含以下特性:
- 並行for迴圈 (parfor),可以在多個處理器上執行任務並行演算法。
- 支援CUDA的NVIDIA GPU。
- 通過本地workers,充分利用桌上型電腦的多核處理器。
- 計算機叢集和網格計算支援(通過MATLAB分散式計算服務)。
- 以互動方式和批量方式執行並行應用程式。
- 分散式陣列和SPMD(single-program-multiple-data),用於大型資料集的處理和資料並行演算法。
本文僅介紹迴圈的並行,批處理和GPU平行計算。
2.1 並行池
2.1.1 開啟和配置並行池
在使用parfor和spmd之前,首先要配置和開啟平行計算池。parpool函式[1]提供並行池的配置和開啟功能,其用法如下表 2‑1:
表 2‑1 parpool函式用法

此外,還可以給上述命令指定輸出引數,如輸入:p = parpool,輸出如下圖:
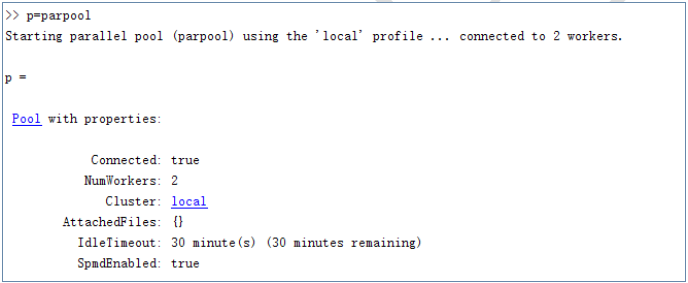
圖2‑1 輸入命令p=parpool時的執行結果
輸出引數p為並行池物件,一個池物件有7中屬性,上圖顯示了6種屬性。其中,“NumWorkers” 代表worker的個數,也就是說開啟了兩個並行池;“IdleTimeout”指定了池定時關閉的時長,單位為分鐘,圖中為30分鐘;“SpmdEnabled”指定池是否可以執行SPMD程式碼,其它屬性相見Matlab 並行工具箱手冊[2]。
此外,可以通過p.Property 訪問和設定屬性,如p.IdleTimeout = 10; 可以設定定時關閉池的時長為10分鐘。
如果在啟動池時沒有設定輸出引數p,可以使用gcp函式獲取當前池的物件,gcp的用法如下表2-2:
表 2‑2 gcp用法
|
語法和引數 |
功能 |
|
p = gcp |
獲取當前池物件,如果未開啟,則使用預設配置檔案建立池。 |
|
p = gcp('nocreate') |
獲取當前池物件,如果未開啟,返回空。 |
Matlab中,使用delete函式關閉或刪除池,用法:delete(poolobj),其中poolobj為要關閉的池物件。
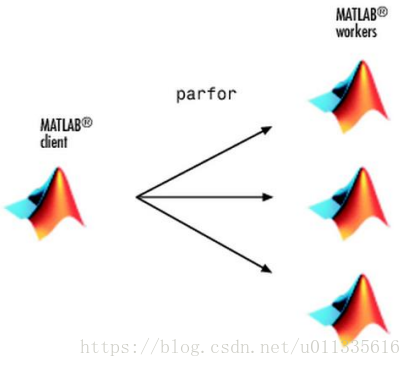
|
圖 2‑2 Matlab client 分配parfor並行任務到多個Matlab |
Matlab並行執行parfor迴圈時,採用client和worker模式。其中client指編寫和啟動並行程式碼的Matlab段,worker指並行執行程式碼的Matlab端。使用者可以將Matlab軟體理解為一個程序,在同一計算機或網路上的多個計算機上可以執行多個Matlab程序,每個Matlab程序之間通過某種方式進行資料傳輸,使用者首先在client端編寫程式碼,然後再client端執行編寫的程式碼,在執行程式碼的過程中,如果某個程式需要並行執行,Matlabclient端根據並行程式碼的關鍵字及型別將並行程式碼分配到本機或網路上的其它Matlab程序執行,那些最終執行並行程式碼的Matlab程序即為worker[3]。右圖顯示了,Matlab client 對parfor關鍵字的處理,它將任務分配到多個Matlab workers 上並行執行程式。假設m為Matlab worker的數量,迴圈次數為n,若n/m為整數的話,則迴圈將被均勻劃分到Matlab worker;否則,迴圈被非均勻劃分,有些Matlab worker的負載會大些。
應用parfor的一個基本前提是迴圈可以被等效分解,即分解後的迴圈的執行順序不會影響最終結果。parfor的用法與for類似,其語法如下表 2‑3:
表2‑3 parfor的用法
|
語法和引數 |
功能 |
|
parfor loopvar = initval:endval,statements,end |
在並行池中執行迴圈。其中initval和endval必須為正整數,或者是一個包含連續遞增的整數行向量。parfor i = range; <loop body>; end ,這樣單行書寫也是可以的,其中的“;”可以是“,”。 |
|
parfor (loopvar = initval:endval, M), statements, end |
使用M指定執行迴圈體的Matlab worker的最大數量,M為非負整數,如果M=0,則在client上序列執行。 |
平行計算間的資料轉移大小極限受Java虛擬機器(JVM)記憶體分配的限制。在MJS叢集上執行job的client和worker間的單次資料轉移量也受此限制。具體大小限制取決於系統結構。如下表所示:
表 2‑4 每次轉移資料的最大量與系統結構的關係
|
系統結構(System Architecture) |
每次轉移資料的最大數(近似值.) |
|
64-bit |
2.0 GB |
|
32-bit |
600 MB |
使用parfor並行for迴圈的基本步驟為:
1) 使用parpool函式配置和開啟平行計算池。
2) 將序列迴圈中的for關鍵字改為parfor,並注意是否要修改迴圈體,以滿足特定要求,如迴圈變數的型別要求(參見參考手冊)
3) 執行完畢後若不再進行平行計算,使用delete關閉並行池。
batch函式完成函式或指令碼在叢集或桌上型電腦上的分載執行,也就是實現函式或指令碼的並行。這裡不再說明語法(詳見Matlab 並行工具箱參考手冊),而是舉兩個例子說明它的使用方法(此例子亦來自參考手冊)。
建立mywave.m指令碼檔案,輸入如下程式碼並儲存:
|
for i=1:1024 A(i) = sin(i*2*pi/1024); end |
在命令列視窗輸入:job = batch('mywave'),Matlab以下圖所示方式並行執行:
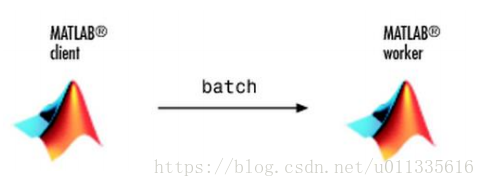
圖 2‑3 批處理for迴圈
然後等待作業完成:wait(job),使用load命令將資料從Matlabworker 轉移到Matlabclient的workspace,即load(job,’A’)。任務完成後,使用delete(job)永久刪除它的資料。
開啟mywave.m指令碼檔案,修改for為parfor,儲存,程式碼如下:
|
parfor i=1:1024 A(i) = sin(i*2*pi/1024); end |
輸入:job =batch('mywave','Pool',2),以兩個worker來執行parfor並行迴圈任務,所以此例總共使用3個本地worker,如下圖所示:
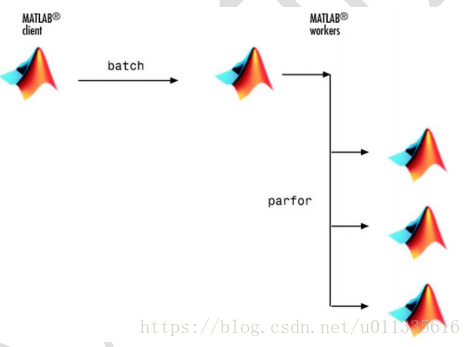
圖2‑4 批處理並行迴圈
同樣的,依次使用wait(job)、load(job,'A'),將資料從worker的workspace轉移到client的workspace。最後,使用delet(job)刪除資料。
批處理命令還有其它的執行方式,在此不再介紹。
Matlab 的GPU計算實現MATLABworkspace和圖形處理器(GPU)間的資料傳遞;在GPU上執行程式碼。
使用者可以使用計算機的GPU處理矩陣運算,在大多數情況下,在GPU上執行要比在CPU上快。
Matlab的GPU計算提供了下表 2‑5所列的14種MATLAB函式和1種C語言函式,表中僅簡要介紹函式功能,具體參見Matlab並行工具箱參考手冊。
表2‑5 GPU計算函式列表
|
函式 |
功能 |
|
gpuArray |
在GPU上建立陣列。 |
|
gather |
把分散式陣列或gpuArray轉移到Matlab的workspace。 |
|
existsOnGPU |
確定gpuArray或CUDAKernel在GPU上可用。 |
|
gpuDevice |
查詢或選擇GPU裝置。 |
|
gpuDeviceCount |
目前GPU的裝置數量。 |
|
gputimeit |
在GPU上執行函式所需時間。 |
|
reset |
重置GPU裝置並清空它的記憶體。 |
|
wait(GPUDevice) |
等待GPU計算完成。 |
|
arrayfun |
對GPU陣列上的每個元素應用函式。 |
|
bsxfun |
用於GPU陣列的二元但擴充套件函式。 |
|
pagefun |
對GPU陣列的每一頁應用函式。 |
|
parallel.gpu.CUDAKernel |
從PTX和CU程式碼建立 GPU CUDA kernel 物件。 |
|
feval |
評估GPU的核。 |
|
setConstantMemory |
設定GPU的一些常量記憶體。 |
|
mxInitGPU |
這是一個C語言函式,在當前選擇的裝置上初始化Matlab GPU計算庫。 |
Matlab的GPU計算提供了三種Matlab類和一種C類,如下表 2‑6
表2‑6 Matlab GPU計算提供的類
|
類 |
描述 |
|
gpuArray |
儲存在GPU上的陣列 |
|
GPUDevice |
