
關於C++ 中大小端和位域
宣告:由於本文的程式碼會受到計算機環境的影響,故在此說明本篇博文中的程式的執行環境。
1、Microsoft Windows 7 Ultimate Edition Service Pack 1 (64bit 6.1.7601)
2、Microsoft Visual Studio 2010 Version 10.0.40219.1 SP1Rel(Ultimate--ENU)。
3、Microsoft .NET Framework Version 4.0.30319 SP1Rel
4、Microsoft Visual C++ 2010
注:雖然系統是64位的,但是我是使用VC++ 2010預設配置,也即是x86平臺。所以下面所有示例和文字表述都是基於32位編譯平臺。
一、大小端
在現代“馮.諾依曼體系結構”計算機中,它的數制都是採用二進位制來儲存,並且是以8位,一個位元組為單位,產生記憶體地址系統。資料在記憶體中有如下三種存在方式:
1、從靜態儲存區分配:此時的記憶體在程式編譯的時候已經分配好,並且在程式的整個執行期間都存在。全域性變數,static變數等在此儲存。
2、在棧區分配:在程式的相關程式碼執行時建立,執行結束時被自動釋放。區域性變數在此儲存。棧記憶體分配運算內置於處理器的指令集中,效率
高,但容量有限。
3、在堆區分配:動態分配記憶體。用new/malloc時開闢,delete/free時釋放。變數的生存期由使用者指定,靈活,但會有記憶體洩露等問題。
對於像C++中的char這樣的資料型別,它本身就是佔用一個位元組的大小,不會產生什麼問題。但是當數制型別為int,在32bit的系統中,它需要佔用4個位元組(32bit),這個時候就會產生這4個位元組在暫存器中的存放順序的問題。比如int maxHeight = 0x12345678,&maxHeight = 0x0042ffc4。具體的該怎麼存放呢?這個時候就需要理解計算機的大小端的原理了。
大端:(Big-Endian)就是把數值的高位位元組放在記憶體的低位地址上,把數值的地位位元組放在記憶體的高位地址上。
小端:(Little-Endian)就是把數字的高位位元組放在高位的地址上,低位位元組放在低位地址上。
我們常用的x86結構都是小端模式,而大部分DSP,ARM也是小端模式,不過有些ARM是可以選擇大小端模式。所以對於上面的maxHeight是應該以小端模式來存放,具體情況請看下面兩表。
| 地址 | 0x0042ffc4 | 0x0042ffc5 | 0x0042ffc6 | 0x0042ffc7 |
|
數值 |
0x78 |
0x56 |
0x34 |
0x12 |
上圖為小端模式
| 地址 | 0x0042ffc4 | 0x0042ffc5 | 0x0042ffc6 | 0x0042ffc7 |
| 數值 |
0x12 |
0x34 |
0x56 |
0x78 |
上圖為大端模式
通過上面的表格,可以看出來大小端的不同,在這裡無法討論那種方式更好,個人覺得似乎大端模式更符合我的習慣。(注:在這裡我還要說一句,其實在計算機記憶體中並不存在所謂的資料型別,比如char,int等的。這個型別在程式碼中的作用就是讓編譯器知道每次應該從那個地址起始讀取多少位的資料,賦值給相應的變數。)
二、位段或位域
在前面已經提起過,在計算機中是採用二進位制0和1來表示資料的,每一個0或者1佔用1位(bit)儲存空間,8位組成一個位元組(byte),為計算機中資料型別的最小單位,如char在32bit系統中佔用一個位元組。但是正如我們知道的,有時候程式中的資料可能並不需要這麼的位元組,比如一個開關的狀態,只有開和關,用1和0分別替代就可以表示。此時開關的狀態只需要一位儲存空間就可以滿足要求。如果用一個位元組來儲存,顯然浪費了另外的7位儲存空間。所以在C語言中就有了位段(有的也叫位域,其實是一個東西)這個概念。具體的語法就是在變數名字後面,加上冒號(:)和指定的儲存空間的位數。具體的定義語法如下:
1: struct 位段名稱
2: {
3: 位段資料型別 位段變數名稱 : 位段長度,
4: .......
