
假期跟我一起寫一個點對點VPN-SimpleVPN詳解
阿新 • • 發佈:2019-02-10
自從上週寫了幾篇關於BadVPN的文章後,收到很多的郵件前來詢問細節。其中最多的不外乎兩類,一類是詢問怎麼使用的,另一類則是要求我寫幾篇原始碼分析。先來一個一個說。
所以關於BadVPN的用法,我不想過多的說,只要你能先把BadVPN跑起來,那麼後面的就不屬於BadVPN的範疇了。如果你不懂IP路由,那麼這是另外一個話題。
一直存在關於各種SSLVPN與IPSec VPN區別和聯絡的討論,自然,很多人會把OpenVPN這種“使用SSL協議的VPN”叫做SSLVPN,誠然,BadVPN並沒有OpenVPN那麼出名,很多人都不知道,而OpenVPN卻是業內眾所周知的,曾經有一本書叫做《OpenVPN and the SSL VPN Revolution》就是宣傳OpenVPN的,另外,除了OpenVPN,來自日本的SoftEther也曾經大紅一時,作者還被採訪,從其描述中得知,這也是VPN的一次Revolution...不管怎麼樣,OpenVPN也好,SoftEhter也罷,都是針對傳統的IPSec VPN的,革的是IPSec VPN的命,類似這種IPSec VPN由於廠商獨斷,配置複雜,且NAT穿越問題而飽受詬病,所以世界這麼大,總是會有人跳出來提一個全新的方案,這並不足以為奇。而且這些所謂的新方案無一沒有使用SSL協議,這就給人造成了一種假象,這些都是SSLVPN!使用了SSL的VPN就一定是SSLVPN嗎?
其實根本就不是!SSL只是這種VPN使用的工具集裡一個套件,不用SSL,還是可以用別的方式構建安全的控制通道,比如大多數簡單環境下,直接用DH寫上金鑰我就覺得沒什麼不好。另外,也很少有人直接用SSL記錄協議去封裝資料流,畢竟SSL(統稱,包括TLS,DTLS...)記錄協議太重了,它便於封裝能感知的業務資料比如HTTPS,而不是透明地封裝裸資料。需求決定方法,VPN難道不就只是為了讓資料進行加密傳輸嗎(together with認證)?所以使用SSL只是為了構建一個安全通道而已,在這個安全通道里去協商資料通道的對稱金鑰,如果你理解了這,那麼SSL顯然其分量就沒有那麼重了。
當然我是站在中立的立場上來說這件事,如果對於偏網路的公司,比如Cisco,華為,他們可能傾向於將SSL作為元件結合到VPN中,而對於安全類公司,比如格爾軟體,他們可能會將SSL立足為根本,但在中立者看來,討論這個問題毫無意義,取向取決於公司的基礎投資,這永遠都是個案問題,沒有普適的答案。
那麼BadVPN又是什麼?它出自誰之手?這裡有一個連結:
當有人問“Why is it called badvpn?”時,作者如是說:
No particular reason really, I just needed a name that sounded deviant - I was still a teen back then! Over time I added other software to the repo for convenience (tun2socks, NCD). A name change might in fact be due.
如今,作者已經長大了吧。這個專案並沒有大紅大紫過,可能是沒有資金的支撐,但根本的原因我覺得還是宣傳的不到位,如果宣傳到位了,那麼自然會有資金到來的,但這一切並不妨礙BadVPN的優秀。作為VPN的鼓手,我願意為之宣傳。
------------------------
本著我的基本原則,不管好不好,先跑起來再說。趁著五一假期有點時間,我決定寫一個點對點的VPN框架出來,一方面是為了給大家解釋BadVPN的程式碼構成,另一方面是為了自己練習一下程式設計。我雖然不會程式設計,但也不是一點也不會,我稍微會一點。
本文中的VPN程式碼我儘量做到簡單再簡單,但這並不妨礙理解其技術本質,我們知道,github上有一個
1.向其它所有的已註冊節點通知,新節點註冊了;
2.告訴新節點都有哪些節點已經註冊。
經常聊QQ的再也熟悉不過這個場景了,如果我們剛剛登入QQ,一個線上使用者列表便馬上刷新出來,告訴新登入的自己誰線上,另外如果我們已經線上,那麼一旦有人登入,伴隨著一聲咳嗽,那人就顯示線上了。VPN的伺服器所要做的,無無外乎也就是上面的兩點。
再看VPN節點的邏輯,其實也不難,就把自己當成QQ客戶端吧,當你登入後,你就可以跟任何好友進行聊天了,你和好友傳送的訊息不需要經過中間伺服器中轉,而是直達你好友機器的。對於VPN節點也一樣,註冊後會收到伺服器推送下來的線上VPN節點的列表,每一個表項都包括足夠豐富的資訊,比如IP地址,埠,金鑰協商引數什麼的,只要VPN節點儲存下來這些,那麼就可以直接和感興趣的節點進行直接VPN通訊了。
在節點已經登入的期間,如果有其它新節點登入,該節點會收到新節點登入的訊息。所以說VPN節點與伺服器的互動中最重要的事只有一件,那就是接收服務端隨時推送的“線上使用者列表”,然後生成或者更新自己本地的鄰居表並維護它。當真的需要通訊的時候,那就相當於你已經知道源和目標,求如何通訊的問題了,Socket程式設計總會吧,如果會的話,用TLS/DTLS也不難吧。
這就是全部嗎?是的,這就是全部。
在本文中,我沒有使用任何的複雜通用加密演算法,只是用了普通的低階凱撒加密,即加密時將每一個位元組二進位制加1,解密時每一個位元組二進位制減1,僅此而已。原則上,你將此替換為OpenSSL的EVP系列呼叫實現真正的加解密,也是不難的。詳情參考OpenVPN是怎麼做的。
好了,以上就是服務端程式碼了。當然,我可能遺忘了Linux核心list_head移植部分的講解,也沒有select/poll/epoll的優劣比較,不過我覺得,把這些寫全不利於理解主要問題。我會把本文的全部程式碼編譯可執行後放入github,歡迎直接前往嘲笑拍磚。
注意,frame最前面是兩個16bit的ID頭欄位,為什麼要用到它呢?既然已經知道資料發給誰了,封裝這個ID的意義又何在呢?SimpleVPN只是一個及其簡單的Demo,實際上,為了支援組播,這個ID欄位是必要的,我們把ID看作是組標識也是可以的。
這個結構體表現了VPN處理的核心機制。一般而言,當VPN拿到裸資料後,到將其發出前,需要一系列的操作,比如先加密/摘要,然後封裝協議頭,最後傳送,反過來當收到
網路資料後,要執行解除協議頭,解密/驗證摘要等反向的操作,所以我將它們成對組織起來:
所有以上的結構體之間的關係如下:
接下來就很簡單了,定義幾個process_handler結構體以及回撥即可,比如下面的一對:
程式碼就不解釋了,太簡單。我下面註釋一對比較複雜的handler邏輯。
--------------------------------------------------
當從TAP收到幀之後,要根據其MAC地址找到對應的鄰居,這個查詢過程和交換機的查詢過程非常類似,基本就是下面的邏輯:
如果反過來,資料從Socket收到,那麼就會經歷一個MAC學習的過程,這個和交換機也是類似的:
最後,將上述的邏輯插入到一個處理模組routing_handler裡即可:
其它的處理就不多說了,如果你想用TLS/DTLS或者用DH演算法協商出來的金鑰進行加密,那麼再寫一個process_handler即可。我接下啦展示一下一個處理模組是如何註冊到系統的,其實也很簡單,就是一堆連結串列操作:
最後,我們來看看總體的邏輯,即main函式:
好了,以上就是核心的程式碼分析。全部的程式碼在github上:https://github.com/marywangran/SimpleVPN/
編譯服務端:gcc CtrlCenter.c
執行服務端:./a.out 192.168.44.100 7000
編譯VPN節點:gcc SimpleVPN.c
執行VPN節點:
機器1上執行:
tunctl -u root -t tap0
ifconfig tap0 10.10.10.129/24
./a.out 192.168.44.100 7000 1.1.1.1 100
機器2上執行:
tunctl -u root -t tap0
ifconfig tap0 10.10.10.131/24
./a.out 192.168.44.100 7000 1.1.1.3 100
然後在機器1上ping機器2的tap0地址。
明明已經有了TCP和UDP,還要再設計一個新的四層協議,這會造成損失。還記得VXLAN和NVGRE的區別嗎?VXLAN使用了通用的UDP來封裝,而NVGRE則沒有,這就是的NVGRE幾乎不能適配基於UDP元組的負載均衡。仔細想想OpenVPN,幸虧它採用了UDP封裝...它可以無縫適配Linux自帶的reuseport機制來簡單負載均衡,不然負載均衡都得自己寫。我記得最初的負載均衡是我在IP層用nf_conntrack來做的,其實我之所以用nf_conntrack來做,那是因為那時我並不知道reuseport...如果沒有reuseport,然後你還不懂nf_conntrack,那就得花費大量的精力去優化OpenVPN服務端的負載均衡或者多處理。
在網路虛擬化方面,其中也包括一些VPN技術,很多廠商都在做這塊,我們來看看如今他們分屬的陣營,我大致將它們分為網路陣營和軟體陣營,我比較傾向於網路陣營。
我大致分下類,VXLAN,VN-TAG,IPSec,這些倡導者都屬於網路陣營,比如Cisco,IETF,而像NVGRE,VEPA,SSL這種,基本都是軟體陣營,比如倡導者是微軟,HP之流,然而我們發現,這兩個陣營誰也壓不倒誰,在VXLAN和NVGRE的PK中,網路陣營完勝,但在VN-TAG和VEPA的較量中,網路陣營又輸的比較慘淡...Why?
