
深入理解HTTP協議(轉)
1. 基礎概念篇
1.1 介紹
HTTP是Hyper Text Transfer Protocol(超文字傳輸協議)的縮寫。它的發展是全球資訊網協會(World Wide Web Consortium)和Internet工作小組IETF(Internet Engineering Task Force)合作的結果,(他們)最終釋出了一系列的RFC,RFC 1945定義了HTTP/1.0版本。其中最著名的就是RFC 2616。RFC 2616定義了今天普遍使用的一個版本——HTTP 1.1。
HTTP協議(HyperText Transfer Protocol,超文字傳輸協議)是用於從WWW伺服器傳輸超文字到本地瀏覽器的傳送協議。它可以使瀏覽器更加高效,使網路傳輸減少。它不僅保證計算機正確快速地傳輸超文字文件,還確定傳輸文件中的哪一部分,以及哪部分內容首先顯示(如文字先於圖形)等。
HTTP是一個應用層協議,由請求和響應構成,是一個標準的客戶端伺服器模型。HTTP是一個無狀態的協議。
1.2 在TCP/IP協議棧中的位置
HTTP協議通常承載於TCP協議之上,有時也承載於TLS或SSL協議層之上,這個時候,就成了我們常說的HTTPS。如下圖所示:
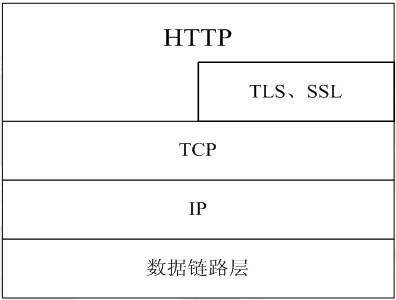
預設HTTP的埠號為80,HTTPS的埠號為443。
1.3 HTTP的請求響應模型
HTTP協議永遠都是客戶端發起請求,伺服器回送響應。見下圖:
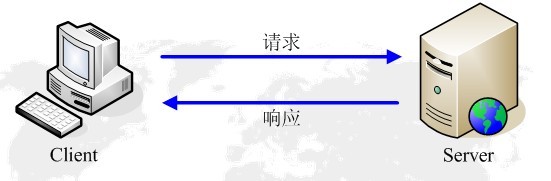
這樣就限制了使用HTTP協議,無法實現在客戶端沒有發起請求的時候,伺服器將訊息推送給客戶端。
HTTP協議是一個無狀態的協議,同一個客戶端的這次請求和上次請求是沒有對應關係。
1.4 工作流程
一次HTTP操作稱為一個事務,其工作過程可分為四步:
1)首先客戶機與伺服器需要建立連線。只要單擊某個超級連結,HTTP的工作開始。
2)建立連線後,客戶機發送一個請求給伺服器,請求方式的格式為:統一資源識別符號(URL)、協議版本號,後邊是MIME資訊包括請求修飾符、客戶機資訊和可能的內容。
3)伺服器接到請求後,給予相應的響應資訊,其格式為一個狀態行,包括資訊的協議版本號、一個成功或錯誤的程式碼,後邊是MIME資訊包括伺服器資訊、實體資訊和可能的內容。
4)客戶端接收伺服器所返回的資訊通過瀏覽器顯示在使用者的顯示屏上,然後客戶機與伺服器斷開連線。
如果在以上過程中的某一步出現錯誤,那麼產生錯誤的資訊將返回到客戶端,有顯示屏輸出。對於使用者來說,這些過程是由HTTP自己完成的,使用者只要用滑鼠點選,等待資訊顯示就可以了。
1.5 使用Wireshark抓TCP、http包
開啟Wireshark,選擇工具欄上的“Capture”->“Options”,介面選擇如圖1所示:
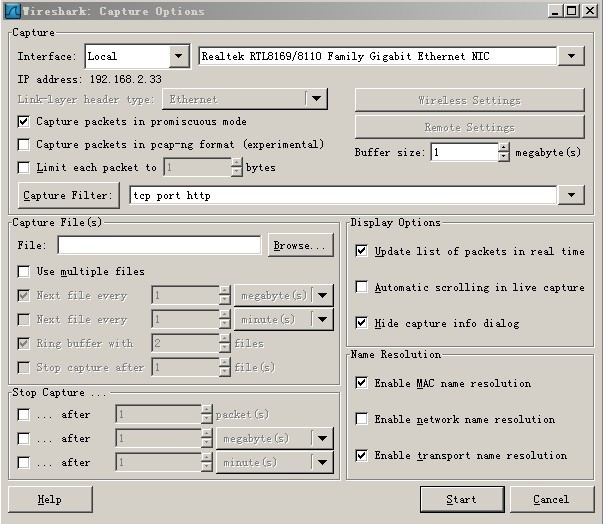
圖1 設定Capture選項
一般讀者只需要選擇最上邊的下拉框,選擇合適的Device,而後點選“Capture Filter”,此處選擇的是“HTTP TCP port(80)”,選擇後點擊上圖的“Start”開始抓包。
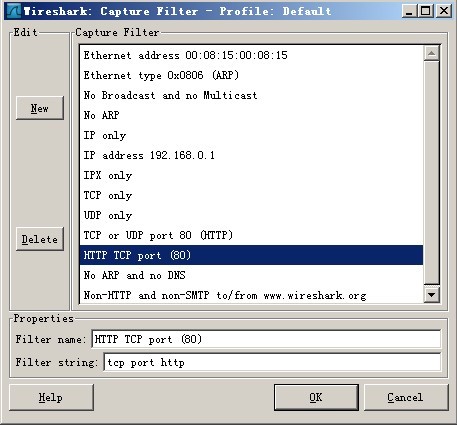
圖2 選擇Capture Filter
例如在瀏覽器中開啟http://image.baidu.com/,抓包如圖3所示:
http://www.blogjava.net/images/blogjava_net/amigoxie/40799/o_http%e5%8d%8f%e8%ae%ae%e5%ad%a6%e4%b9%a0-%e6%a6%82%e5%bf%b5-3.jpg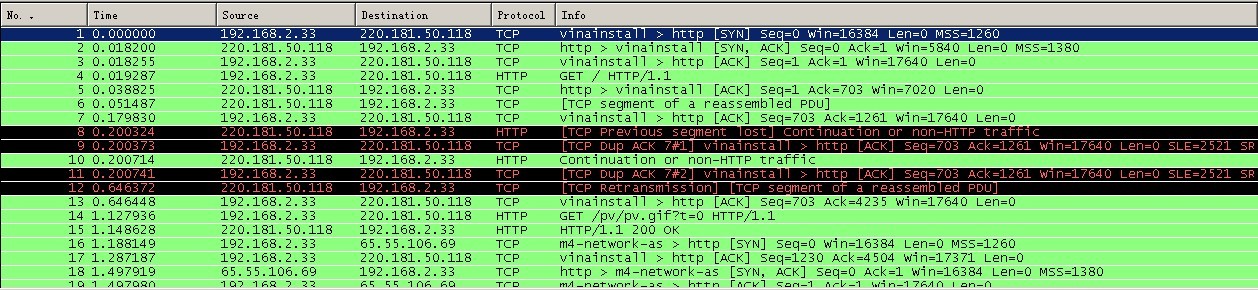
圖3 抓包
在上圖中,可清晰的看到客戶端瀏覽器(ip為192.168.2.33)與伺服器的互動過程:
1)No1:瀏覽器(192.168.2.33)向伺服器(220.181.50.118)發出連線請求。此為TCP三次握手第一步,此時從圖中可以看出,為SYN,seq:X (x=0)
2)No2:伺服器(220.181.50.118)迴應了瀏覽器(192.168.2.33)的請求,並要求確認,此時為:SYN,ACK,此時seq:y(y為0),ACK:x+1(為1)。此為三次握手的第二步;
3)No3:瀏覽器(192.168.2.33)迴應了伺服器(220.181.50.118)的確認,連線成功。為:ACK,此時seq:x+1(為1),ACK:y+1(為1)。此為三次握手的第三步;
4)No4:瀏覽器(192.168.2.33)發出一個頁面HTTP請求;
5)No5:伺服器(220.181.50.118)確認;
6)No6:伺服器(220.181.50.118)傳送資料;
7)No7:客戶端瀏覽器(192.168.2.33)確認;
8)No14:客戶端(192.168.2.33)發出一個圖片HTTP請求;
9)No15:伺服器(220.181.50.118)傳送狀態響應碼200 OK
……
1.6 頭域
每個頭域由一個域名,冒號(:)和域值三部分組成。域名是大小寫無關的,域值前可以新增任何數量的空格符,頭域可以被擴充套件為多行,在每行開始處,使用至少一個空格或製表符。
圖4 http請求訊息
迴應的訊息如圖5所示:
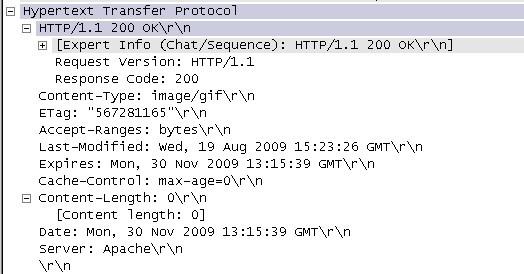
圖5 http狀態響應資訊
1.6.1 host頭域
Host頭域指定請求資源的Intenet主機和埠號,必須表示請求url的原始伺服器或閘道器的位置。HTTP/1.1請求必須包含主機頭域,否則系統會以400狀態碼返回。
圖5中host那行為:
![]()
1.6.2 Referer頭域
Referer頭域允許客戶端指定請求uri的源資源地址,這可以允許伺服器生成回退連結串列,可用來登陸、優化cache等。他也允許廢除的或錯誤的連線由於維護的目的被追蹤。如果請求的uri沒有自己的uri地址,Referer不能被髮送。如果指定的是部分uri地址,則此地址應該是一個相對地址。
在圖4中,Referer行的內容為:
![]()
1.6.3 User-Agent頭域
User-Agent頭域的內容包含發出請求的使用者資訊。
1.6.4 Cache-Control頭域
Cache-Control指定請求和響應遵循的快取機制。在請求訊息或響應訊息中設定Cache-Control並不會修改另一個訊息處理過程中的快取處理過程。請求時的快取指令包括no-cache、no-store、max-age、max-stale、min-fresh、only-if-cached,響應訊息中的指令包括public、private、no-cache、no-store、no-transform、must-revalidate、proxy-revalidate、max-age。
在圖5中的該頭域為:
![]()
1.6.5 Date頭域
Date頭域表示訊息傳送的時間,時間的描述格式由rfc822定義。例如,Date:Mon,31Dec200104:25:57GMT。Date描述的時間表示世界標準時,換算成本地時間,需要知道使用者所在的時區。
圖5中,該頭域如下圖所示:
![]()
1.7 HTTP的幾個重要概念
1.7.1連線:Connection
一個傳輸層的實際環流,它是建立在兩個相互通訊的應用程式之間。
在http1.1,request和reponse頭中都有可能出現一個connection的頭,此header的含義是當client和server通訊時對於長連結如何進行處理。
在http1.1中,client和server都是預設對方支援長連結的, 如果client使用http1.1協議,但又不希望使用長連結,則需要在header中指明connection的值為close;如果server方也不想支援長連結,則在response中也需要明確說明connection的值為close。不論request還是response的header中包含了值為close的connection,都表明當前正在使用的tcp連結在當天請求處理完畢後會被斷掉。以後client再進行新的請求時就必須建立新的tcp連結了。
1.7.2訊息:Message
HTTP通訊的基本單位,包括一個結構化的八元組序列並通過連線傳輸。
1.7.3請求:Request
一個從客戶端到伺服器的請求資訊包括應用於資源的方法、資源的識別符號和協議的版本號。
1.7.4響應:Response
一個從伺服器返回的資訊包括HTTP協議的版本號、請求的狀態(例如“成功”或“沒找到”)和文件的MIME型別。
1.7.5資源:Resource
由URI標識的網路資料物件或服務。
1.7.6實體:Entity