5: }
6:
7: 例項
8:
9: struct Node
10: {
11: char a:2;
12: double i;
13: int c:4;
14: }node;
其實定義很簡單,上面示例的意義是,定義一個char變數a,佔用2位儲存空間,一個double變數i,以及一個佔用4位儲存的int變數c。請注意這裡改變了變數本來佔用位元組的大小,並不是我們常規定義的一個int變數佔用4個位元組,一個char變數佔用1一個位元組。但是sizeof(node) = ?呢,在實際的執行環境中執行,得到sizeof(node) = 24;為什麼呢?說起來其實也很簡單,位元組對齊,什麼是位元組對齊,待會下一個段落會具體講解。先來看一個面試示例,程式碼如下:
1: #include <iostream>
2:
3: using namespace std;
4:
5: union
6: {
7: struct
8: {
9: char i:1;
10: char j:2;
11: char m:3;
12: }s;
13:
14: char ch;
15: }r;
16:
17: int _tmain(int argc, _TCHAR* argv[])
18: {
19: r.s.i = 1;
20: r.s.j = 2;
21: r.s.m = 3;
22:
23: cout<<" r.ch = "<<(int)r.ch<<" = 0x"<<hex<<(int)r.ch<<endl
24: <<" sizeof(r) = "<<sizeof(r)<<endl;
25:
26: return 0;
27: }
好了,具體結果是怎麼樣的呢?
r.ch = 29 = 0x1d
sizeof(r) = 1
為什麼是這個結果?說起來其實也很簡單,結合前面的大小端,可以具體來分析下,先看下錶:
|
m:3 |
j:2 |
i:1 |
|||||
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
0 |
0 |
0 |
1 |
1 |
1 |
0 |
1 |
|
1 |
D |
||||||
上面的表格,解釋了為什麼這裡等於29=0x1D。首先i、j、m分別佔用1、2、3位,分佈在一個位元組中。故根據賦值語句可知,在記憶體的相應的位元組上首先儲存i=1,然後儲存j=2,也即10,而後是m=3,也即011。可看上表的不同顏色所示,然後不足的位,補0來填充。所以整個位元組就是0x1D=29,顧r.ch = 29 = 0x1D。
關於位段,補充以下規則:
三、記憶體對齊
記憶體地址對齊,是一種在計算機記憶體中排列資料(表現為變數的地址)、訪問資料(表現為CPU讀取資料)的一種方式,包含了兩種相互獨立又相互關聯的部分:基本資料對齊和結構體資料對齊 。
為什麼需要記憶體對齊?對齊有什麼好處?是我們程式設計師來手動做記憶體對齊呢?還是編譯器在進行自動優化的時候完成這項工作?
