
探索性資料分析與視覺化
阿新 • • 發佈:2019-02-10
世界如此大,我想去看看;資料如此豐富,怎麼能看完。
面對未知,人類是富有探索精神的,可以不畏艱險,可以排除萬難,正是這種探索精神使得人類不斷進步不斷創造一個又一個奇蹟。對於紛繁複雜的資料世界,我們如何進行探索性分析呢?
探索性資料分析
之前的一些模型是假定資料服從某種分佈,然後用樣本去調整假設分佈的引數,比如貝葉斯模型,GMM等。如果面臨錯綜複雜的資料,我們想去直接看到資料最原始的特點,比如,某個屬性是什麼分佈特點,某些屬性的關係,哪些因素具有最大量的資訊,某些不確定關係的研究等等。這個時候,假設模型的方法就不那麼好使了,這時候就較為考驗一個綜合能力了。
所謂探索性資料分析,是在沒有頭緒的情況下,對資料進行的基本分析
與視覺化的關係
探索性的資料分析,側重於原始資料本身的展示,故此與資料視覺化具有相當緊密的聯絡,並且圖形展示更直觀且有利於發現有價值的資訊。
視覺化能夠幫助我們搞定以下幾個問題:
1. 瞭解資料基本特徵
2. 發現數據潛在的模式
3. 指導建模策略
4. 為工程提供參考資訊和必要的更正
探索內容與實現
雖說是探索,但也得有點目標才好,不能啥都不知道就愣頭愣腦地往上衝,那豈不是自我證明非二即傻。手段要靈活,快捷。
Python2.7+ubuntu14.0
我們採取一個先分後總的研究順序來探索。
分別看看各個屬性的資料特徵
大體分佈最直觀的就是直方圖了,這個最易於實現。
import matplotlib.pyplot as plt
data1 = [2,2,2,2,3,3,3,4,4,4,4,4,4]
data2 = [2.3,2.4,3.4,2,1,3.4,2,5.6]
plt.xlabel('Smarts')
plt.ylabel('Probability')
plt.title(r'$\mathrm{Histogram\ of\ IQ:}\ \mu=100,\ \sigma=15$' 上面的程式碼得到的兩個圖如下:
圖中的橫縱座標的名稱和標題只是為了展示如何給圖配置,而不是真實情況。
稍微進階一下,將多個圖放到同一個圖中展示(新增標題之類的操作和單個圖時是一樣的)。
import matplotlib.pyplot as plt
data1 = [2,2,2,2,3,3,3,4,4,4,4,4,4]
data2 = [2.3,2.4,3.4,2,1,3.4,2,5.6]
fig = plt.figure()
ax1 = fig.add_subplot(2, 2, 1) # 2*2 的 第一個,及左上側