資料資源或來自服務資源的回映的一種特殊表示方法,它可能被包圍在一個請求或響應資訊中。一個實體包括實體頭資訊和實體的本身內容。
1.7.7客戶機:Client
一個為傳送請求目的而建立連線的應用程式。
1.7.8使用者代理:UserAgent
初始化一個請求的客戶機。它們是瀏覽器、編輯器或其它使用者工具。
1.7.9伺服器:Server
一個接受連線並對請求返回資訊的應用程式。
1.7.10源伺服器:Originserver
是一個給定資源可以在其上駐留或被建立的伺服器。
1.7.11代理:Proxy
一箇中間程式,它可以充當一個伺服器,也可以充當一個客戶機,為其它客戶機建立請求。請求是通過可能的翻譯在內部或經過傳遞到其它的伺服器中。一個代理在傳送請求資訊之前,必須解釋並且如果可能重寫它。
代理經常作為通過防火牆的客戶機端的門戶,代理還可以作為一個幫助應用來通過協議處理沒有被使用者代理完成的請求。
1.7.12閘道器:Gateway
一個作為其它伺服器中間媒介的伺服器。與代理不同的是,閘道器接受請求就好象對被請求的資源來說它就是源伺服器;發出請求的客戶機並沒有意識到它在同閘道器打交道。
閘道器經常作為通過防火牆的伺服器端的門戶,閘道器還可以作為一個協議翻譯器以便存取那些儲存在非HTTP系統中的資源。
1.7.13通道:Tunnel
是作為兩個連線中繼的中介程式。一旦啟用,通道便被認為不屬於HTTP通訊,儘管通道可能是被一個HTTP請求初始化的。當被中繼的連線兩端關閉時,通道便消失。當一個門戶(Portal)必須存在或中介(Intermediary)不能解釋中繼的通訊時通道被經常使用。
1.7.14快取:Cache
反應資訊的局域儲存。
附錄:參考資料
《分析TCP的三次握手》:
《使用Wireshark來檢測一次HTTP連線過程》:
http://blog.163.com/wangbo_tester/blog/static/12806792120098174162288/
《http協議中connection頭的作用》:
http://blog.csdn.net/barfoo/archive/2008/06/05/2514667.aspx2. 協議詳解篇
2.1 HTTP/1.0和HTTP/1.1的比較
RFC 1945定義了HTTP/1.0版本,RFC 2616定義了HTTP/1.1版本。
筆者在blog上提供了這兩個RFC中文版的下載地址。
RFC1945下載地址:
http://www.blogjava.net/Files/amigoxie/RFC1945(HTTP)中文版.rar
RFC2616下載地址:
http://www.blogjava.net/Files/amigoxie/RFC2616(HTTP)中文版.rar
2.1.1建立連線方面
HTTP/1.0 每次請求都需要建立新的TCP連線,連線不能複用。HTTP/1.1 新的請求可以在上次請求建立的TCP連線之上傳送,連線可以複用。優點是減少重複進行TCP三次握手的開銷,提高效率。
注意:在同一個TCP連線中,新的請求需要等上次請求收到響應後,才能傳送。
2.1.2 Host域
HTTP1.1在Request訊息頭裡頭多了一個Host域, HTTP1.0則沒有這個域。
Eg:
 GET /pub/WWW/TheProject.html HTTP/1.1 Host: www.w3.org
GET /pub/WWW/TheProject.html HTTP/1.1 Host: www.w3.org
可能HTTP1.0的時候認為,建立TCP連線的時候已經指定了IP地址,這個IP地址上只有一個host。
2.1.3日期時間戳
(接收方向)
無論是HTTP1.0還是HTTP1.1,都要能解析下面三種date/time stamp:
Sun, 06 Nov 1994 08:49:37 GMT ; RFC 822, updated by RFC 1123Sunday, 06-Nov-94 08:49:37 GMT ; RFC 850, obsoleted by RFC 1036Sun Nov 6 08:49:37 1994 ; ANSI C's asctime() format
(傳送方向)
HTTP1.0要求不能生成第三種asctime格式的date/time stamp;
HTTP1.1則要求只生成RFC 1123(第一種)格式的date/time stamp。
