
python爬蟲之反爬蟲情況下的煎蛋網圖片爬取初步探索
本次爬蟲網址:http://jandan.net/ooxx
前言:
前段時間一直在折騰基於qqbot的QQ機器人,昨天用itchat在微信上也寫了一個機器人,相比webqq,微信的web端功能比較豐富,圖片、檔案等都可以傳輸。今天閒來無事準備給寫個爬蟲豐富微信機器人的功能,就想到了爬煎蛋網上面的圖片。
說做就做,開啟瀏覽器一看,渲染前的原始碼裡是沒有圖片地址的。這個很正常,首先想到的就是非同步請求去獲取例如json格式的圖片地址,然後渲染在頁面上。於是用Chrome的全域性搜尋功能嘗試搜了一下某一張圖片的地址,結果居然是沒有搜到。早就耳聞煎蛋被爬蟲弄得苦不堪言,看來也開始採取一些措施了。於是去GitHub上搜了一下jiandan關鍵詞,按時間排序,發現靠前的幾個專案要不就沒意識到煎蛋的反爬從而還是在用原來的方式直接處理原始碼,要不就是在用selenium(web自動化框架,可參考我的這篇文章:
正文:
首先檢視js渲染前的html原始碼,發現放圖片的位置是這樣的
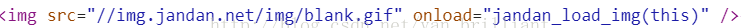
本該放地址的地方赫然放著blank.gif,並且在onload屬性上綁定了一個jandan_load_img函式。這個jandan_load_img就成為本次爬蟲的突破所在了。繼續ctrl+shift+F全域性搜尋,找到這個函式
function jandan_load_img(b) { var d = $(b); var f = d.next("span.img-hash"); var e = f.text(); f.remove(); var c = f_K1Ft7i9UekcAhptpgQlLRFFKpzH6gOr0(e, "n8DpQLgoyVr2evbxYcQyFzxk9NRmsSKQ"); var a = $('<a href="' + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.(gif|jpg|jpeg))/, "$1large$3") + '" target="_blank" class="view_img_link">[檢視原圖]</a>'); d.before(a); d.before("<br>"); d.removeAttr("onload"); d.attr("src", location.protocol + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.gif)/, "$1thumb180$3")); if (/\.gif$/.test(c)) { d.attr("org_src", location.protocol + c); b.onload = function() { add_img_loading_mask(this, load_sina_gif) } } }
果然就是這個函式在處理圖片相關的標籤,寫在一個單獨的js檔案裡。容易看到,第7、8行將a標籤插入到img之前,檢視原始碼看到a標籤就是是檢視原圖的連結,也就是我們接下來爬取的時候用到的地址了。第6行f_後跟著一長串字母的這個函式(簡稱f函式)返回的就是圖片地址。第7行中replace函式的作用是當圖片為gif時替換中間的一個字串為large。
那麼接下來的任務就是分析f函式到底是怎麼獲取圖片的地址的。首先看引數,第一個引數e為img-hash標籤的text,第二個引數則是一個常量。這個常量我實測是會變化的,所以需要我們去請求這個js檔案然後用正則去匹配到該常量。js檔案的地址則寫在了html原始碼裡,檔名應該也是會變化的,也是用正則去匹配到。拿到常量之後接下來仍然使用chrome全域性搜尋(注:最好是打上斷點跳過去,同一個js檔案裡的第605行和第943行有兩個f函式可能會造成干擾,參見本文評論區),找到f函式,我發現此函式只是在做一些md5、base_64加密等操作,並不算複雜,可以將js程式碼轉為python執行。當然也可以選擇直接執行js,不過應該也是比較耗費效能的。我在轉化成python程式碼的過程中,在base64解碼上耗費了較長時間,也說明了自己在字元編碼方面的知識比較薄弱。
下面是我對轉換的一點解釋,把一些無意義的ifelse等程式碼精簡掉,再把程式碼分成五塊之後,f函式長這樣:
var f_K1Ft7i9UekcAhptpgQlLRFFKpzH6gOr0 = function(m, r, d) {
var q = 4;
r = md5(r);
var o = md5(r.substr(0, 16));
var l = m.substr(0, q);
var c = o + md5(o + l);
var k;
m = m.substr(q);
k = base64_decode(m);
var h = new Array(256);
for (var g = 0; g < 256; g++) {
h[g] = g
}
var b = new Array();
for (var g = 0; g < 256; g++) {
b[g] = c.charCodeAt(g % c.length)
}
for (var f = g = 0; g < 256; g++) {
f = (f + h[g] + b[g]) % 256;
tmp = h[g];
h[g] = h[f];
h[f] = tmp;
}
var t = "";
k = k.split("");
for (var p = f = g = 0; g < k.length; g++) {
p = (p + 1) % 256;
f = (f + h[p]) % 256;
tmp = h[p];
h[p] = h[f];
h[f] = tmp;
t += chr(ord(k[g]) ^ (h[(h[p] + h[f]) % 256]));
}
t = t.substr(26);
return t
};轉換得到的python程式碼也相對應地分成五塊之後如下:
def parse(imgHash, constant):
q = 4
constant = md5(constant)
o = md5(constant[0:16])
l = imgHash[0:q]
c = o + md5(o + l)
imgHash = imgHash[q:]
k = decode_base64(imgHash)
h =list(range(256))
b = list(range(256))
for g in range(0,256):
b[g] = ord(c[g % len(c)])
f=0
for g in range(0,256):
f = (f+h[g]+b[g]) % 256
tmp = h[g]
h[g] = h[f]
h[f] = tmp
result = ""
p=0
f=0
for g in range(0,len(k)):
p = (p + 1) % 256;
f = (f + h[p]) % 256
tmp = h[p]
h[p] = h[f]
h[f] = tmp
result += chr(k[g] ^ (h[(h[p] + h[f]) % 256]))
result = result[26:]
return result這樣對比之下應該就比較清晰了,基本上就是逐行翻譯。另外base64需要重寫一下。
最後就是一些普通的http請求操作了,以及使用itchat進行圖片傳輸。所有程式碼已經上傳到github上,後續有時間我打算新增上ip代理等新功能。沒有系統學習過python所以程式碼可能不太規範,希望大家多多交流。專案地址:點選開啟連結
另附本次爬蟲的思維導圖:
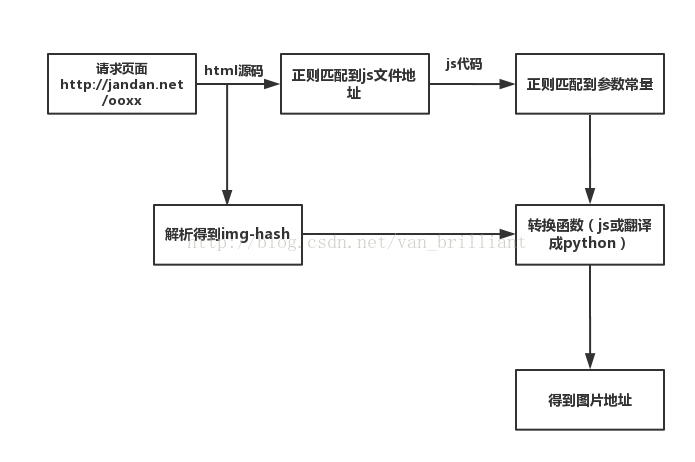
溫馨提醒:雖然煎蛋肯定還有其他反爬措施,大家在爬蟲過程中請務必遵守基本的網際網路秩序,具體是啥相信大家都懂滴。
參考資料:
python base64解碼incorect padding錯誤:點選開啟連結
寫於2017年12月6日晚
編輯於2018年2月6日晚