在現代計算機體系中,每次讀寫記憶體中資料,都是按字(word,4個位元組,對於X86架構,系統是32位,資料匯流排和地址匯流排的寬度都是32位,所以最大的定址空間為232 = 4GB(也許有人會問,我的32位XP用不了4GB記憶體,關於這個不在本篇博文討論範圍),按A[31,30…2,1,0]這樣排列,但是請注意為了CPU每次讀寫4個位元組定址,A[0]和A[1]兩位是不參與定址計算的。)為一個快(chunks)來操作(而對於X64則是8個位元組為一個快)。注意,這裡說的CPU每次讀取的規則,並不是變數在記憶體中地址對齊規則。既然是這樣的,如果變數在記憶體中儲存的時候也按照這樣的對齊規則,就可以加快CPU讀寫記憶體的速度,當然也就提高了整個程式的效能,並且效能提升是客觀,雖然當今的CPU的處理資料速度(是指邏輯運算等,不包括取址)遠比記憶體訪問的速度快,程式的執行速度的瓶頸往往不是CPU的處理速度不夠,而是記憶體訪問的延遲,雖然當今CPU中加入了快取記憶體用來掩蓋記憶體訪問的延遲,但是如果高密集的記憶體訪問,一種延遲是無可避免的,記憶體地址對齊會給程式帶來了很大的效能提升。
記憶體地址對齊是計算機語言自動進行的,也即是編譯器所做的工作。但這不意味著我們程式設計師不需要做任何事情,因為如果我們能夠遵循某些規則,可以讓編譯器做得更好,比較編譯器不是萬能的。
為了更好理解上面的意思,這裡給出一個示例。在32位系統中,假如一個int變數在記憶體中的地址是0x00ff42c3,因為int是佔用4個位元組,所以它的尾地址應該是0x00ff42c6,這個時候CPU為了讀取這個int變數的值,就需要先後讀取兩個word大小的塊,分別是0x00ff42c0~0x00ff42c3和0x00ff42c4~0x00ff42c7,然後通過移位等一系列的操作來得到,在這個計算的過程中還有可能引起一些匯流排資料錯誤的。但是如果編譯器對變數地址進行了對齊,比如放在0x00ff42c0,CPU就只需要一次就可以讀取到,這樣的話就加快讀取效率。
在這裡給出三個個人認為講解比較好的網址,供大家參考,英語比較好的朋友,推薦閱讀。
1、基本資料對齊
在X86,32位系統下基於Microsoft、Borland和GNU的編譯器,有如下資料對齊規則:
a、一個char(佔用1-byte)變數以1-byte對齊。
b、一個short(佔用2-byte)變數以2-byte對齊。
c、一個int(佔用4-byte)變數以4-byte對齊。
d、一個long(佔用4-byte)變數以4-byte對齊。
e、一個float(佔用4-byte)變數以4-byte對齊。
f、一個double(佔用8-byte)變數以8-byte對齊(注:在Linux平臺下是4-byte對齊,超過4-byte都是以4-byte對齊)。
g、一個long double(佔用12-byte)變數以4-byte對齊。
h、任何pointer(佔用4-byte)變數以4-byte對齊。
而在64位系統下,與上面規則對比有如下不同:
a、一個long(佔用8-byte)變數以8-byte對齊。
b、一個double(佔用8-byte)變數以8-byte對齊。
c、一個long double(佔用16-byte)變數以16-byte對齊。
d、任何pointer(佔用8-byte)變數以8-byte對齊。
2、結構體資料對齊