2.1.4狀態響應碼
狀態響應碼100 (Continue) 狀態程式碼的使用,允許客戶端在發request訊息body之前先用request header試探一下server,看server要不要接收request body,再決定要不要發request body。
客戶端在Request頭部中包含
Expect: 100-continue
Server看到之後呢如果回100 (Continue) 這個狀態程式碼,客戶端就繼續發request body。這個是HTTP1.1才有的。
另外在HTTP/1.1中還增加了101、203、205等等性狀態響應碼
2.1.5請求方式
HTTP1.1增加了OPTIONS, PUT, DELETE, TRACE, CONNECT這些Request方法.
Method = "OPTIONS" ; Section 9.2
| "GET" ; Section 9.3
| "HEAD" ; Section 9.4
| "POST" ; Section 9.5
| "PUT" ; Section 9.6
| "DELETE" ; Section 9.7
| "TRACE" ; Section 9.8
| "CONNECT" ; Section 9.9
| extension-method
extension-method = token
2.2 HTTP請求訊息
2.2.1請求訊息格式
請求訊息格式如下所示:
請求行
通用資訊頭|請求頭|實體頭
CRLF(回車換行)
實體內容
其中“請求行”為:請求行 = 方法 [空格] 請求URI [空格] 版本號 [回車換行]
請求行例項:
Eg1:
GET /index.html HTTP/1.1
Eg2:
HTTP請求訊息例項:
GET /hello.htm HTTP/1.1Accept: */*Accept-Language: zh-cnAccept-Encoding: gzip, deflateIf-Modified-Since: Wed, 17 Oct 2007 02:15:55 GMTIf-None-Match: W/"158-1192587355000"User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)Host: 192.168.2.162:8080Connection: Keep-Alive
2.2.2請求方法
HTTP的請求方法包括如下幾種:
q GET
q POST
q HEAD
q PUT
q DELETE
q OPTIONS
q TRACE
q CONNECT
2.3 HTTP響應訊息
2.3.1響應訊息格式
HTTP響應訊息的格式如下所示:
狀態行
通用資訊頭|響應頭|實體頭
CRLF
實體內容
其中:狀態行 = 版本號 [空格] 狀態碼 [空格] 原因 [回車換行]
狀態行舉例:
Eg1:
HTTP/1.0 200 OK
Eg2:
HTTP/1.1 400 Bad Request
HTTP響應訊息例項如下所示:
HTTP/1.1 200 OKETag: W/"158-1192590101000"Last-Modified: Wed, 17 Oct 2007 03:01:41 GMTContent-Type: text/htmlContent-Length: 158Date: Wed, 17 Oct 2007 03:01:59 GMTServer: Apache-Coyote/1.1
2.3.2 http的狀態響應碼
2.3.2.1 1**:請求收到,繼續處理
100——客戶必須繼續發出請求
101——客戶要求伺服器根據請求轉換HTTP協議版本
2.3.2.2 2**:操作成功收到,分析、接受
200——交易成功
201——提示知道新檔案的URL
202——接受和處理、但處理未完成
203——返回資訊不確定或不完整
204——請求收到,但返回資訊為空
205——伺服器完成了請求,使用者代理必須復位當前已經瀏覽過的檔案
206——伺服器已經完成了部分使用者的GET請求
2.3.2.3 3**:完成此請求必須進一步處理
300——請求的資源可在多處得到
301——刪除請求資料
302——在其他地址發現了請求資料
303——建議客戶訪問其他URL或訪問方式
304——客戶端已經執行了GET,但檔案未變化
305——請求的資源必須從伺服器指定的地址得到
306——前一版本HTTP中使用的程式碼,現行版本中不再使用