是該聯合起來的時候了。我們發現,贏的那一方一定是便宜的那一方,一定是簡單的那一方。所以我一向提倡炫技者止步的意義就在於此。同軸電纜複雜吧,輸給了簡單便宜的雙絞線,魏國武卒昂貴吧,卻輸給了秦國農民軍...
快到中午了,令人遺憾的五一勞動節...
1.關於BadVPN的使用問題
和OpenVPN相反,BadVPN幾乎沒有除了配置隧道之外的任何東西,這些被排除了內容中最重要的應該就是路由了。OpenVPN中就有關於路由的很多配置,還可以從服務端往客戶端推送路由,這簡直太方便了,但同時也增加了配置的複雜性。BadVPN我認為是比較好的方式,它本身沒有關於路由的任何配置,只要你把隧道搭建好,路由就找熟悉路由的人配置吧,讓專業的人做專業的事。所以關於BadVPN的用法,我不想過多的說,只要你能先把BadVPN跑起來,那麼後面的就不屬於BadVPN的範疇了。如果你不懂IP路由,那麼這是另外一個話題。
2.關於原始碼分析
說實話,我是不喜歡用原始碼分析的方式去熟悉一個技術的。如果你已經理解了原理,何必不自己試著寫一個呢?本文就是針對這一點來寫的。趁著五一假期,花點時間盲寫了一個VPN框架,所謂盲寫就是這個VPN沒有基於任何其它的程式碼修改,都是自己寫的,像我這種程式設計編的不好人,能寫出個這樣的程式碼,我已經很知足了。一直存在關於各種SSLVPN與IPSec VPN區別和聯絡的討論,自然,很多人會把OpenVPN這種“使用SSL協議的VPN”叫做SSLVPN,誠然,BadVPN並沒有OpenVPN那麼出名,很多人都不知道,而OpenVPN卻是業內眾所周知的,曾經有一本書叫做《OpenVPN and the SSL VPN Revolution》就是宣傳OpenVPN的,另外,除了OpenVPN,來自日本的SoftEther也曾經大紅一時,作者還被採訪,從其描述中得知,這也是VPN的一次Revolution...不管怎麼樣,OpenVPN也好,SoftEhter也罷,都是針對傳統的IPSec VPN的,革的是IPSec VPN的命,類似這種IPSec VPN由於廠商獨斷,配置複雜,且NAT穿越問題而飽受詬病,所以世界這麼大,總是會有人跳出來提一個全新的方案,這並不足以為奇。而且這些所謂的新方案無一沒有使用SSL協議,這就給人造成了一種假象,這些都是SSLVPN!使用了SSL的VPN就一定是SSLVPN嗎?
其實根本就不是!SSL只是這種VPN使用的工具集裡一個套件,不用SSL,還是可以用別的方式構建安全的控制通道,比如大多數簡單環境下,直接用DH寫上金鑰我就覺得沒什麼不好。另外,也很少有人直接用SSL記錄協議去封裝資料流,畢竟SSL(統稱,包括TLS,DTLS...)記錄協議太重了,它便於封裝能感知的業務資料比如HTTPS,而不是透明地封裝裸資料。需求決定方法,VPN難道不就只是為了讓資料進行加密傳輸嗎(together with認證)?所以使用SSL只是為了構建一個安全通道而已,在這個安全通道里去協商資料通道的對稱金鑰,如果你理解了這,那麼SSL顯然其分量就沒有那麼重了。
當然我是站在中立的立場上來說這件事,如果對於偏網路的公司,比如Cisco,華為,他們可能傾向於將SSL作為元件結合到VPN中,而對於安全類公司,比如格爾軟體,他們可能會將SSL立足為根本,但在中立者看來,討論這個問題毫無意義,取向取決於公司的基礎投資,這永遠都是個案問題,沒有普適的答案。
那麼BadVPN又是什麼?它出自誰之手?這裡有一個連結:
當有人問“Why is it called badvpn?”時,作者如是說:
No particular reason really, I just needed a name that sounded deviant - I was still a teen back then! Over time I added other software to the repo for convenience (tun2socks, NCD). A name change might in fact be due.
如今,作者已經長大了吧。這個專案並沒有大紅大紫過,可能是沒有資金的支撐,但根本的原因我覺得還是宣傳的不到位,如果宣傳到位了,那麼自然會有資金到來的,但這一切並不妨礙BadVPN的優秀。作為VPN的鼓手,我願意為之宣傳。
------------------------
前言
好久都沒有程式設計了,我從來都覺得自己根本就不會程式設計,心裡有邏輯細節,就是寫不出來。我想寫一個小程式來闡述BadVPN及其它點對點VPN的技術原理,但我怕自己寫出來的東西是垃圾,所以就一直都沒有敢寫,我想深入學習一下設計模式,學習一下Java的最新特性,然後再寫...但是那恐怕會很久,也許就再也沒有機會寫了。本著我的基本原則,不管好不好,先跑起來再說。趁著五一假期有點時間,我決定寫一個點對點的VPN框架出來,一方面是為了給大家解釋BadVPN的程式碼構成,另一方面是為了自己練習一下程式設計。我雖然不會程式設計,但也不是一點也不會,我稍微會一點。
本文中的VPN程式碼我儘量做到簡單再簡單,但這並不妨礙理解其技術本質,我們知道,github上有一個
結構總覽
SimpleVPN是一個點對點VPN框架,它非常類似於一種聊天軟體的設計,所有的VPN節點,類似聊天客戶端在啟動的時候先向一箇中心的伺服器去註冊,然後伺服器收到註冊訊息後做兩件事:1.向其它所有的已註冊節點通知,新節點註冊了;
2.告訴新節點都有哪些節點已經註冊。
經常聊QQ的再也熟悉不過這個場景了,如果我們剛剛登入QQ,一個線上使用者列表便馬上刷新出來,告訴新登入的自己誰線上,另外如果我們已經線上,那麼一旦有人登入,伴隨著一聲咳嗽,那人就顯示線上了。VPN的伺服器所要做的,無無外乎也就是上面的兩點。
再看VPN節點的邏輯,其實也不難,就把自己當成QQ客戶端吧,當你登入後,你就可以跟任何好友進行聊天了,你和好友傳送的訊息不需要經過中間伺服器中轉,而是直達你好友機器的。對於VPN節點也一樣,註冊後會收到伺服器推送下來的線上VPN節點的列表,每一個表項都包括足夠豐富的資訊,比如IP地址,埠,金鑰協商引數什麼的,只要VPN節點儲存下來這些,那麼就可以直接和感興趣的節點進行直接VPN通訊了。
在節點已經登入的期間,如果有其它新節點登入,該節點會收到新節點登入的訊息。所以說VPN節點與伺服器的互動中最重要的事只有一件,那就是接收服務端隨時推送的“線上使用者列表”,然後生成或者更新自己本地的鄰居表並維護它。當真的需要通訊的時候,那就相當於你已經知道源和目標,求如何通訊的問題了,Socket程式設計總會吧,如果會的話,用TLS/DTLS也不難吧。
這就是全部嗎?是的,這就是全部。
在本文中,我沒有使用任何的複雜通用加密演算法,只是用了普通的低階凱撒加密,即加密時將每一個位元組二進位制加1,解密時每一個位元組二進位制減1,僅此而已。原則上,你將此替換為OpenSSL的EVP系列呼叫實現真正的加解密,也是不難的。詳情參考OpenVPN是怎麼做的。
服務端程式碼
先看資料結構
1.可以代表一個VPN節點的元組
struct tuple {
char addr[16]; // 建立VPN通道的IP地址,可以向其傳送VPN資料
unsigned short port; // 建立VPN通道的埠
unsigned short id; // VPN節點的唯一ID號
unsigned short unused; // 為了主機內資料對齊,未用,但是卻增加網路的開銷
} __attribute__((packed));2.服務端回覆的資訊頭部
struct ctrl_header {
unsigned short sid; // 固定為0
unsigned short did; // 回覆到的VPN節點的ID標識
unsigned short num; // 一次通告中,一共包含多少鄰居節點
unsigned short unused; // 未使用
} __attribute__((packed));3.服務端傳送到VPN節點的鄰居表
struct control_frame {
struct ctrl_header header;
struct tuple tuple[0]; // 所有的要通告的鄰居節點
} __attribute__((packed));4.表示一個VPN節點的物件結構體
struct client {
struct list_head list; // 所有的VPN節點會連結在一起
struct tuple tuple; // 該節點的元組資訊
int fd; // 儲存與改VPN節點通話的檔案描述符資訊
void *others; // 其它資訊,盡情發揮。但肯定與TLS/DTLS有關
};5.全域性的配置資訊
struct config {
int listen_fd; // 偵聽套接字
struct list_head clients; // 儲存所有的已經登入的VPN節點
unsigned short tot_num; // 已經登入的VPN節點數目
};再看服務端處理的原始碼
資料結構都明白了,原始碼自己也可以盲寫,非常簡單。int client_msg_process(int fd, struct config *conf)
{
int ret = 0;
int i = 0;
size_t len = 0;
struct client *peer;
struct sockaddr_in addr;
char *saddr;
int port;
int addr_len = sizeof(struct sockaddr_in);
struct ctrl_header aheader = {0};
struct tuple newclient;
struct tuple *peers;
struct tuple *peers_base;
struct list_head *tmp;
bzero (&addr, sizeof(addr));
len = recv(fd, &newclient, sizeof(newclient), 0);
peer = (struct client *)calloc(1, sizeof(struct client));
if (!peer) {
return -1;
}
memcpy(peer->tuple.addr, &newclient.addr, sizeof(struct tuple));
peer->tuple.port = newclient.port;
peer->fd = fd;
INIT_LIST_HEAD(&peer->list);
aheader.sid = 0;
aheader.num = 0;
peers_base = peers = (struct tuple*)calloc(conf->tot_num, sizeof(struct tuple));
// 這個ID分配,著實不用這個醜陋的機制,用bitmap是我的最愛,或者雜湊!
peer->tuple.id = conf->tot_num+1;
aheader.did = peer->tuple.id;
conf->tot_num ++;
// 以下for迴圈有兩個作用:1.將新登入節點知會所有已登入節點;2.蒐集已登入節點資訊,準備知會新登入節點
list_for_each(tmp, &conf->clients) {
struct ctrl_header header = {0};
struct client *tmp_client = list_entry(tmp, struct client, list);
header.sid = 0;
header.did = tmp_client->tuple.id;
newclient.id = aheader.did;
header.num = 1;
send(tmp_client->fd, &header, sizeof(struct ctrl_header), 0);
send(tmp_client->fd, &newclient, sizeof(struct tuple), 0);
aheader.num += 1;
memcpy(peers->addr, tmp_client->tuple.addr, 16);
peers->port = tmp_client->tuple.port;
peers->id = tmp_client->tuple.id;
peers++;
}
// 傳送給VPN節點頭部訊息
send(peer->fd, (const void *)&aheader, sizeof(struct ctrl_header), 0);
if (aheader.num) {
// 將所有其它已經登入的鄰居通告給新註冊節點
send(peer->fd, peers_base, aheader.num*sizeof(struct tuple), 0);
}
// 將新登入的使用者連結入總的鄰居節點
list_add_tail(&peer->list, &conf->clients);
return ret;
}好了,以上就是服務端程式碼了。當然,我可能遺忘了Linux核心list_head移植部分的講解,也沒有select/poll/epoll的優劣比較,不過我覺得,把這些寫全不利於理解主要問題。我會把本文的全部程式碼編譯可執行後放入github,歡迎直接前往嘲笑拍磚。
VPN節點程式碼
首先看結構體
1.乙太網頭部,不必多說
struct ethernet_header {
unsigned char dest[6];
unsigned char source[6];
unsigned short type;
} __attribute__((packed));2.可以代表一個VPN節點的元組
struct tuple {
char addr[16];
unsigned short port;
unsigned short id;
unsigned short unused;
} __attribute__((packed));
3.回覆給VPN節點的資訊頭
struct ctrl_header {
unsigned short sid; // 資料來源的源ID號
unsigned short did; // 資料來源的目標ID號
unsigned short num; // 一共回覆給初創節點多少鄰居數量
unsigned short unused;
} __attribute__((packed));
4.標識一個鄰居節點
struct node_info {
struct list_head list; // 所有鄰居要接在一起
struct tuple tuple; // 鄰居的元組資訊
struct list_head macs; // 該鄰居虛擬子網一側的Mac地址集合
void *other; // 其它的,盡情發揮。估計可以去往TLS/DTLS方面發揮。
};5.一個實體地址必然要隸屬於VPN節點
struct mac_entry {
struct list_head list;
struct list_head node; //struct hlist_node; // 很顯然為了簡單使用list_head,但實際上應該用雜湊或者樹來組織,用於查詢