ax1.hist(data1, bins=5, facecolor='green')#分成5份
ax2 = fig.add_subplot(222) # 2*2 的 第二個,及右上側
ax2.hist(data2, bins=5, facecolor='green')#分成5份
ax3 = fig.add_subplot(212) # 2*1 的 第3個, 及下側一整個
ax3.hist(data1, bins = 4, facecolor = 'green', alpha = 0.5)
ax3.hist(data2, bins = 4, facecolor = 'blue', alpha = 0.5)
plt.show()
而資料的均值、最大最小表現形式較好的則是箱線圖。
import pandas as pd
import matplotlib.pyplot as plt
# 本地讀取資料 #
#df = pd.read_csv("your/file/direction/name.csv")
# 讀取網路資料 #
data_url = "https://raw.githubusercontent.com/alstat/Analysis-with-Programming/master/2014/Python/Numerical-Descriptions-of-the-Data/data.csv"
df = pd.read_csv(data_url)
print(type(df))
print df.head() # 頭
print df.tail() # 細節
print df.columns # 列名
print df.index # 行號
#print df.drop(df.columns[[1, 2]], axis = 1).head() # 捨棄列axis=1;捨棄行axis=0(預設)
print df.describe() # 統計特性,最大,最小,均值,方差
plt.show(df.boxplot()) # 箱線圖繪製展示
#### 或者採用 模組 seaborn #### 這個也非常好用,顏色自動搭配
import seaborn as sns
import matplotlib.pyplot as plt
plt.show(sns.boxplot(data = df))
#plt.show(sns.distplot(df.ix[:,2], rug = True, bins = 15))上面程式碼的兩個圖如下:

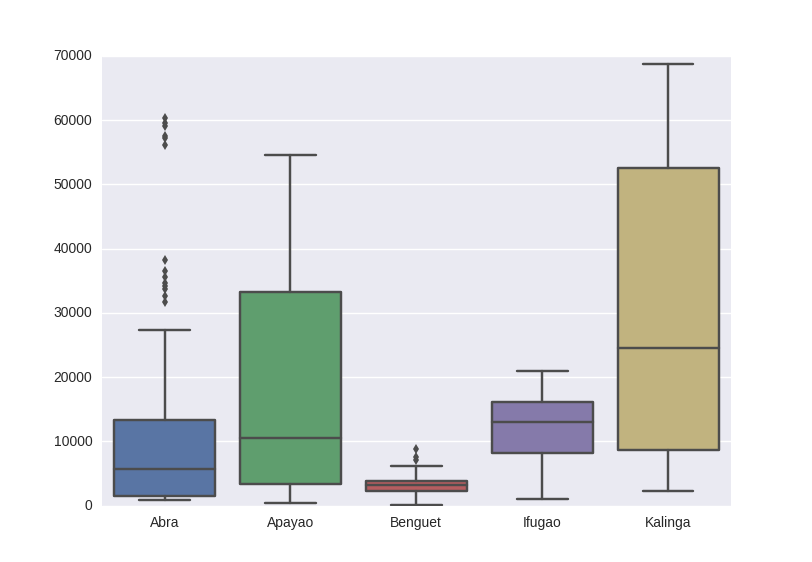