307——申明請求的資源臨時性刪除
2.3.2.4 4**:請求包含一個錯誤語法或不能完成
400——錯誤請求,如語法錯誤
401——未授權
HTTP 401.1 - 未授權:登入失敗
HTTP 401.2 - 未授權:伺服器配置問題導致登入失敗
HTTP 401.3 - ACL 禁止訪問資源
HTTP 401.4 - 未授權:授權被篩選器拒絕
HTTP 401.5 - 未授權:ISAPI 或 CGI 授權失敗
402——保留有效ChargeTo頭響應
403——禁止訪問
HTTP 403.1 禁止訪問:禁止可執行訪問
HTTP 403.2 - 禁止訪問:禁止讀訪問
HTTP 403.3 - 禁止訪問:禁止寫訪問
HTTP 403.4 - 禁止訪問:要求 SSL
HTTP 403.5 - 禁止訪問:要求 SSL 128
HTTP 403.6 - 禁止訪問:IP 地址被拒絕
HTTP 403.7 - 禁止訪問:要求客戶證書
HTTP 403.8 - 禁止訪問:禁止站點訪問
HTTP 403.9 - 禁止訪問:連線的使用者過多
HTTP 403.10 - 禁止訪問:配置無效
HTTP 403.11 - 禁止訪問:密碼更改
HTTP 403.12 - 禁止訪問:對映器拒絕訪問
HTTP 403.13 - 禁止訪問:客戶證書已被吊銷
HTTP 403.15 - 禁止訪問:客戶訪問許可過多
HTTP 403.16 - 禁止訪問:客戶證書不可信或者無效
HTTP 403.17 - 禁止訪問:客戶證書已經到期或者尚未生效
404——沒有發現檔案、查詢或URl
405——使用者在Request-Line欄位定義的方法不允許
406——根據使用者傳送的Accept拖,請求資源不可訪問
407——類似401,使用者必須首先在代理伺服器上得到授權
408——客戶端沒有在使用者指定的餓時間內完成請求
409——對當前資源狀態,請求不能完成
410——伺服器上不再有此資源且無進一步的參考地址
411——伺服器拒絕使用者定義的Content-Length屬性請求
412——一個或多個請求頭欄位在當前請求中錯誤
413——請求的資源大於伺服器允許的大小
414——請求的資源URL長於伺服器允許的長度
415——請求資源不支援請求專案格式
416——請求中包含Range請求頭欄位,在當前請求資源範圍內沒有range指示值,請求也不包含If-Range請求頭欄位
417——伺服器不滿足請求Expect頭欄位指定的期望值,如果是代理伺服器,可能是下一級伺服器不能滿足請求長。
2.3.2.5 5**:伺服器執行一個完全有效請求失敗
HTTP 500 - 內部伺服器錯誤
HTTP 500.100 - 內部伺服器錯誤 - ASP 錯誤
HTTP 500-11 伺服器關閉
HTTP 500-12 應用程式重新啟動
HTTP 500-13 - 伺服器太忙
HTTP 500-14 - 應用程式無效
HTTP 500-15 - 不允許請求 global.asa
Error 501 - 未實現
HTTP 502 - 閘道器錯誤
2.4 使用telnet進行http測試
在Windows下,可使用命令視窗進行http簡單測試。
輸入cmd進入命令視窗,在命令列鍵入如下命令後按回車:
telnet www.baidu.com 80
而後在視窗中按下“Ctrl+]”後按回車可讓返回結果回顯。
接著開始發請求訊息,例如傳送如下請求訊息請求baidu的首頁訊息,使用的HTTP協議為HTTP/1.1:
GET /index.html HTTP/1.1
注意:copy如上的訊息到命令視窗後需要按兩個回車換行才能得到響應的訊息,第一個回車換行是在命令後鍵入回車換行,是HTTP協議要求的。第二個是確認輸入,傳送請求。
可看到返回了200 OK的訊息,如下圖所示: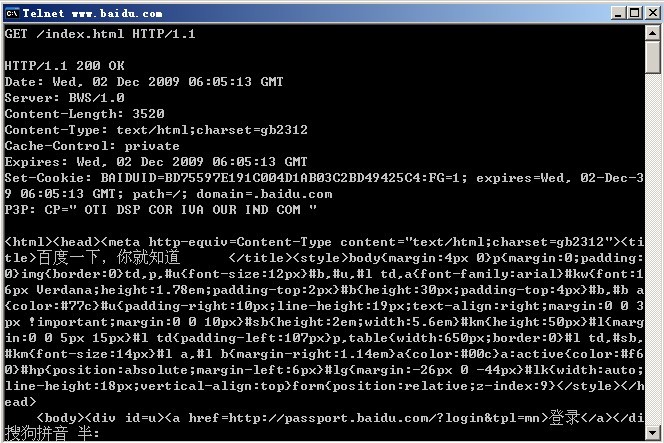
可看到,當採用HTTP/1.1時,連線不是在請求結束後就斷開的。若採用HTTP1.0,在命令視窗鍵入:
GET /index.html HTTP/1.0
此時可以看到請求結束之後馬上斷開。
讀者還可以嘗試在使用GET或POST等時,帶上頭域資訊,例如鍵入如下資訊:
GET /index.html HTTP/1.1connection: closeHost: www.baidu.com
2.5 常用的請求方式
常用的請求方式是GET和POST.
