Spark總結(三)——RDD的Action操作
1、foreach操作:對RDD中的每個元素執行f函式操作,返回Unit。
def funOps1(): Unit = {
var rdd1 = sc.parallelize(List(1, 2, 3, 5, 6))
rdd1.foreach(println _)
}原始碼:

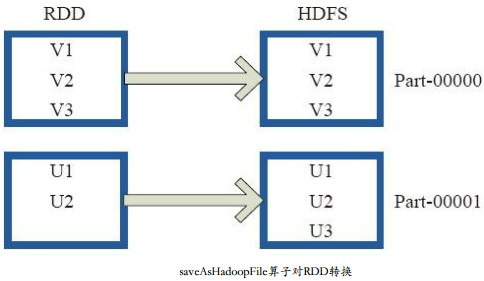
2、saveAsTextFile操作:將資料輸出到hdfs上,將RDD中的每個元素對映轉變為(Null, e.toString),然後將其寫入HDFS。RDD的每個分割槽儲存為HDFS中的一個Block。
def funOps2(): Unit = {
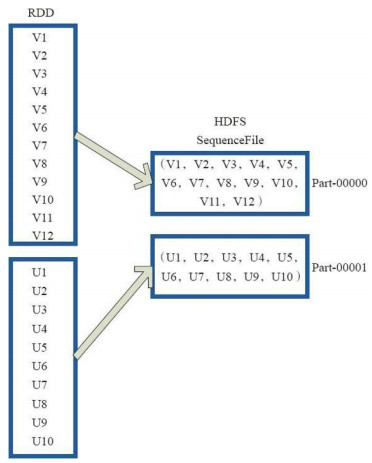
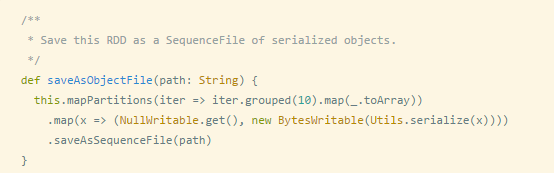
var rdd1 = sc.parallelize(List(1 3、saveAsObjectFile操作:saveAsObjectFile將分割槽中的每10個元素組成一個Array,然後將這個Array序列化,對映為(Null,BytesWritable(Y))的元素,寫入HDFS為SequenceFile的格式。
def funOps2(): Unit = {
var rdd1 = sc.parallelize(List(1, 2, 3, 5, 6))
var rdd2 = rdd1.map(_ + 1 原始碼:
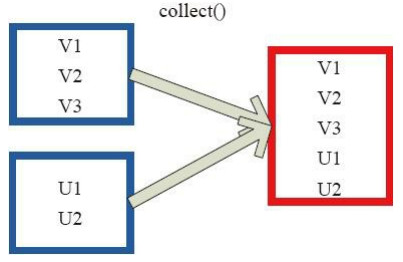
4、collect操作:相當於toArray操作,將分散式的RDD轉為一個數組返回到Driver程式所在的節點。
scala> var rdd1 = sc.parallelize(List(1, 2, 3, 5, 6))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[45] at parallelize at <console>:27 5、collectAsMap操作:對(k,v)型的RDD資料轉為一個單機的HashMap返回到Driver程式所在的節點。如果有重複的k,則後面的元素覆蓋前面的。
原始碼:

6、reduceByKeyLocally操作:實現的是先reduce再collectAsMap的功能,先對RDD的整體進行reduce操作,然後再收集所有結果返回為一個HashMap。
7、Lookup操作:對(K,V)型的RDD操作,返回指定K對應的元素形成的Seq。這個函式處理優化的部分在於,如果這個RDD包含分割槽器,則只會對應處理K所在的分割槽,然後返回由(K,V)形成的Seq。如果RDD不包含分割槽器,則需要對全RDD元素進行暴力掃描處理,搜尋指定K對應的元素。
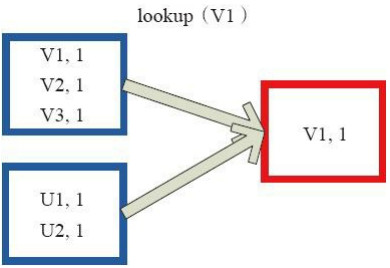
左側方框代表RDD分割槽,右側方框代表Seq,最後結果返回到Driver所在節點的應用中。
8、count操作:返回RDD中元素個數。
scala> var rdd1 = sc.parallelize(List(1, 2, 3, 5, 6))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[47] at parallelize at <console>:27
scala> rdd1.count
res23: Long = 5 9、top操作:返回RDD中最大的k個元素
scala> var rdd1 = sc.parallelize(List(1, 2, 3, 5, 6))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[47] at parallelize at <console>:27
scala> rdd1.top(2)
res24: Array[Int] = Array(6, 5) 10、take操作:返回RDD中最小的k個元素
scala> rdd1.take(2)
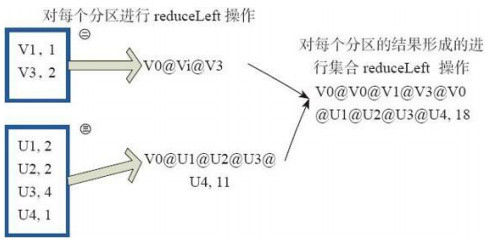
res25: Array[Int] = Array(1, 2)11、reduce操作:相當於對每個元素進行reduceLeft操作。
12、fold操作
13、aggregate操作:對每個分割槽的所有元素進行aggregate操作,再對分割槽的結果進行fold操作。aggregate採用歸併的方式進行資料聚集,是並行化的。 而在fold和reduce函式的運算過程中,每個分割槽中需要進行序列處理,每個分割槽序列計算完結果,結果再按之前的方式進行聚集,並返回最終聚集結果。