是否自相關?對於時間序列,自相關是對某個屬性值,時間T和T+1時刻的值存線上性關係。
# 自相關係數
import numpy as np
def autocorrelation(x,lags):
# 計算lags階以內的自相關係數,返回lags個值,分別計算序列均值,標準差
# lags表示錯開的時間間隔
n = len(x)
x = np.array(x)
result = [np.correlate(x[i:]-x[i:].mean(),x[:n-i]-x[:n-i].mean())[0]\
/(x[i:].std()*x[:n-i].std()*(n-i)) \
for i in range(1,lags+1)]
return result
z = autocorrelation(df.ix[:, 1], 1)
print(z)# 繪製個原始資料的散點圖 並將一階到10階的自相關係數也繪製到上面
import matplotlib.pyplot as plt
import numpy as np
def autocorrelation(x,lags):
# 計算lags階以內的自相關係數,返回lags個值,分別計算序列均值,標準差
# lags表示錯開的時間間隔
# Notice: 標題神馬的不支援中文 #
n = len(x)
x = np.array(x)
result = [np.correlate(x[i:]-x[i:].mean(),x[:n-i]-x[:n-i].mean())[0]\
/(x[i:].std()*x[:n-i].std()*(n-i)) \
for i in range(1,lags+1)]
return result
fig = plt.figure()
axes1 = fig.add_axes([0.1, 0.1, 0.8, 0.8]) # main axes
axes2 = fig.add_axes([0.2, 0.5, 0.4, 0.3]) # inset axes
# main figure
x1 = np.linspace(1, len(df.ix[:, 1]), len(df.ix[:, 1]))
axes1.plot(x1, df.ix[:, 1], 'r')
axes1.set_xlabel(df.columns[1])
axes1.set_ylabel('value')
axes1.set_title('main')
# insert
x2 = np.linspace(1, 10, 10)
y2 = autocorrelation(df.ix[:, 1], 10)
y2 = np.array(y2)
axes2.plot(x2, y2, 'g')
axes2.set_xlabel('jieci')
axes2.set_ylabel('ar')
axes2.set_title('autoRelation of different jieci')
plt.show()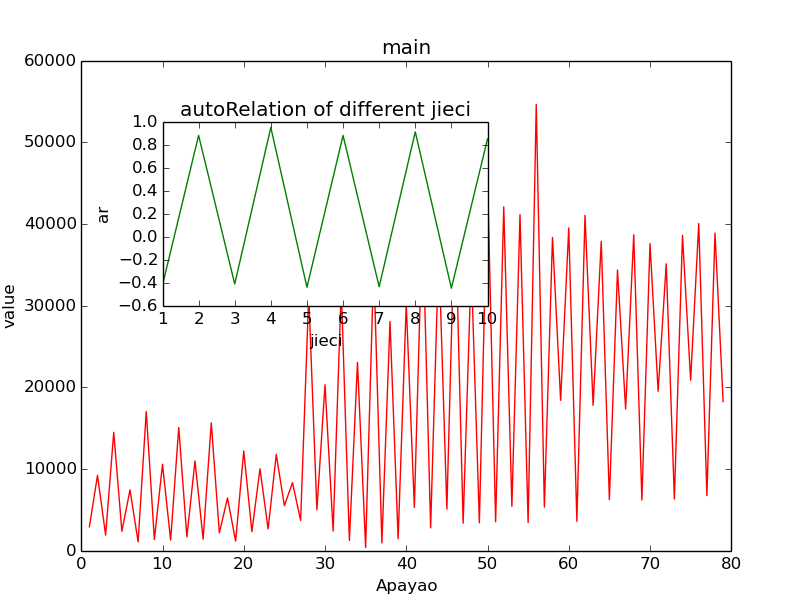
密度與熱度。密度表示分佈情況,可以是單個屬性,也可以是多個屬性的聯合分佈。單個屬性的密度可以用細密的直方圖(將bins值調大)展示。多個屬性可以用氣泡圖來展示,也可以用heat map來表示。(三維heat map)熱點圖圖示化了離散資料(事件或事物)的分佈及其相互關係,常常以一張具備顯著顏色差異圖片的方式呈現最終 結果,亮色一般代表事件發生頻率較高或事物分佈密度較大,暗色反之。很明顯,heat map對資料的要求就是需要有座標
#(1) 基於二維位置資訊的熱點圖 #
import seaborn as sns
plt.show(sns.jointplot(df.ix[:,1], df.ix[:,2], kind = "kde"))
#df.ix[:,1]代表所有點在X軸的位置 #
#df.ix[:,2]代表所有點在Y軸的位置 #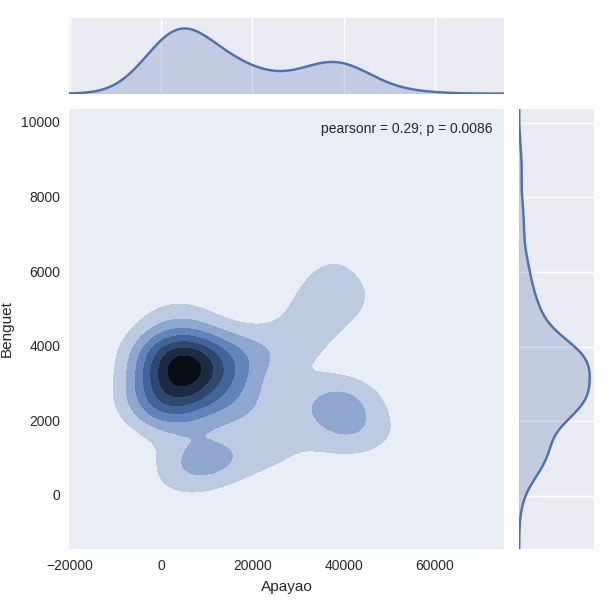
```
#(2) 或者藉助別人寫的一個模組
from pyheatmap.heatmap import HeatMap
http://www.open-open.com/lib/view/open1348041833834.html
但是不怎麼好使#(3) 基於二維位置資訊+密度值 的 平面熱點圖 #
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
side = np.linspace(-2, 2, 15)
X, Y = np.meshgrid(side, side)
# X 和 Y 聯合起來表示了網格的位置 #
# X 表示了網格中所有點的x軸值 #
print(type(X)) # narray 矩陣 #
Z = np.exp(-((X-1)**2 + Y**2))
# Z 表示了某個位置處的值 #
print(type(Z)) # Z是一個矩陣 #
plt.show(plt.pcolormesh(X, Y, Z, cmap=cm.RdBu))
# 沒有cmap時,預設是黑白的 #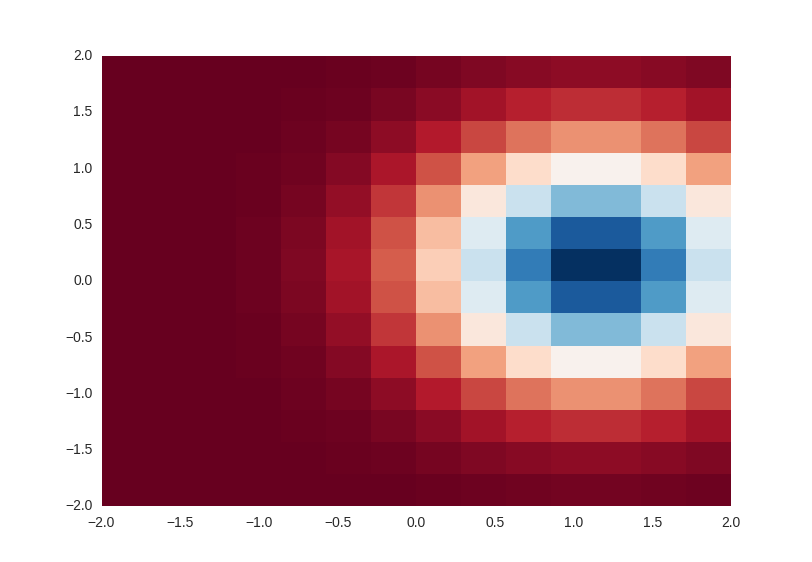
#(4) 用 plt.pcolor 繪製效果, 跟pcolormesh效果類似 #
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
fig, ax = plt.subplots()
p = ax.pcolor(X/(2*np.pi), Y/(2*np.pi), Z, cmap=cm.RdBu, vmin=abs(Z).min(), vmax=abs(Z).max())
cb = fig.colorbar(p, ax=ax)
plt.show()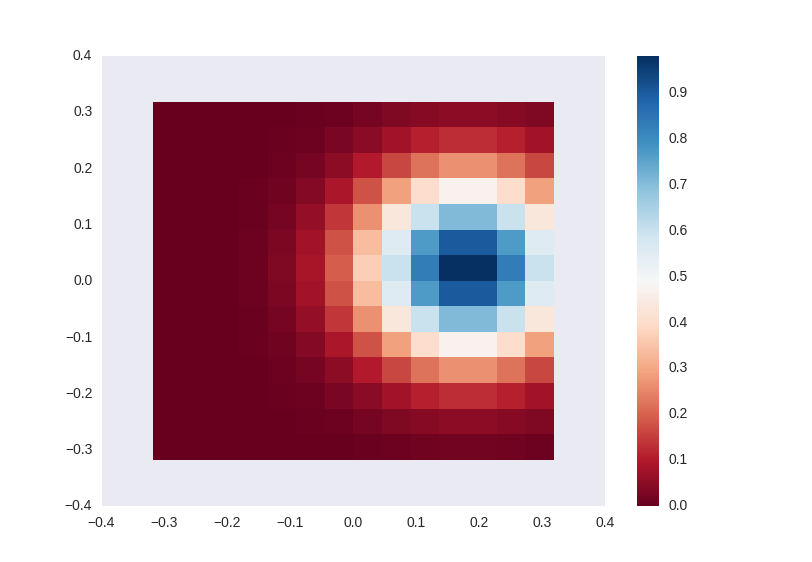
#(5)基於密度值(高度)的 等高線圖 # 需要矩陣表示的高度 #
import matplotlib.pyplot as plt
cnt = plt.contour(Z, cmap=cm.RdBu, vmin=abs(Z).min(), vmax=abs(Z).max(), extent=[0, 1, 0, 1])
plt.show()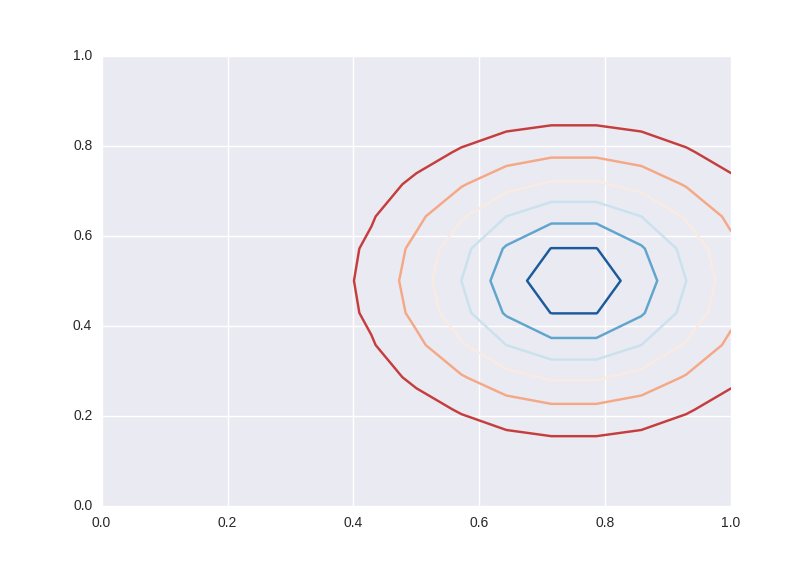
#(6) 基於二維位置資訊+密度值 的 三維熱點圖
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
import numpy as np
# suface圖
fig = plt.figure(figsize=(14,6))
# `ax` is a 3D-aware axis instance because of the projection='3d' keyword argument to add_subplot
ax = fig.add_subplot(1, 2, 1, projection='3d')
p = ax.plot_surface(X, Y, Z, rstride=4, cstride=4, linewidth=0)
# surface_plot with color grading and color bar
ax = fig.add_subplot(1, 2, 2, projection='3d')
p = ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap=cm.coolwarm, linewidth=0, antialiased=False)
cb = fig.colorbar(p, shrink=0.5)
plt.show()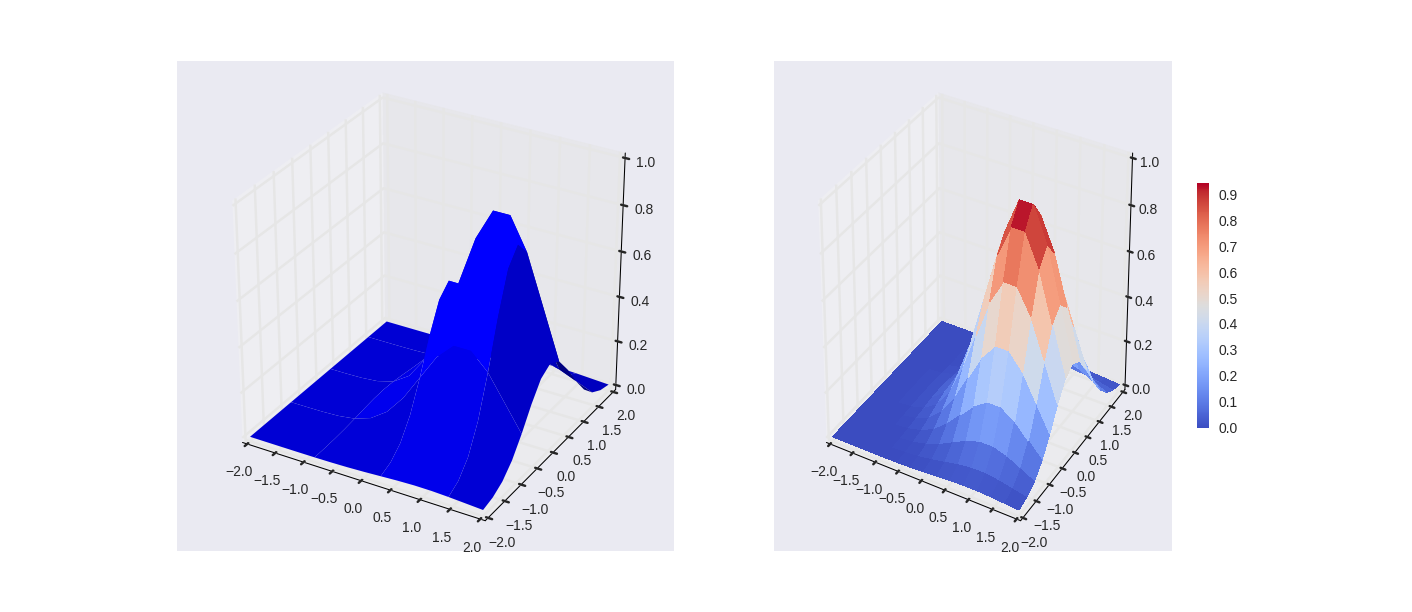
#(7)想將在各個平面上的投影也體現出來 #
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
alpha = 0.7
phi_ext = 2 * np.pi * 0.5
def flux_qubit_potential(phi_m, phi_p):
return 2 + alpha - 2 * np.cos(phi_p) * np.cos(phi_m) - alpha * np.cos(phi_ext - 2*phi_p)
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(1,1,1, projection='3d')
phi_m = np.linspace(0, 2*np.pi, 100)
phi_p = np.linspace(0, 2*np.pi, 100)
X,Y = np.meshgrid(phi_p, phi_m)
Z = flux_qubit_potential(X, Y).T
ax.plot_surface(X, Y, Z, rstride=4, cstride=4, alpha=0.25)
cset = ax.contour(X, Y, Z, zdir='z', offset=-np.pi, cmap=cm.coolwarm)
cset = ax.contour(X, Y, Z, zdir='x', offset=-np.pi, cmap=cm.coolwarm)
cset = ax.contour(X, Y, Z, zdir='y', offset=3*np.pi, cmap=cm.coolwarm)
ax.set_xlim3d(-np.pi, 2*np.pi);
ax.set_ylim3d(0, 3*np.pi);
ax.set_zlim3d(-np.pi, 2*np.pi);
plt.show()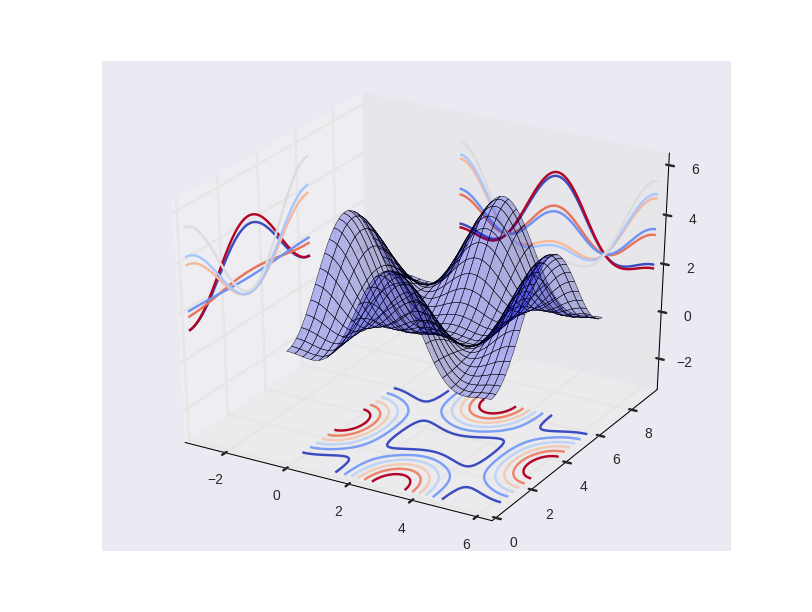
有人會問,空缺值怎麼辦,這就要看你自己怎麼處理了。
有人會問,為什麼不加上歸一化的操作,沒有說不行,但我們更傾向於發現原始資料的特點,所以操作最好是原始資料來操作。
看看哪些屬性對結果更重要一些。這裡可選的方法就多了,有統計學的方法,比如Pearson相關係數(Spearman係數等)、卡方檢驗,有資訊理論的方 ,比如資訊增益率、GainRatio等,有資料探勘的方法,比如邏輯迴歸的屬性係數、隨機森林的屬性重要性等。
#(1)Pearson線性相關係數
import numpy as np
# np.correlate 只是計算兩個向量對應位置相乘,再求和
# 樣本協方差如下
cov = np.correlate(df.ix[:, 1] - df.ix[:, 1].mean(), df.ix[:, 2] - df.ix[:, 2].mean())/(len(df.ix[:, 1] - 1))
# 與下面的計算是一樣的
#cov = np.dot(df.ix[:, 1] - df.ix[:, 1].mean(), df.ix[:, 2] - df.ix[:, 2].mean())/(len(df.ix[:, 1] - 1))
# 樣本方差如下
std1 = df.ix[:, 1].std()
std2 = df.ix[:, 2].std()
# 故兩個屬性的Pearson線性相關係數如下
Pearson = cov/(std1*std2)
print(Pearson)
# 相關係數的大小 與 線性相關性 的關係
# 0.8-1.0 極強相關
# 0.6-0.8 強相關
# 0.4-0.6 中等程度相關
# 0.2-0.4 弱相關
# 0.0-0.2 極弱相關或無相關看看某些屬性間是否也存在某些關係。
# 兩個屬性之間的 散點圖 #
import matplotlib.pyplot as plt
plt.xlabel(df.columns[2])
plt.ylabel(df.columns[3])
plt.grid(True)
plt.show(plt.scatter(df.ix[:, 2], df.ix[:, 3]))
# 兩個屬性之間的 聯合分佈 # 用seaborn更方便一些 #
import matplotlib.pyplot as plt
import seaborn as sns
plt.show(sns.jointplot(df.ix[:,1], df.ix[:,2], kind = "kde"))
# 三個屬性之間的關係 展示 # 可以用上面的三維展示方法,plot_surface,如上文中的介紹,此處不再贅述。
散點圖與聯合分佈圖
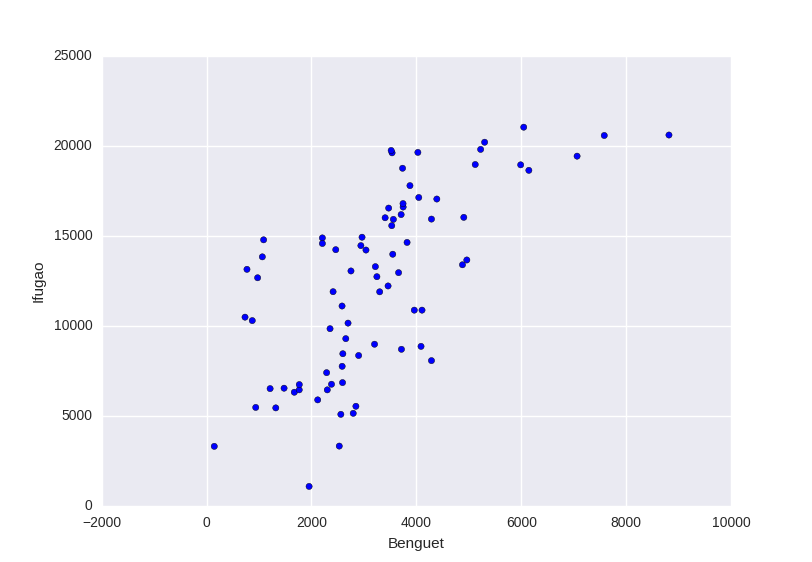
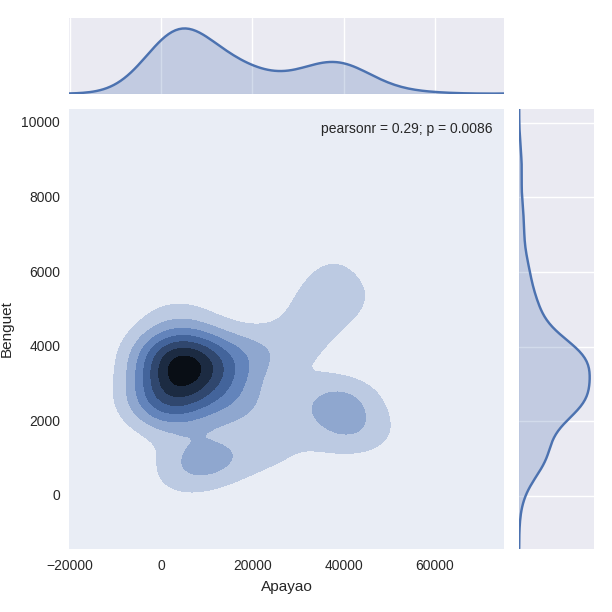
# 多個個體之間的關係,比如社交關係 的展示 #
再簡單聚個類,不要小瞧聚類,很多時候會非常給力。當然聚類方法的選擇和聚類個數需要好好試試。聚類可以看到資料大體的特點,還可以把某些屬性跟所分的類聯絡到一起。
# python 聚類
#(1)K-Means聚類
#(2)基於密度的聚類