l GET方式:是以實體的方式得到由請求URI所指定資源的資訊,如果請求URI只是一個數據產生過程,那麼最終要在響應實體中返回的是處理過程的結果所指向的資源,而不是處理過程的描述。
l POST方式:用來向目的伺服器發出請求,要求它接受被附在請求後的實體,並把它當作請求佇列中請求URI所指定資源的附加新子項,Post被設計成用統一的方法實現下列功能:
1:對現有資源的解釋;
2:向電子公告欄、新聞組、郵件列表或類似討論組發信息;
3:提交資料塊;
4:通過附加操作來擴充套件資料庫 。
從上面描述可以看出,Get是向伺服器發索取資料的一種請求;而Post是向伺服器提交資料的一種請求,要提交的資料位於資訊頭後面的實體中。
GET與POST方法有以下區別:
(1) 在客戶端,Get方式在通過URL提交資料,資料在URL中可以看到;POST方式,資料放置在HTML HEADER內提交。
(2) GET方式提交的資料最多隻能有1024位元組,而POST則沒有此限制。
(3) 安全性問題。正如在(1)中提到,使用 Get 的時候,引數會顯示在位址列上,而 Post 不會。所以,如果這些資料是中文資料而且是非敏感資料,那麼使用 get;如果使用者輸入的資料不是中文字元而且包含敏感資料,那麼還是使用 post為好。
(4) 安全的和冪等的。所謂安全的意味著該操作用於獲取資訊而非修改資訊。冪等的意味著對同一 URL 的多個請求應該返回同樣的結果。完整的定義並不像看起來那樣嚴格。換句話說,GET 請求一般不應產生副作用。從根本上講,其目標是當用戶開啟一個連結時,她可以確信從自身的角度來看沒有改變資源。比如,新聞站點的頭版不斷更新。雖然第二次請求會返回不同的一批新聞,該操作仍然被認為是安全的和冪等的,因為它總是返回當前的新聞。反之亦然。POST 請求就不那麼輕鬆了。POST 表示可能改變伺服器上的資源的請求。仍然以新聞站點為例,讀者對文章的註解應該通過
POST 請求實現,因為在註解提交之後站點已經不同了(比方說文章下面出現一條註解)。
2.6 請求頭
HTTP最常見的請求頭如下:
l Accept:瀏覽器可接受的MIME型別;
l Accept-Charset:瀏覽器可接受的字符集;
l Accept-Encoding:瀏覽器能夠進行解碼的資料編碼方式,比如gzip。Servlet能夠向支援gzip的瀏覽器返回經gzip編碼的HTML頁面。許多情形下這可以減少5到10倍的下載時間;
l Accept-Language:瀏覽器所希望的語言種類,當伺服器能夠提供一種以上的語言版本時要用到;
l Authorization:授權資訊,通常出現在對伺服器傳送的WWW-Authenticate頭的應答中;
l Connection:表示是否需要持久連線。如果Servlet看到這裡的值為“Keep-Alive”,或者看到請求使用的是HTTP 1.1(HTTP 1.1預設進行持久連線),它就可以利用持久連線的優點,當頁面包含多個元素時(例如Applet,圖片),顯著地減少下載所需要的時間。要實現這一點,Servlet需要在應答中傳送一個Content-Length頭,最簡單的實現方法是:先把內容寫入ByteArrayOutputStream,然後在正式寫出內容之前計算它的大小;
l Content-Length:表示請求訊息正文的長度;
l Cookie:這是最重要的請求頭資訊之一;
l From:請求傳送者的email地址,由一些特殊的Web客戶程式使用,瀏覽器不會用到它;
l Host:初始URL中的主機和埠;
l If-Modified-Since:只有當所請求的內容在指定的日期之後又經過修改才返回它,否則返回304“Not Modified”應答;
l Pragma:指定“no-cache”值表示伺服器必須返回一個重新整理後的文件,即使它是代理伺服器而且已經有了頁面的本地拷貝;
l Referer:包含一個URL,使用者從該URL代表的頁面出發訪問當前請求的頁面。
l User-Agent:瀏覽器型別,如果Servlet返回的內容與瀏覽器型別有關則該值非常有用;
l UA-Pixels,UA-Color,UA-OS,UA-CPU:由某些版本的IE瀏覽器所傳送的非標準的請求頭,表示螢幕大小、顏色深度、作業系統和CPU型別。
2.7 響應頭
HTTP最常見的響應頭如下所示:
l Allow:伺服器支援哪些請求方法(如GET、POST等);
l Content-Encoding:文件的編碼(Encode)方法。只有在解碼之後才可以得到Content-Type頭指定的內容型別。利用gzip壓縮文件能夠顯著地減少HTML文件的下載時間。Java的GZIPOutputStream可以很方便地進行gzip壓縮,但只有Unix上的Netscape和Windows上的IE 4、IE 5才支援它。因此,Servlet應該通過檢視Accept-Encoding頭(即request.getHeader("Accept-Encoding"))檢查瀏覽器是否支援gzip,為支援gzip的瀏覽器返回經gzip壓縮的HTML頁面,為其他瀏覽器返回普通頁面;
