
kd樹(學習總結及虛擬碼)
阿新 • • 發佈:2019-02-10
kd樹是用來為求k臨近而建立的資料結構,查詢的平均複雜度是logN(和二叉樹很像)
kd樹的建立


這裡在建立kd樹的時候,這裡的演算法是迴圈依次採取各個維度來構建二叉樹,也有做法是選取資料在該維度上方差最大的那一維,因為方差大代表資料較分散,會有更好的解析度。
插入節點
insert(Point x, KDNode t, int cd) {
if t == null
t = new KDNode(x)
else if (x == t.data)
// error! duplicate
else if (x[cd] < t.data[cd])
t.left FindMin in kd-trees(尋找第k維最小的節點)
FindMin(d): find the point with the smallest value in the dth dimension.
虛擬碼:
Point findmin(Node T,int dim,int cd):
// empty tree
if T == NULL:return 刪除節點
當有右節點的時候:

當沒有右節點有左節點的時候:
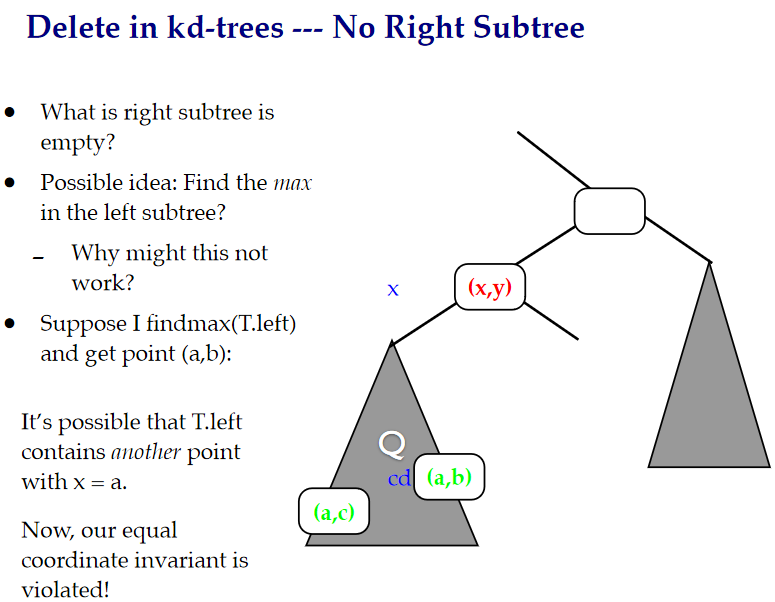
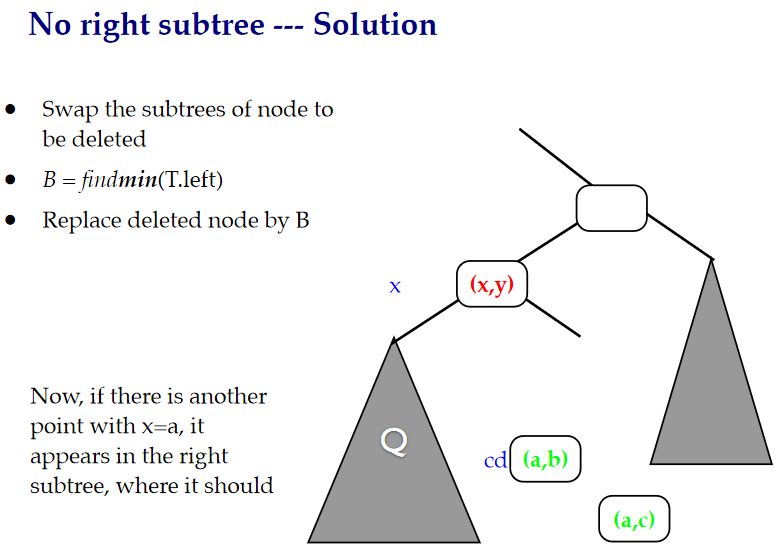
在這裡,找到最小的一個節點來替代刪除的節點,並將左節點變為右節點
當沒有位元組的時候直接設定為NULL返回
虛擬碼:
Point delete(Point x, Node T, int cd):
if T == NULL: error point not found!
next_cd = (cd+1)%DIM
// This is the point to delete:
if x = T.data:
// use min(cd) from right subtree:
if t.right != NULL:
t.data = findmin(T.right, cd, next_cd)
t.right = delete(t.data, t.right, next_cd)
// swap subtrees and use min(cd) from new right:
else if T.left != NULL:
t.data = findmin(T.left, cd, next_cd)
t.right = delete(t.data, t.left, next_cd)
t.left = null
else
t = null // we’re a leaf: just remove
// this is not the point, so search for it:
else if x[cd] < t.data[cd]:
t.left = delete(x, t.left, next_cd)
else
t.right = delete(x, t.right, next_cd)
return t查詢最近鄰節點
k-d樹最鄰近搜尋的過程如下:
- 從根節點開始,遞迴的往下移。往左還是往右的決定方法與插入元素的方法一樣(如果輸入點在分割槽面的左邊則進入左子節點,在右邊則進入右子節點)。
- 一旦移動到葉節點,將該節點當作”目前最佳點”。
- 解開遞迴,並對每個經過的節點執行下列步驟:
- 如果目前所在點比目前最佳點更靠近輸入點,則將其變為目前最佳點。
- 檢查另一邊子樹有沒有更近的點,如果有則從該節點往下找
- 當根節點搜尋完畢後完成最鄰近搜尋

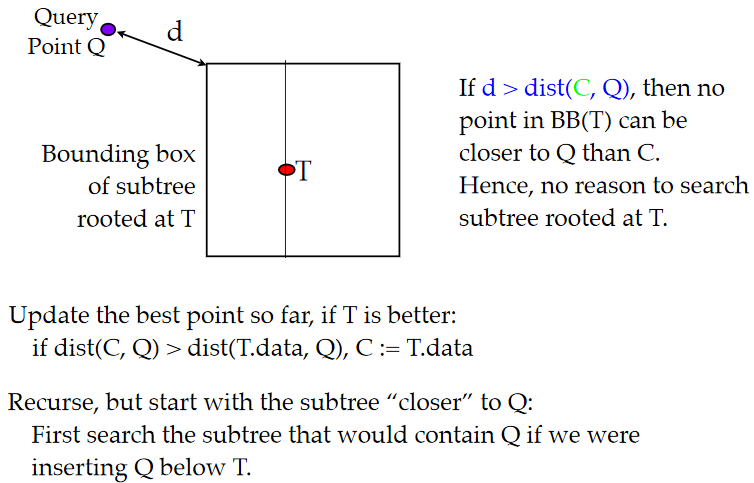
其實對kd樹的搜尋是一個剪枝問題,本來我們是要遍歷樹上所有的點的,但是噹噹前區域不可能有點比之前搜到的最小距離小的時候直接就剪枝不搜了。
怎麼求這個最小距離呢:
設max[i]為當前一些點第i維的最大值,min[i]為當前一些點第i維的最小值,point表示當前要找的點
double getdist():
dist = 0
for i = 0 to dim:
if point[i] < min[i]:
dist += (point[i] - min[i]) * (point[i] - min[i])
else if point[i] > max[i]:
dist += (point[i] - max[i]) * (point[i] - max[i])
return dist虛擬碼:
def NN(Point Q, kdTree T, int cd, Rect BB):
// if this bounding box is too far, do nothing
if T == NULL or distance(Q, BB) > best_dist: return
// if this point is better than the best:
dist = distance(Q, T.data)
if dist < best_dist:
best = T.data
best_dist = dist
// visit subtrees is most promising order:
if Q[cd] < T.data[cd]:
NN(Q, T.left, next_cd, BB.trimLeft(cd, t.data))
NN(Q, T.right, next_cd, BB.trimRight(cd, t.data))
else:
NN(Q, T.right, next_cd, BB.trimRight(cd, t.data))
NN(Q, T.left, next_cd, BB.trimLeft(cd, t.data))查詢K近鄰節點
這個查詢最近的k個節點的演算法是我自己想的,還有實驗驗證
在上面找最近鄰節點的時候判斷條件是當前搜尋區域不可能有節點比之前搜到的近的時候就剪枝:
if T == NULL or distance(Q, BB) > best_dist: return那麼我們在找最近的k個節點的時候做一下改變,首先用一個最大堆來儲存已經找到的k個節點,噹噹前區域不可能有節點比堆上最大的距離小的時候就剪枝:
我們用queue來表示這個堆
if T == NULL or distance(Q, BB) > queue.MAX: return //queue.MAX表示堆上的最大值那麼最後的虛擬碼是:
def NN(Point Q, kdTree T, int cd, Rect BB):
// if this bounding box is too far, do nothing
if T == NULL or distance(Q, BB) > queue.MAX: return //queue.MAX表示堆上的最大值
// if this point is better than the best:
dist = distance(Q, T.data)
if dist < queue.MAX:
queue.updata(dist,T.data);//用這個新找到的比較小的距離dist來更新這個最大堆
// visit subtrees is most promising order:
if Q[cd] < T.data[cd]:
NN(Q, T.left, next_cd, BB.trimLeft(cd, t.data))
NN(Q, T.right, next_cd, BB.trimRight(cd, t.data))
else:
NN(Q, T.right, next_cd, BB.trimRight(cd, t.data))
NN(Q, T.left, next_cd, BB.trimLeft(cd, t.data))