圖形處理單元Graphics processing unit (GPU) |
|
CUDAKernel |
執行在GPU上的核 |
|
它是一個C類,MEX函式可以訪問Matlab的gpuArray |
關於各類的具體含義和各函式的詳細用法請參見MATLAB並行工具箱手冊。
下面主要從:GPU裝置查詢、在GPU上建立陣列、在GPU上執行內建函式、在GPU上執行自定義函式四個方面說明Matlab GPU計算支援的技術,此外,使用者還可以在GPU上執行CUDA或PTX程式碼、執行包含CUDA程式碼的MEX-函式等等,詳見MATLAB並行工具箱手冊和文獻[3]的第10章。
1.4.1. GPU 裝置查詢與選擇
|
圖 2‑5 GPU裝置資訊 |
GPU裝置查詢與選擇
在使用GPU裝置之前,可以利用gpuDeviceCount函式檢視計算機當前可用GPU裝置數量,若存在可用的GPU裝置,則輸出大於等於1的數。
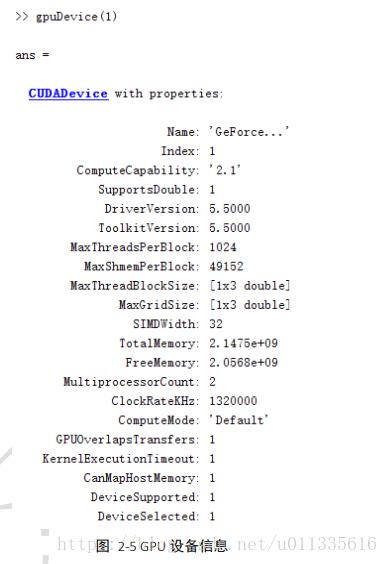
在Matlab中使用gpuDevice(IDX)來選擇第IDX個GPU裝置,起始編號為1,如輸入gpuDevice(1),輸出右圖所示結果:
其中,“MaxThreadsPerBlock”表示每個Block的最大執行緒數;“MaxShmemPerBlock”表示每個Block可用的最大共享記憶體大小;“TotalMemory”表示GPU擁有的所有記憶體,圖中為2.1475e+09Byte,即2GB;“FreeMemory”代表可用記憶體;“MultiprocessorCount”表示GPU裝置處理器個數;“DeviceSupported”表示本機Matlab支援的GPU裝置數。
有兩種方式在GPU上建立陣列:從Workspace轉移和直接建立。
1) 從Workspace轉移到GPU
使用gpuArray函式來把資料從Workspace轉移到GPU,如下面的程式碼所示,將Workspace中的陣列A轉移到GPU中,並存為G,原Workspace中的A陣列並不消失。
|
A = [1 2 3;4 5 6]; G = gpuArray(A); |
該函式支援對非稀疏陣列且可以是:'single','double','int8','int16','int32','int64','uint8','uint16','uint32','uint64',or 'logical'型別。
gpuArray類提供了一些方法來在GPU上直接建立陣列,這樣就不需要從Workspace進行轉移。可用的有:
表 2‑7 gpuArray類提供的建立GPU陣列的方法
|
方法 |
方法 |
|
eye(___,'gpuArray') |
rand(___,'gpuArray') |
|
false(___,'gpuArray') |
randi(___,'gpuArray') |
|
Inf(___,'gpuArray') |
randn(___,'gpuArray') |
|
NaN(___,'gpuArray') |
|
|
ones(___,'gpuArray') |
|
|
true(___,'gpuArray') |
|
|
zeros(___,'gpuArray') |
gpuArray.colon |
如:G = ones(100,100,50,'gpuArray');在GPU上建立一個100-by-100-by-50的陣列。
此外,支援gpuArray陣列的方法還有abs,cos,fft,conv,plot等等共369個方法。若要檢視,輸入如下命令即可檢視:
|
methods('gpuArray') |
如果,要檢視某個方法的幫助,輸入如下命令檢視:
|
help gpuArray/functionname |
其中,functionname為函式名,如:helpgpuArray/dot。
3) 從GPU上回收資料
從GPU上回收資料,即把資料從GPU轉移到MatlabWorkspace。在Matlab中使用gather函式來取回GPU上的資料並存在Matlab的 Workspace中。可以使用isequal函式來驗證轉移前後,值是否相同。如下程式碼將GPU中的陣列G傳回到Workspace生成D。
|
G = gpuArray(ones(100,'uint32')); D = gather(G); OK = isequal(D,G) |
如 2)直接建立GPU陣列 所述,Matlab的369個函式都支援對GPU陣列的操作,下面是手冊上的一個示例程式碼:
|
Ga = rand(1000,'single','gpuArray'); Gfft = fft(Ga); Gb = (real(Gfft) + Ga) * 6; G = gather(Gb); |
程式碼主要實現對GPU上的陣列Ga進行FFT變換,並將結果回收到Workspace。可見內建函式的呼叫與普通序列程式沒有大的區別,只是輸入陣列的型別為gpuArray。
Matlab中使用arrayfun或bsxfun來執行自定義的函式,即:
|
result = arrayfun(@myFunction,arg1,arg2); |
下面舉例來說明,建立myfun.m檔案,開啟輸入如下程式碼:
|
function [ absga1,absga2,maxga ] = myfun( ga1,ga2 ) absga1 = abs(ga1); absga2 = abs(ga2); maxga = max(absga1,absga2); |
該程式碼實現對輸入陣列ga1,ga2的每個元素取絕對值,然後取出兩者中對應最大的。為了執行並檢視結果,建立一個指令碼,輸入如下程式碼:
|
ga1 = [-1 5 -3] ga2 = gpuArray([4 -6 -2]) [absga1,absga2,maxga] = arrayfun(@myfun,ga1,ga2) absda1 = gather(absga1) absda2 = gather(absga2) maxda = gather(maxga) |
通過上述程式,可以看出,在自定義函式myfun中,只要有一個輸入引數的型別為gpuArray,則整個函式myfun都將執行在GPU中,對於非gpuArray型別的陣列,Matlab自動進行轉換。
除了可以呼叫Matlab自身支援的函式外,可以自己編寫支援GPU的Matlab函式。自定義的函式中可以呼叫的函式和操作如下表 2 8:
表2‑8 自定義函式中支援gpuArray的函式和操作
|
abs and acos acosh acot acoth acsc acsch asec asech asin asinh atan atan2 atanh beta betaln bitand bitcmp bitget bitor bitset bitshift bitxor ceil complex conj cos cosh cot coth csc csch |
double eps eq erf erfc erfcinv erfcx erfinv exp expm1 false fix floor gamma gammaln ge gt hypot imag Inf int8 int16 int32 int64 intmax intmin isfinite isinf isnan ldivide le log log2 |
log10 log1p logical lt max min minus mod NaN ne not or pi plus pow2 power rand randi randn rdivide real reallog realmax realmin realpow realsqrt rem round sec sech sign sin single |
sinh sqrt tan tanh times true uint8 uint16 uint32 uint64 xor + - .* ./ .\ .^ == ~= < <= > >= & | ~ && || |
以下的標量擴充套件版: * / \ ^ 分支指令: break continue else elseif for if return while |
2. 總結
本文簡要介紹了Matlab並行工具箱及其用法,包括多處理器的並行和GPU的並行,具體包括:平行計算池的開啟,查詢與關閉;for迴圈的並行;批處理;GPU計算。由於時間關係並未介紹分散式陣列和SPMD。
嘗試並行化自己改進的Hough變換演算法和FCM,可是並行後的效果很差(這和使用的電腦的配置有關),本文中並未給出,將來會進一步研究。
之所以選擇高效能運算這門課,是因為在研究學習中,發現程式的執行速度是一個很重要和亟待解決的問題。已經儘量採用向量化程式設計實現,可是它的本質是犧牲空間換時間,仍不能滿足需求。高效能運算讓我找到了突破點,將來會繼續開展相關的工作。
[3] 實戰 Matlab之並行程式設計[J]. 2012.