l Content-Length:表示內容長度。只有當瀏覽器使用持久HTTP連線時才需要這個資料。如果你想要利用持久連線的優勢,可以把輸出文件寫入ByteArrayOutputStram,完成後檢視其大小,然後把該值放入Content-Length頭,最後通過byteArrayStream.writeTo(response.getOutputStream()傳送內容;
l Content-Type: 表示後面的文件屬於什麼MIME型別。Servlet預設為text/plain,但通常需要顯式地指定為text/html。由於經常要設定Content-Type,因此HttpServletResponse提供了一個專用的方法setContentTyep。 可在web.xml檔案中配置副檔名和MIME型別的對應關係;
l Date:當前的GMT時間。你可以用setDateHeader來設定這個頭以避免轉換時間格式的麻煩;
l Expires:指明應該在什麼時候認為文件已經過期,從而不再快取它。
l Last-Modified:文件的最後改動時間。客戶可以通過If-Modified-Since請求頭提供一個日期,該請求將被視為一個條件GET,只有改動時間遲於指定時間的文件才會返回,否則返回一個304(Not Modified)狀態。Last-Modified也可用setDateHeader方法來設定;
l Location:表示客戶應當到哪裡去提取文件。Location通常不是直接設定的,而是通過HttpServletResponse的sendRedirect方法,該方法同時設定狀態程式碼為302;
l Refresh:表示瀏覽器應該在多少時間之後重新整理文件,以秒計。除了重新整理當前文件之外,你還可以通過setHeader("Refresh", "5; URL=http://host/path")讓瀏覽器讀取指定的頁面。注意這種功能通常是通過設定HTML頁面HEAD區的<META HTTP-EQUIV="Refresh" CONTENT="5;URL=http://host/path">實現,這是因為,自動重新整理或重定向對於那些不能使用CGI或Servlet的HTML編寫者十分重要。但是,對於Servlet來說,直接設定Refresh頭更加方便。注意Refresh的意義是“N秒之後重新整理本頁面或訪問指定頁面”,而不是“每隔N秒重新整理本頁面或訪問指定頁面”。因此,連續重新整理要求每次都發送一個Refresh頭,而傳送204狀態程式碼則可以阻止瀏覽器繼續重新整理,不管是使用Refresh頭還是<META HTTP-EQUIV="Refresh" ...>。注意Refresh頭不屬於HTTP 1.1正式規範的一部分,而是一個擴充套件,但Netscape和IE都支援它。
2.8實體頭
實體頭用坐實體內容的元資訊,描述了實體內容的屬性,包括實體資訊型別,長度,壓縮方法,最後一次修改時間,資料有效性等。
l Allow:GET,POST
l Content-Encoding:文件的編碼(Encode)方法,例如:gzip,見“2.5 響應頭”;
l Content-Language:內容的語言型別,例如:zh-cn;
l Content-Length:表示內容長度,eg:80,可參考“2.5響應頭”;
l Content-Location:表示客戶應當到哪裡去提取文件,例如:http://www.dfdf.org/dfdf.html,可參考“2.5響應頭”;
l Content-MD5:MD5 實體的一種MD5摘要,用作校驗和。傳送方和接受方都計算MD5摘要,接受方將其計算的值與此頭標中傳遞的值進行比較。Eg1:Content-MD5: <base64 of 128 MD5 digest>。Eg2:dfdfdfdfdfdfdff==;
l Content-Range:隨部分實體一同傳送;標明被插入位元組的低位與高位位元組偏移,也標明此實體的總長度。Eg1:Content-Range: 1001-2000/5000,eg2:bytes 2543-4532/7898
l Content-Type:標明發送或者接收的實體的MIME型別。Eg:text/html; charset=GB2312 主型別/子型別;
l Expires:為0證明不快取;
l Last-Modified:WEB 伺服器認為物件的最後修改時間,比如檔案的最後修改時間,動態頁面的最後產生時間等等。例如:Last-Modified:Tue, 06 May 2008 02:42:43 GMT.
