
用Python爬取拉鉤網招聘職位資訊
阿新 • • 發佈:2019-02-10
本文實現自動爬取拉鉤網招聘資訊,並將爬取結果儲存在本地文字中(也可以將資料存入資料庫)
使用到的Python模組包(Python3):
1.urllib.request
2.urllib.parse
3.json
簡單分析:
1.在向伺服器傳送請求,需要傳入post引數
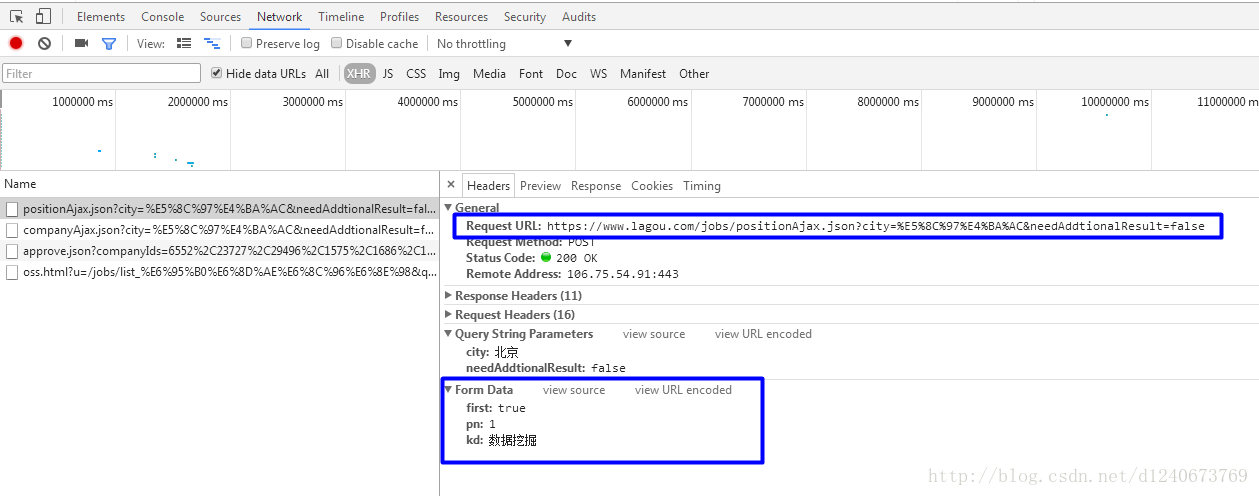
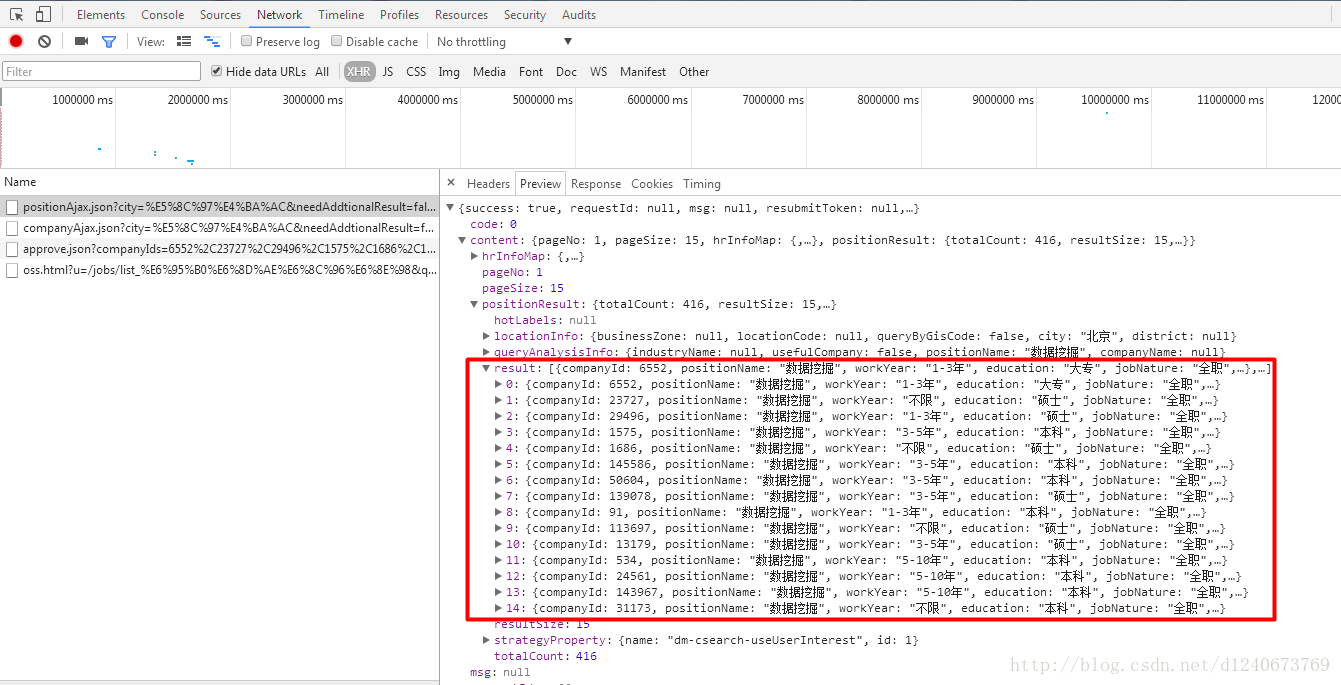
2.搜尋的職位列表資訊存在一個josn檔案中,可使用json模組解析
3.翻頁
本文使用while True和break結合,根據json中result的值是否為空來判斷當前要是否是最後一頁,也可以根據json檔案中pageSize和totalCount兩個欄位的值得出總的頁面數。
完整程式碼:
import 爬取結果:
