
Java volatile的記憶體語義與AQS鎖記憶體可見性
0、引子
提到volatile首先想到就是:
到這裡大家感覺自己對volatile理解了嗎?
如果理解了,大家考慮這麼一個問題:ReentrantLock(或者其它基於AQS實現的鎖)是如何保證程式碼段中變數(變數主要是指共享變數,存在競爭問題的變數)的可見性?
private static ReentrantLock reentrantLock = new ReentrantLock();
private static intcount = 0;
//...
// 多執行緒 run 如下程式碼
reentrantLock.lock();
try
{
count++;
}
finally
{
reentrantLock.unlock();
}
//... 既然提到了可見性,那就先熟悉幾個概念:
1、Java Memory Model (JMM)即 Java 記憶體模型
2、重排序
在執行程式時,為了提高效能,編譯器和處理器常常會對指令做重排序。重排序分3種類型:
- 編譯器優化的重排序。編譯器在不改變單執行緒程式語義的前提下,可以重新安排語句的執行順序。
- 指令級並行的重排序。現代處理器採用了指令級並行技術(Instruction-Level
Parallelism,ILP)來將多條指令重疊執行。如果不存在資料依賴性,處理器可以改變語句對應機器指令的執行順序。 - 記憶體系統的重排序。由於處理器使用快取和讀/寫緩衝區,這使得載入和儲存操作看上去可能是在亂序執行。
從Java原始碼到最終實際執行的指令序列,會分別經歷下面3種重排序:

對於編譯器,JMM的編譯器重排序規則會禁止特定型別的編譯器重排序(不是所有的編譯器重排序都要禁止)。對於處理器重排序,JMM的處理器重排序規則會要求Java編譯器在生成指令序列時,插入特定型別的記憶體屏障(Memory Barriers,Intel稱之為Memory Fence)指令,通過記憶體屏障指令來禁止特定型別的處理器重排序。
JMM屬於語言級的記憶體模型,它確保在不同的編譯器和不同的處理器平臺之上,通過禁止特定型別的編譯器重排序和處理器重排序,為程式設計師提供一致的記憶體可見性保證。
3、happens-before
- 程式順序規則:一個執行緒中的每個操作,happens-before於該執行緒中的任意後續操作。
- 監視器鎖規則:對一個鎖的解鎖,happens-before於隨後對這個鎖的加鎖。
- volatile變數規則:對一個volatile域的寫,happens-before於任意後續對這個volatile域的讀。(對一個volatile變數的讀,總是能看到【任意執行緒】對這個volatile變數最後的寫入)
- 傳遞性:如果A happens-before B,且B happens-before C,那麼A happens-before C。
兩個操作之間具有happens-before關係,並不意味著前一個操作必須要在後一個操作之前執行!happens-before僅僅要求前一個操作(執行的結果)對後一個操作可見,且前一個操作按順序排在第二個操作之前(the first is visible to and ordered before the second)。
4、記憶體屏障
- 硬體層的記憶體屏障分為兩種:Load Barrier 和 Store Barrier即讀屏障和寫屏障。
記憶體屏障有兩個作用:
- 阻止屏障兩側的指令重排序;
- 強制把寫緩衝區/快取記憶體中的資料等寫回主記憶體,讓快取中相應的資料失效。
對於Load Barrier來說,在指令前插入Load Barrier,可以讓快取記憶體中的資料失效,強制從新從主記憶體載入資料;
對於Store Barrier來說,在指令後插入Store Barrier,能讓寫入快取中的最新資料更新寫入主記憶體,讓其他執行緒可見。
5、volatile的記憶體語義
從JSR-133開始(即從JDK5開始),volatile變數的寫-讀可以實現執行緒之間的通訊。
從記憶體語義的角度來說,volatile的寫-讀與鎖的釋放-獲取有相同的記憶體效果:
- volatile寫和鎖的釋放有相同的記憶體語義;
- volatile讀與鎖的獲取有相同的記憶體語義。
volatile僅僅保證對單個volatile變數的讀/寫具有原子性,而鎖的互斥執行的特性可以確保對整個臨界區程式碼的執行具有原子性。在功能上,鎖比volatile更強大;在可伸縮性和執行效能上,volatile更有優勢。
volatile變數自身具有下列特性:
- 可見性。對一個volatile變數的讀,總是能看到(任意執行緒)對這個volatile變數最後的寫入。
- 原子性:對任意單個volatile變數的讀/寫具有原子性,即使是64位的long型和double型變數,只要它是volatile變數,對該變數的讀/寫就具有原子性。如果是多個volatile操作或類似於volatile++這種複合操作,這些操作整體上不具有原子性。
volatile寫和volatile讀的記憶體語義
- 執行緒A寫一個volatile變數,實質上是執行緒A向接下來將要讀這個volatile變數的某個執行緒發出了(其對共享變數所做修改的)訊息。
- 執行緒B讀一個volatile變數,實質上是執行緒B接收了之前某個執行緒發出的(在寫這個volatile變數之前對共享變數所做修改的)訊息。
- 執行緒A寫一個volatile變數,隨後執行緒B讀這個volatile變數,這個過程實質上是執行緒A通過主記憶體向執行緒B傳送訊息。
JMM針對編譯器制定的volatile重排序規則表

- 當第二個操作是volatile寫時,不管第一個操作是什麼,都不能重排序。這個規則確保volatile寫之前的操作不會被編譯器重排序到volatile寫之後。
- 當第一個操作是volatile讀時,不管第二個操作是什麼,都不能重排序。這個規則確保volatile讀之後的操作不會被編譯器重排序到volatile讀之前。
- 當第一個操作是volatile寫,第二個操作是volatile讀時,不能重排序。
為了實現volatile的記憶體語義,編譯器在生成位元組碼時,會在指令序列中插入記憶體屏障來禁止特定型別的處理器重排序。對於編譯器來說,發現一個最優佈置來最小化插入屏障幾乎是不可能的。為此,JMM採取保守策略。下面是基於保守策略的JMM記憶體屏障插入策略。
- 在每個volatile寫操作的前面插入一個StoreStore屏障。
- 在每個volatile寫操作的後面插入一個StoreLoad屏障。
- 在每個volatile讀操作的後面插入一個LoadLoad屏障。
- 在每個volatile讀操作的後面插入一個LoadStore屏障。
LoadLoad屏障:對於這樣的語句Load1; LoadLoad; Load2,在Load2及後續讀取操作要讀取的資料被訪問前,保證Load1要讀取的資料被讀取完畢。
StoreStore屏障:對於這樣的語句Store1; StoreStore; Store2,在Store2及後續寫入操作執行前,保證Store1的寫入操作對其它處理器可見。
LoadStore屏障:對於這樣的語句Load1; LoadStore; Store2,在Store2及後續寫入操作被刷出前,保證Load1要讀取的資料被讀取完畢。
StoreLoad屏障:對於這樣的語句Store1; StoreLoad; Load2,在Load2及後續所有讀取操作執行前,保證Store1的寫入對所有處理器可見。它的開銷是四種屏障中最大的。在大多數處理器的實現中,這個屏障是個萬能屏障,兼具其它三種記憶體屏障的功能。
上述記憶體屏障插入策略非常保守,但它可以保證在任意處理器平臺,任意的程式中都能得到正確的volatile記憶體語義。
下面是保守策略下,volatile寫插入記憶體屏障後生成的指令序列示意圖.
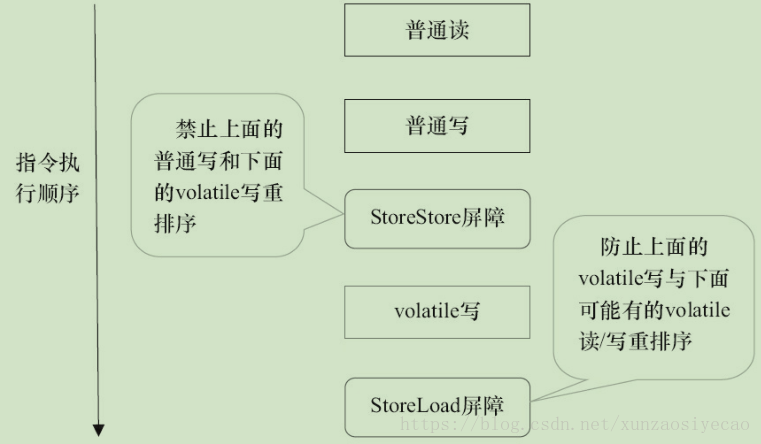
圖中的StoreStore屏障可以保證在volatile寫之前,其前面的所有普通寫操作已經對任意處理器可見了。這是因為StoreStore屏障將保障上面所有的普通寫在volatile寫之前重新整理到主記憶體。
這裡比較有意思的是,volatile寫後面的StoreLoad屏障。此屏障的作用是避免volatile寫與後面可能有的volatile讀/寫操作重排序。因為編譯器常常無法準確判斷在一個volatile寫的後面是否需要插入一個StoreLoad屏障(比如,一個volatile寫之後方法立即return)。為了保證能正確實現volatile的記憶體語義,JMM在採取了保守策略:在每個volatile寫的後面,或者在每個volatile讀的前面插入一個StoreLoad屏障。從整體執行效率的角度考慮,JMM最終選擇了在每個volatile寫的後面插入一個StoreLoad屏障。因為volatile寫-讀記憶體語義的常見使用模式是:一個寫執行緒寫volatile變數,多個讀執行緒讀同一個volatile變數。當讀執行緒的數量大大超過寫執行緒時,選擇在volatile寫之後插入StoreLoad屏障將帶來可觀的執行效率的提升。從這裡可以看到JMM在實現上的一個特點:首先確保正確性,然後再去追求執行效率。
下面是在保守策略下,volatile讀插入記憶體屏障後生成的指令序列示意圖:
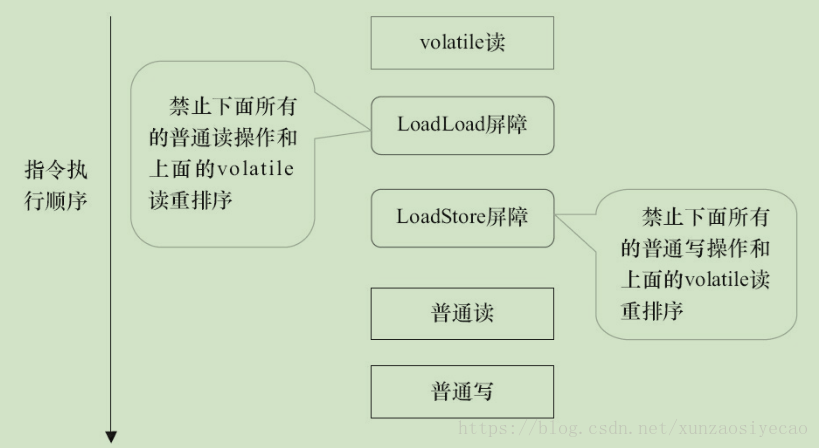
圖中的LoadLoad屏障用來禁止處理器把上面的volatile讀與下面的普通讀重排序。LoadStore屏障用來禁止處理器把上面的volatile讀與下面的普通寫重排序。
上述volatile寫和volatile讀的記憶體屏障插入策略非常保守。在實際執行時,只要不改變volatile寫-讀的記憶體語義,編譯器可以根據具體情況省略不必要的屏障。
6、AQS
7、ReentrantLock
以公平鎖為例,看看 ReentrantLock 獲取鎖 & 釋放鎖的關鍵程式碼:
/**
* The synchronization state.
*/
private volatile int state;
/**
* Returns the current value of synchronization state.
* This operation has memory semantics of a {@code volatile} read.
* @return current state value
*/
protected final int getState() {
return state;
}
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);// 釋放鎖的最後,寫volatile變數state
return free;
}
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();// 獲取鎖的開始,首先讀volatile變數state
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}公平鎖在釋放鎖的最後寫volatile變數state,在獲取鎖時首先讀這個volatile變數。根據volatile的happens-before規則,釋放鎖的執行緒在寫volatile變數之前可見的共享變數,在獲取鎖的執行緒讀取同一個volatile變數後將立即變得對獲取鎖的執行緒可見。從而保證了程式碼段中變數(變數主要是指共享變數,存在競爭問題的變數)的可見性。
8、小結
如果我們仔細分析concurrent包的原始碼實現,會發現一個通用化的實現模式。
首先,宣告共享變數為volatile。
然後,使用CAS的原子條件更新來實現執行緒之間的同步。
同時,配合以volatile的讀/寫和CAS所具有的volatile讀和寫的記憶體語義來實現執行緒之間的通訊。
前文我們提到過,編譯器不會對volatile讀與volatile讀後面的任意記憶體操作重排序;編譯器不會對volatile寫與volatile寫前面的任意記憶體操作重排序。組合這兩個條件,意味著為了同時實現volatile讀和volatile寫的記憶體語義,編譯器不能對CAS與CAS前面和後面的任意記憶體操作重排序。
個人微信公眾號:
