
大資料平臺搭建------CDH單機部署
從 17年十一月入職起,到中間經歷了畢業、春節、轉正。在工作崗位上學到了很多很多的東西,非常有幸遇到這麼一群人生導師,早就想把工作中趟過的坑,總結的文件,開個部落格記錄起來,一來可以給其他人蔘考,二來也是自己的一個複習吧。可是拖延症作祟,這事,一直耽擱,爭取以後每週至少總結兩篇。加油,未來的路很長!
----------------------------------------------------我是分割線-----------------------------------------------------------------
一、部署前的準備
1、檢查jdk是否安裝:參考jdk安裝配置文件(jdk7或jdk8,所有節點都要一致)
2、相容性建議:CentOS6.8+CDH5.11.x(x>1)+mysql5.x+jdk1.7u80
***CDH5.13以上包含kafka3.0,不支援jdk1.7***
***CDH不支援ipv6,需提前關閉***
二、線上安裝
(不推薦,安裝慢,失敗率高,原因你懂得)
參考文件:
1、下載CDH5的包,放在linux系統中,下載連結:
2、使用rpm安裝
$ sudo yum --nogpgcheck localinstall cloudera-cdh-5-0.x86_64.rpm |
3、(可選)將Cloudera公鑰新增到庫中
$ sudo rpm --import https://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera |
4、安裝偽分散式hadoop
MRv1 | $ sudo yum install hadoop-0.20-conf-pseudo |
YARN | sudo yum install hadoop-conf-pseudo |
5、啟動Hadoop並且驗證其是否工作正常
MRv1 | $ rpm -ql hadoop-0.20-conf-pseudo |
YARN | $ rpm -ql hadoop-conf-pseudo |
6、格式化NameNode
$ sudo -u hdfs hdfs namenode -format |
7、啟動HDFS,通過http://localhost:50070/來檢查是否正常啟動
for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done |
8、建立Hadoop程序所需的目錄
$ sudo /usr/lib/hadoop/libexec/init-hdfs.sh |
9、驗證HDFS檔案結構
sudo -u hdfs hadoop fs -ls -R / |
10、啟動MapReduce/YARN
MRv1 | for x in `cd /etc/init.d ; ls hadoop-0.20-mapreduce-*` ; do sudo service $x start ; done |
YARN | $ sudo service hadoop-yarn-resourcemanager start $ sudo service hadoop-yarn-nodemanager start $ sudo service hadoop-mapreduce-historyserver start |
11、在namenode建立使用者目錄
$ sudo -u hdfs hadoop fs -mkdir -p /user/<user> $ sudo -u hdfs hadoop fs -chown <user> /user/<user> |
12、啟動MapReduce例子
MRv1 | 建立執行目錄 | sudo -u hdfs hadoop fs -mkdir -p /user/joe sudo -u hdfs hadoop fs -chown joe /user/joe |
建立輸入目錄並拷貝xml檔案準備測試 | $ hadoop fs -mkdir input $ hadoop fs -put /etc/hadoop/conf/*.xml input $ hadoop fs -ls input | |
執行hadoop示例 | $ /usr/bin/hadoop jar /usr/lib/hadoop-0.20-mapreduce/hadoop-examples.jar grep input output 'dfs[a-z.]+' | |
檢視輸出 | $ hadoop fs -ls output | |
YARN | 建立執行目錄 | sudo -u hdfs hadoop fs -mkdir -p /user/joe sudo -u hdfs hadoop fs -chown joe /user/joe |
建立輸入目錄並拷貝xml檔案準備測試 | $ hadoop fs -mkdir input $ hadoop fs -put /etc/hadoop/conf/*.xml input $ hadoop fs -ls input | |
設定環境變數 | $ export HADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce | |
執行hadoop示例 | $ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar grep input output23 'dfs[a-z.]+' | |
檢視輸出 | $ hadoop fs -ls output23 |
三、離線安裝
參考文件:
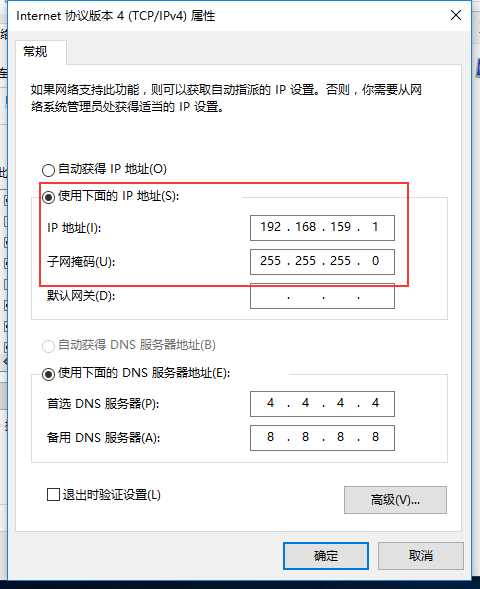