結構體資料對齊,是指結構體內的各個資料對齊。在結構體中的第一個成員的首地址等於整個結構體的變數的首地址,而後的成員的地址隨著它宣告的順序和實際佔用的位元組數遞增。為了總的結構體大小對齊,會在結構體中插入一些沒有實際意思的字元來填充(padding)結構體。
1: #include <iostream>
2:
3: using namespace std;
4:
5: union
6: {
7: struct
8: {
9: char i:1;
10: char j:2;
11: char m:3;
12: }s;
13:
14: char ch;
15: }r;
16:
17: struct
18: {
19: char i;
20: double j;
21: int m;
22: }node;
23:
24: int _tmain(int argc, _TCHAR* argv[])
25: {
26: r.s.i = 1;
27: r.s.j = 2;
28: r.s.m = 3;
29:
30: node.i = 'm';
31: node.j = 3.1415926;
32: node.m = 100;
33:
34: cout<<" r.ch = "<<(int)r.ch<<" = 0x"<<hex<<(int)r.ch<<endl
35: <<" sizeof(r) = "<<sizeof(r)<<endl;
36:
37: cout.unsetf(ios::hex);
38:
39: cout<<" sizeof(node) = "<<sizeof(node)<<endl;
40:
41: system("PAUSE");
42:
43: return 0;
44: }
45:
執行結果截圖如下:
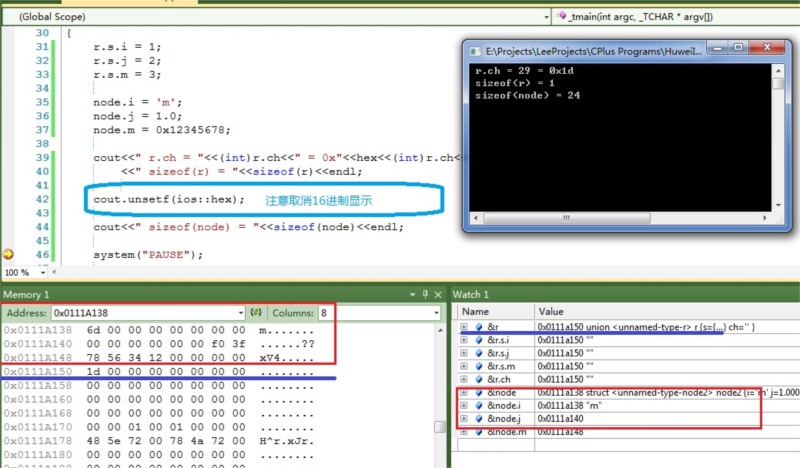
通過上面的執行截圖,可以得知,sizeof(r) = 1,sizeof(node)=24;首先看r儲存在首地址0x0111a150,node的首地址 為0x0111a138,這個符合先定義先分配空間,並且是從記憶體地址大到小的順序來分配空間。它們之間相差(0x0111a150-0x0111a138)=0x18=24byte(注意這裡是16進位制計算,借1當16,不是習慣性的當10)。而且通過每個成員的地址也知道,m和j之間隔8位元組,double是佔用8位元組,j和i之間也是8位元組,但是char只佔用了一個位元組,其餘相差的7個位元組使用0來填充。同樣int成員在後面的4個高位元組中也填充了0,以滿足8位元組對齊(前面4個位元組按小端高位元組高地址低位元組低地址存放)。同樣r只佔用0x0111a150這個位元組,值為0x1d=29。
在結構體中,成員資料對齊滿足以下規則:
a、結構體中的第一個成員的首地址也即是結構體變數的首地址。
b、結構體中的每一個成員的首地址相對於結構體的首地址的偏移量(offset)是該成員資料型別大小的整數倍。
c、結構體的總大小是對齊模數(對齊模數等於#pragma pack(n)所指定的n與結構體中最大資料型別的成員大小的最小值)的整數倍。
在看另外一個示例,來理解以上規則。
1: #include "stdafx.h"
2:
3: #include <iostream>
4:
5: using namespace std;
6:
7: struct
8: {
9: char a;
10: int b;
11: short c;
12: char d;
13: }dataAlign;
14:
15: struct
16: {
17: char a;
18: char d;
19: short c;
20: int b;
21:
22: }dataAlign2;
23:
24: int _tmain(int argc, _TCHAR* argv[])
25: {
26: dataAlign.a = 'A';
27: dataAlign.b = 0x12345678;
28: dataAlign.c = 0xABCD;
29: dataAlign.d = 'B';
30:
31: dataAlign2.a = 'A';
32: dataAlign2.b = 0x12345678;
33: dataAlign2.c = 0xABCD;
34: dataAlign2.d = 'B';
35:
36: cout<<" sizeof(dataAlign) = "<<sizeof(dataAlign)<<endl;
37: cout<<" sizeof(dataAlign2) = "<<sizeof(dataAlign2)<<endl;
38:
39: system("PAUSE");
40:
41: return 0;
42: }
執行結果截圖如下:
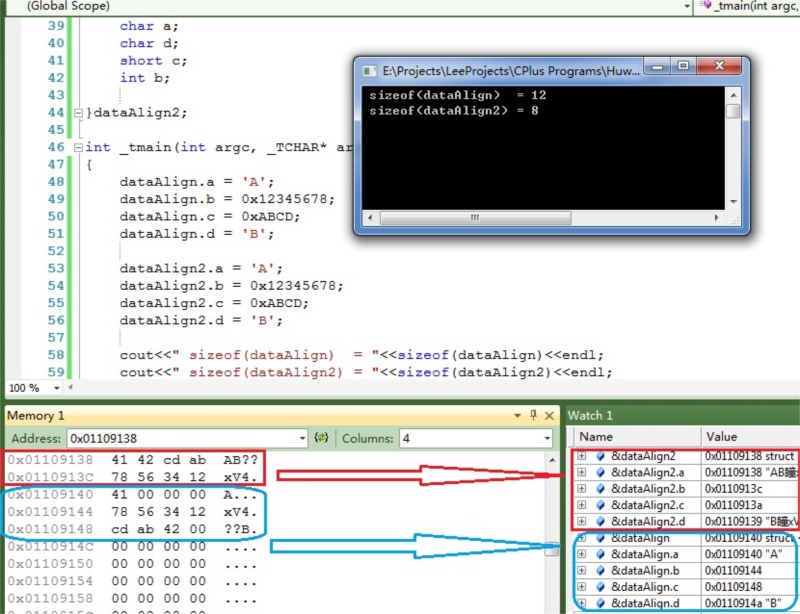
仔細觀察,會發現雖然是一樣的資料型別的成員,只不過宣告的順序不同,結構體佔用的大小也不同,一個8-byte一個12-byte。為什麼這樣,下面進行具體分析。
首先來看dataAlign2,第一個成員的地址等於結構體變數的首地址,第二個成員char型別,為了滿足規則b,它相對於結構體的首地址的偏移量必須是char=1的倍數,由於前面也是char,故不需要在第一個和第一個成員之間填充,直接滿足條件。第三個成員short=2如果要滿足規則b,也不需要填充,因為它的偏移量已經是2。同樣第四個也因為偏移量int=4,不需要填充,這樣結構體總共大小為8-byte。最後來驗證規則c,在VC中預設的#pragma pack(n)中的n=8,而結構體中資料型別大小最大的為第四個成員int=4,故對齊模數為4,並且8 mode 4 = 0,所以滿足規則c。這樣整個結構體的總大小為8。結合上面執行結果截圖的紅色框,可以驗證。
對於dataAlign,第一個成員等於結構體變數首地址,偏移量為0,第二個成員為int=4,為了滿足規則b,需要在第一個成員之後填充3-byte,讓它相對於結構體首地址偏移量為4,結合執行結果截圖,可知&dataAlign.a = 0x01109140,而&dataAlign.b = 0x01109144,它們之間相隔4-byte,0x01109141~0x01109143三個位元組被0填充。第三個成員short=2,無需填充滿足規則b。第四個成員char=1,也不需要填充。OK,結構體總大小相加4 + 4 + 2 + 1 = 11。同樣最後需要驗證規則c,結構體中資料型別大小最大為第二個成員int=4,比VC預設對齊模數8小,故這個結構體的對齊模數仍然為4,顯然11 mode 4 != 0,故為了滿足規則c,需要在char後面填充一個位元組,這樣結構體變數dataAlign的總大小為4 + 4 + 2 + 2 = 12。
好了,再來看看位段(也叫位域)這種資料型別在記憶體中的對齊。一個位域必須儲存在同一個位元組中,不能跨位元組,比如跨兩個位元組。如果一個位元組所剩空間不夠儲存另一位位域時,應該從下一個位元組存放該位域。在滿足成員資料對齊的規則下,還滿足如下規則:
d、如果相鄰位域型別相同,並且它倆位域寬度之和小於它的資料型別大小,則後面的欄位緊鄰前面的欄位儲存。
e、如果相鄰位域型別相同,但是它倆位域寬度之和大於它的資料型別大小,則後面的欄位將從新的儲存單元開始,其偏移量為其型別的整數倍。
f、如果相鄰位域型別不同,在VC中是不採取壓縮方式,但是GCC會採取壓縮方式。
具體的結合下面示例來理解,具體程式碼為:
1: #include <iostream>
2:
3: using namespace std;
4:
5: struct
6: {
7: char a:4;
8: int b:6;
9: }bitChar2;
10:
11: struct
12: {
13: char a:3;
14: char b:3;
15: char c:7;
16: double d;
17: int e:4;
18: int f:30;
19: }bitChar;
20:
21: int _tmain(int argc, _TCHAR* argv[])
22: {
23: bitChar2.a = 7;
24: bitChar2.b = 32;
25: cout<<" sizeof(bitChar2) = "<<sizeof(bitChar2)<<endl;
26:
27: bitChar.a = 6;
28: bitChar.b = 4;
29: bitChar.c = 45;
30: bitChar.d = 100.0;
31: bitChar.e = 7;
32: bitChar.f = 0x12345678;
33: cout<<"sizeof(bitChar) = "<<sizeof(bitChar)<<endl;
34:
35: system("PAUSE");
36: return 0;
37: }
執行結果截圖如下:
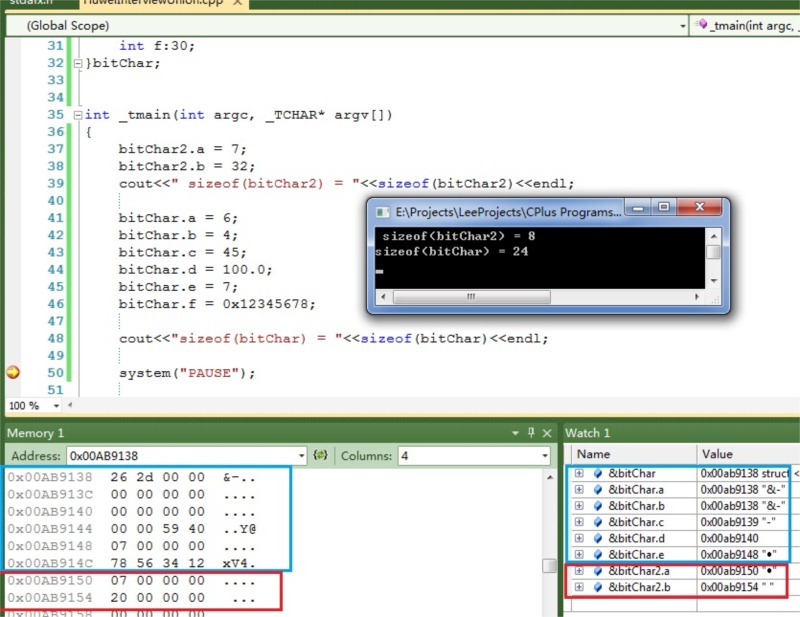
首先來分析bitChar2,因為滿足規則f,在VC下不壓縮,同時要滿足規則a、b、c。所以第二個成員需要最低偏移量為4,第一個成員後需要填充3-byte。再看第二個bitChar,首先成員a、b滿足規則d,故需要填充在0x00ab9138這個位元組內,具體儲存順序見下圖:
|
b:3 |
a:3 |
||||||
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
0 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
|
2 |
6 |
||||||
而第二個成員和第三個成員滿足規則e,位域之和大於sizeof(char)=1的大小,所以需要一個偏移量。而第四個成員double=8為了滿足規則b,必須在第三個成員之後填充6-byte,滿足最小偏移量8。第五個成員不需要偏移,故無需填充。而第六個成員和第五個成員滿足規則e,所以需要從新的儲存單元開始儲存,偏移量為int=4的整數倍,然後儲存最後的成員e,中間需要填充3-byte。
由此可以得出總的大小為1 + 1 + 6 + 8 + 4 + 4 = 24,滿足規則c,即是24 mode 8 = 0。
四,關於#pragma pack(n)
#pragma pack(push) //儲存對齊狀態
#pragma pack(n) /設定對齊模數(選擇n和一般情況下選出來的模數的較小者做對齊模數)
#pragma pack(pop) //恢復對齊狀態