char mac[6]; // 儲存MAC地址
struct node_info *peer; // 儲存與該MAC地址相關的鄰居
};6.SimpleVPN的封裝格式
struct frame {
unsigned short sid; // 傳送方的ID
unsigned short did; // 接收方的ID
char data[1500]; // 資料。注意,為了簡單,我寫死了MTU為1500
int len; // 連同ID頭部,資料的長度
} __attribute__((packed));注意,frame最前面是兩個16bit的ID頭欄位,為什麼要用到它呢?既然已經知道資料發給誰了,封裝這個ID的意義又何在呢?SimpleVPN只是一個及其簡單的Demo,實際上,為了支援組播,這個ID欄位是必要的,我們把ID看作是組標識也是可以的。
7.控制通道的資料格式
struct control_frame {
struct ctrl_header header;
struct tuple tuple[0]; // 服務端通知新接入VPN節點時,可能有多個VPN節點已經接入了,一起打包通知
} __attribute__((packed));
8.處理棧
struct process_handler {
struct list_head list; // 所有的處理器模組連線為一個連結串列
struct node_info *peer; // 儲存臨時變數,其實用void *型別更好些
int (*send)(struct process_handler *this, struct frame *frame); // 從TAP到UDP Socket方向的處理
int (*receive)(struct process_handler *this, struct frame *frame); // 從UDP Socket到TAP方向的處理
struct config *conf; // 全域性配置
};這個結構體表現了VPN處理的核心機制。一般而言,當VPN拿到裸資料後,到將其發出前,需要一系列的操作,比如先加密/摘要,然後封裝協議頭,最後傳送,反過來當收到
網路資料後,要執行解除協議頭,解密/驗證摘要等反向的操作,所以我將它們成對組織起來:
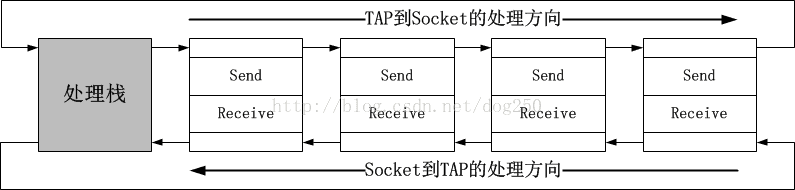
9.伺服器標識
struct server {
char addr[16];
unsigned short port;
void *others; // 顯然這裡可以儲存與構建TLS/DTLS相關的資訊
};10.全域性配置
struct config {
struct node_info *self; // 標識自身
int tap_fd; // TAP虛擬網絡卡的描述符
int udp_fd; // UDP Socket的描述符
int ctrl_fd; // 與伺服器通訊的描述符
struct server server; // 伺服器標識
struct list_head macs; // 本地所有學習到的MAC地址構建成的查詢樹,然則為了簡單,我先實現成了連結串列
struct list_head peers; // 本地所有已知的鄰居構建而成的鄰居表
struct list_head stack; // 處理棧
struct list_head *first; // 處理棧的棧底
struct list_head *last; // 處理棧的棧頂
int num_handlers; // 處理器的長度
};所有以上的結構體之間的關係如下:
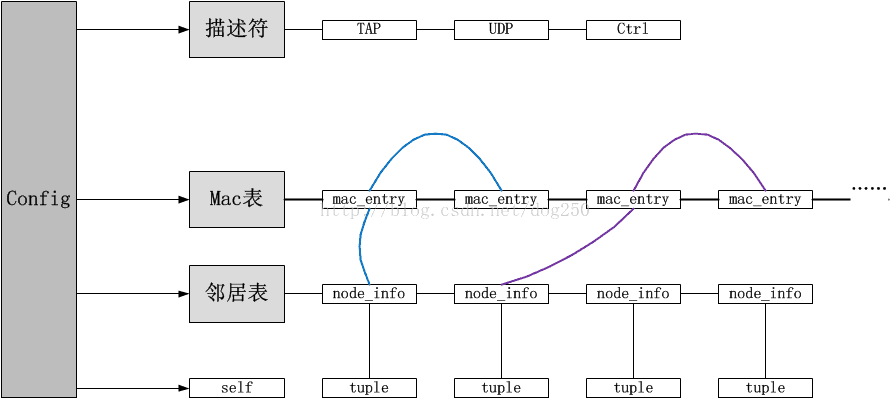
SimpleVPN原始碼分析
處理棧的邏輯:
int call_stack(struct config *conf, int dir)
{
int ret = 0;
struct process_handler *handler;
struct frame frame = {0};
int more = 1;
struct list_head *begin;
struct node_info *tmp_peer;
dir = !!dir;
// 根據方向引數獲取處理棧頂或者處理棧底
if (dir) {
begin = conf->first;
} else {
begin = conf->last;
}
handler = list_entry(begin, struct process_handler, list);
tmp_peer = NULL;
while(handler) {
handler->peer = tmp_peer;
// 根據方向引數決定呼叫的方向
if (dir && handler->send) {
ret = handler->send(handler, &frame);
} else if (!dir && handler->receive) {
ret = handler->receive(handler, &frame);
}
if (ret) {
break;
}
tmp_peer = handler->peer;
// 如果遍歷完了處理棧,則退出
if (dir && handler->list.next == &conf->stack) {
break;
}
if (!dir && handler->list.prev == &conf->stack) {
break;
}
// 否則,取下一個處理模組
if (dir) {
handler = list_entry(handler->list.next, struct process_handler, list);
} else {
handler = list_entry(handler->list.prev, struct process_handler, list);
}
}
return ret;
}接下來就很簡單了,定義幾個process_handler結構體以及回撥即可,比如下面的一對:
int read_from_tap(struct process_handler *obj, struct frame *frame)
{
int ret = 0;
int fd = obj->conf->tap_fd;
size_t len;
len = read(fd, frame->data, sizeof(frame->data));
frame->len = len;
return ret;
}
int write_to_tap(struct process_handler *obj, struct frame *frame)
{
int ret = 0;
int fd = obj->conf->tap_fd;
size_t len;
len = write(fd, frame->data, sizeof(frame->data));
return ret;
}
static struct process_handler tap_handler = {
.send = read_from_tap,
.receive = write_to_tap,
};程式碼就不解釋了,太簡單。我下面註釋一對比較複雜的handler邏輯。
--------------------------------------------------
當從TAP收到幀之後,要根據其MAC地址找到對應的鄰居,這個查詢過程和交換機的查詢過程非常類似,基本就是下面的邏輯:
int frame_routing(struct process_handler *obj, struct frame *frame)
{
int ret = 0;
struct ethernet_header eh;
struct list_head *tmp;
memcpy(&eh, frame->data, sizeof(eh));
list_for_each(tmp, &obj->conf->macs) {
struct mac_entry *tmp_entry = list_entry(tmp, struct mac_entry, node);
if (!memcmp(eh.dest, tmp_entry->mac, 6)) {
// 找到了明確的鄰居出口。
obj->peer = tmp_entry->peer;
break;
}
}
// 如果obj->peer為NULL,即沒有明確地鄰居出口,那麼應該對所有節點廣播。
return ret;
}如果反過來,資料從Socket收到,那麼就會經歷一個MAC學習的過程,這個和交換機也是類似的:
int mac_learning(struct process_handler *obj, struct frame *frame)
{
int ret = 0;
struct mac_entry *entry = NULL;
struct ethernet_header eh;
struct list_head *tmp;
memcpy(&eh, frame->data, sizeof(eh));
list_for_each(tmp, &obj->conf->macs) {
struct mac_entry *tmp_entry = list_entry(tmp, struct mac_entry, node);
if (!memcmp(eh.source, tmp_entry->mac, 6)) {
entry = tmp_entry;
break;
}
}
// 如果找到了表項,那麼更新它
if (entry) {
list_del(&entry->list);
list_del(&entry->node);
} else {
entry = (struct mac_entry *)calloc(1, sizeof(struct mac_entry));
}
if (!entry) {
printf("Alloc entry failed\n");
return -1;
}
// 更新或者新增表項
memcpy(entry->mac, eh.source, 6);
entry->peer = obj->peer;
INIT_LIST_HEAD(&entry->list);
list_add(&entry->list, &entry->peer->macs);
INIT_LIST_HEAD(&entry->node);
list_add(&entry->node, &obj->conf->macs);
return ret;
}最後,將上述的邏輯插入到一個處理模組routing_handler裡即可:
static struct process_handler routing_handler = {
.send = frame_routing,
.receive = mac_learning,