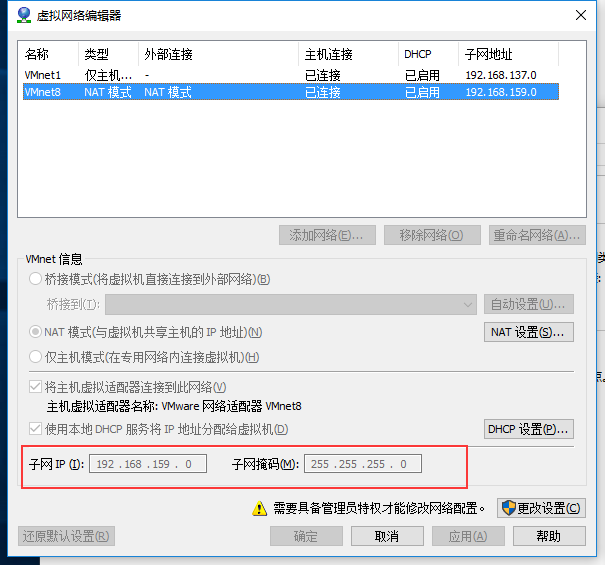
1、配置靜態IP(vmware的nat模式下)
(1)修改自己電腦的虛擬網絡卡VMware Network Adapter VMnet8——屬性——IPv4屬性設定靜態IP(此處設定的靜態IP要對應與VMware的虛擬網路編輯器中VMnet8的子網IP)
(2)、修改虛擬機器的IP
新增閘道器 | vi /etc/sysconfig/network GATEWAY=192.168.159.2(同虛擬網路編輯器中的nat設定中地址) |
修改ip、子網掩碼 | vi /etc/sysconfig/network-scripts/ifcfg-eth0 IPADDR=192.168.159.10(最後一位自選10-255) NETMASK=255.255.255.0 |
重啟網絡卡 | service network restart或ifdown eth0;ifup eth0 |
*****************************問題*****************************
我們會克隆虛擬機器,克隆的機子沒有顯示網絡卡eth0,取而代之的是網絡卡 eth1
在原型機上找原型機的mac地址 | vim /etc/udev/rules.d/70-persistent-net.rules(原型機上執行) |
對比新機上的mac地址 | vim /etc/udev/rules.d/70-persistent-net.rules(新機上執行) |
發現新機上多個eth0和一個eth1,eth1是新機真實的mac地址,刪除多餘eth0,將eth1改成eth0,記錄下真實mac地址 | |
重啟網絡卡和機器 | service network restart reboot |
2、下載Hadoop與CDH對應版本,這裡選hadoop-2.6.0-cdh5.11.1.tar.gz
解壓到/home/hadoop下
tar -zxvf hadoop-2.6.0-cdh5.11.1.tar.gz -C /home/hadoop |
3、關閉防火牆
service iptables stop service ip6tables stop |
4、配置全域性環境變數(追加)
vi /etc/profile |
JAVA_HOME=/opt/jdk1.7.0_80 PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:HADOOP_HOME/sbin CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export HADOOP_HOME=/home/hadoop export JAVA_HOME export PATH export CLASSPATH |
source /etc/profile |
5、配置本機免密碼登入本機
ssh-keygen -t rsa cat id_rsa.pub >> authorized_keys |
6、配置hadoop_env.sh(追加)
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh |
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.45.x86_64 export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native" |
7、配置core-site.xml(追加在configuration裡)
vim $HADOOP_HOME/etc/hadoop/core-site.xml |
<property> <name>fs.defaultFS</name> <value>hdfs://localhost</value> </property> |
8、配置hdfs-site.xml(追加在configuration裡)
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml |
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/hdfs</value> </property> <property> <name>dfs.namenode.http-address</name> <value>localhost:50070</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>localhost:50090</value> </property> |
9、配置yarn-site.xml(追加在configuration裡)
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml |
<property> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> |
10、配置slaves,如果已存在該檔案,且裡面是localhost,則不用修改,否則修改為localhost
vim $HADOOP_HOME/etc/hadoop/slave |
遇到得問題:
1、host檔案未修改
2、hadoop_env.sh漏掉了一個$符
3、忘了配置虛擬機器的dns伺服器,導致兩臺不能訪問外網
3、yarn-site.xml粘貼出錯
4、WARN util.NativeCodeLoader: Unable to load native-hadoop library foryour platform... using builtin-java classes where applicable