
【Flume】【原始碼分析】flume中事件Event的資料結構分析以及Event分流
阿新 • • 發佈:2019-02-10
前言
首先來看一下flume官網中對Event的定義
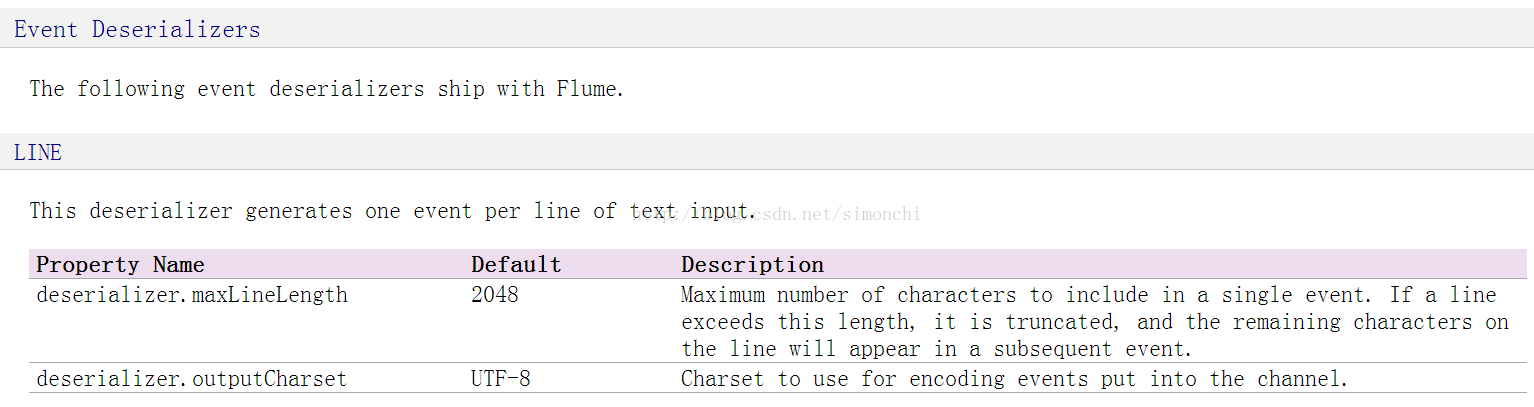
一行文字內容會被反序列化成一個event【序列化是將物件狀態轉換為可保持或傳輸的格式的過程。與序列化相對的是反序列化,它將流轉換為物件。這兩個過程結合起來,可以輕鬆地儲存和傳輸資料】,event的最大定義為2048位元組,超過,則會切割,剩下的會被放到下一個event中,預設編碼是UTF-8,這都是統一的。
但是這個解釋是針對Avro反序列化系統中的Event的定義,而flume ng中很多event用的不是這個,所以你只要記住event的資料結構即可,上面這個解釋可以忽略。
一、Event定義
很簡單的資料結構public interface Event { /** * Returns a map of name-value pairs describing the data stored in the body. */ public Map<String, String> getHeaders(); /** * Set the event headers * @param headers Map of headers to replace the current headers. */ public void setHeaders(Map<String, String> headers); /** * Returns the raw byte array of the data contained in this event. */ public byte[] getBody(); /** * Sets the raw byte array of the data contained in this event. * @param body The data. */ public void setBody(byte[] body); }
header是一個map,body是一個位元組陣列,body才是我們實際使用中真正傳輸的資料,header傳輸的資料,我們是不會是sink出去的。
二、Event如何產出以及如何分流
while ((line = reader.readLine()) != null) { synchronized (eventList) { sourceCounter.incrementEventReceivedCount(); eventList.add(EventBuilder.withBody(line.getBytes(charset))); if(eventList.size() >= bufferCount || timeout()) { flushEventBatch(eventList); } } }
public static Event withBody(byte[] body, Map<String, String> headers) { Event event = new SimpleEvent(); if(body == null) { body = new byte[0]; } event.setBody(body); if (headers != null) { event.setHeaders(new HashMap<String, String>(headers)); } return event; }
這裡是單純的包裝了event的body內容,line即是我們真正的資料內容,將其轉換成UTF-8編碼的位元組內容分裝到event的body中,它的header是null。
用的是SimpleEvent類。
header的話,就是在分裝Event物件的時候,我們可以自定義的設定一些key-value對,這樣做的目的,是為了後續的通道多路複用做準備的
在source端產出event的時候,通過header去區別對待不同的event,然後在sink端的時候,我們就可以通過header中的key來將不同的event輸出到對應的sink下游去,這樣就將event分流出去了,但是這裡有一個前提:不建議通過對event的body解析來設定header,因為flume就是一個水槽,水槽是不會在中間對水進行加工的,要加工,等水流出去了再加工
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = host
a1.sources.r1.interceptors.i1.hostHeader = hostnamea1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = state
a1.sources.r1.selector.mapping.CZ = c1
a1.sources.r1.selector.mapping.US = c2 c3
a1.sources.r1.selector.default = c4每個sink配置的通道區別開就行了。