};其它的處理就不多說了,如果你想用TLS/DTLS或者用DH演算法協商出來的金鑰進行加密,那麼再寫一個process_handler即可。我接下啦展示一下一個處理模組是如何註冊到系統的,其實也很簡單,就是一堆連結串列操作:
int register_handler(struct process_handler *handler, struct config *conf)
{
INIT_LIST_HEAD(&handler->list);
handler->conf = conf;
list_add_tail(&handler->list, &conf->stack);
if (conf->first == NULL) {
conf->first = &handler->list;
}
conf->last = &handler->list;
return 0;
}
最後,我們來看看總體的邏輯,即main函式:
int main(int argc, char **argv)
{
char serverIP[16];
char localIP[16];
unsigned short serverPORT;
unsigned short localPORT;
struct config conf;
if (argc != 5) {
printf("./a.out serverIP serverPORT localIP localPORT\n");
}
strcpy(serverIP, argv[1]);
serverPORT = atoi(argv[2]);
strcpy(localIP, argv[3]);
localPORT = atoi(argv[4]);
init_config(&conf);
init_tap(&conf);
init_self(&conf, localIP, localPORT);
register_handler(&tap_handler, &conf);
register_handler(&routing_handler, &conf);
register_handler(&protocol_handler, &conf);
register_handler(&enc_handler, &conf);
register_handler(&udp_handler, &conf);
init_server_connect(&conf, serverIP, serverPORT); // 連線伺服器
server_msg_register(&conf); // 註冊自己
server_msg_read(&conf); // 讀取伺服器推送的鄰居並建立鄰居表
main_loop(&conf); // select三個檔案描述符
return 0;
}好了,以上就是核心的程式碼分析。全部的程式碼在github上:https://github.com/marywangran/SimpleVPN/
Simple如何跑起來
測試說明:三臺機器,機器0作為伺服器,機器1和機器2作為VPN節點,三臺機器均有兩塊網絡卡,處在兩個C段,分別為192.168.44.0/24和1.1.1.0/24,其中機器0的1.1.1.0/24段不接網線。編譯服務端:gcc CtrlCenter.c
執行服務端:./a.out 192.168.44.100 7000
編譯VPN節點:gcc SimpleVPN.c
執行VPN節點:
機器1上執行:
tunctl -u root -t tap0
ifconfig tap0 10.10.10.129/24
./a.out 192.168.44.100 7000 1.1.1.1 100
機器2上執行:
tunctl -u root -t tap0
ifconfig tap0 10.10.10.131/24
./a.out 192.168.44.100 7000 1.1.1.3 100
然後在機器1上ping機器2的tap0地址。
後面的說明
如果說僅僅是為了炫技,那麼就不要輕易設計自己的四層協議!明明已經有了TCP和UDP,還要再設計一個新的四層協議,這會造成損失。還記得VXLAN和NVGRE的區別嗎?VXLAN使用了通用的UDP來封裝,而NVGRE則沒有,這就是的NVGRE幾乎不能適配基於UDP元組的負載均衡。仔細想想OpenVPN,幸虧它採用了UDP封裝...它可以無縫適配Linux自帶的reuseport機制來簡單負載均衡,不然負載均衡都得自己寫。我記得最初的負載均衡是我在IP層用nf_conntrack來做的,其實我之所以用nf_conntrack來做,那是因為那時我並不知道reuseport...如果沒有reuseport,然後你還不懂nf_conntrack,那就得花費大量的精力去優化OpenVPN服務端的負載均衡或者多處理。
在網路虛擬化方面,其中也包括一些VPN技術,很多廠商都在做這塊,我們來看看如今他們分屬的陣營,我大致將它們分為網路陣營和軟體陣營,我比較傾向於網路陣營。
我大致分下類,VXLAN,VN-TAG,IPSec,這些倡導者都屬於網路陣營,比如Cisco,IETF,而像NVGRE,VEPA,SSL這種,基本都是軟體陣營,比如倡導者是微軟,HP之流,然而我們發現,這兩個陣營誰也壓不倒誰,在VXLAN和NVGRE的PK中,網路陣營完勝,但在VN-TAG和VEPA的較量中,網路陣營又輸的比較慘淡...Why?
是該聯合起來的時候了。我們發現,贏的那一方一定是便宜的那一方,一定是簡單的那一方。所以我一向提倡炫技者止步的意義就在於此。同軸電纜複雜吧,輸給了簡單便宜的雙絞線,魏國武卒昂貴吧,卻輸給了秦國農民軍...
快到中午了,令人遺憾的五一勞動節...