2.8擴充套件頭
在HTTP訊息中,也可以使用一些再HTTP1.1正式規範裡沒有定義的頭欄位,這些頭欄位統稱為自定義的HTTP頭或者擴充套件頭,他們通常被當作是一種實體頭處理。
現在流行的瀏覽器實際上都支援Cookie,Set-Cookie,Refresh和Content-Disposition等幾個常用的擴充套件頭欄位。
l Refresh:1;url=http://www.dfdf.org //過1秒跳轉到指定位置;
l Content-Disposition:頭欄位,可參考“2.5響應頭”;
l Content-Type:WEB 伺服器告訴瀏覽器自己響應的物件的型別。
eg1:Content-Type:application/xml ;
eg2:applicaiton/octet-stream;
Content-Disposition:attachment; filename=aaa.zip。
附錄:參考資料
《HTTP1.1和HTTP1.0的區別》:
《HTTP請求(GET和POST區別)和響應》:
《HTTP請求頭概述_百度知道》:
《實體頭和擴充套件頭》:
3. 深入瞭解篇3.1 Cookie和Session
Cookie和Session都為了用來儲存狀態資訊,都是儲存客戶端狀態的機制,它們都是為了解決HTTP無狀態的問題而所做的努力。
Session可以用Cookie來實現,也可以用URL回寫的機制來實現。用Cookie來實現的Session可以認為是對Cookie更高階的應用。
3.1.1兩者比較
Cookie和Session有以下明顯的不同點:
1)Cookie將狀態儲存在客戶端,Session將狀態儲存在伺服器端;
2)Cookies是伺服器在本地機器上儲存的小段文字並隨每一個請求傳送至同一個伺服器。Cookie最早在RFC2109中實現,後續RFC2965做了增強。網路伺服器用HTTP頭向客戶端傳送cookies,在客戶終端,瀏覽器解析這些cookies並將它們儲存為一個本地檔案,它會自動將同一伺服器的任何請求縛上這些cookies。Session並沒有在HTTP的協議中定義;
3)Session是針對每一個使用者的,變數的值儲存在伺服器上,用一個sessionID來區分是哪個使用者session變數,這個值是通過使用者的瀏覽器在訪問的時候返回給伺服器,當客戶禁用cookie時,這個值也可能設定為由get來返回給伺服器;
4)就安全性來說:當你訪問一個使用session 的站點,同時在自己機子上建立一個cookie,建議在伺服器端的SESSION機制更安全些.因為它不會任意讀取客戶儲存的資訊。
3.1.2 Session機制
Session機制是一種伺服器端的機制,伺服器使用一種類似於散列表的結構(也可能就是使用散列表)來儲存資訊。
當程式需要為某個客戶端的請求建立一個session的時候,伺服器首先檢查這個客戶端的請求裡是否已包含了一個session標識 - 稱為 session id,如果已包含一個session id則說明以前已經為此客戶端建立過session,伺服器就按照session id把這個 session檢索出來使用(如果檢索不到,可能會新建一個),如果客戶端請求不包含session id,則為此客戶端建立一個session並且生成一個與此session相關聯的session id,session id的值應該是一個既不會重複,又不容易被找到規律以仿造的字串,這個 session id將被在本次響應中返回給客戶端儲存。
3.1.6 Session的實現方式
3.1.6.1 使用Cookie來實現
伺服器給每個Session分配一個唯一的JSESSIONID,並通過Cookie傳送給客戶端。
當客戶端發起新的請求的時候,將在Cookie頭中攜帶這個JSESSIONID。這樣伺服器能夠找到這個客戶端對應的Session。
流程如下圖所示:

3.1.6.2 使用URL回顯來實現
URL回寫是指伺服器在傳送給瀏覽器頁面的所有連結中都攜帶JSESSIONID的引數,這樣客戶端點選任何一個連結都會把JSESSIONID帶會伺服器。
如果直接在瀏覽器輸入服務端資源的url來請求該資源,那麼Session是匹配不到的。
Tomcat對Session的實現,是一開始同時使用Cookie和URL回寫機制,如果發現客戶端支援Cookie,就繼續使用Cookie,停止使用URL回寫。如果發現Cookie被禁用,就一直使用URL回寫。jsp開發處理到Session的時候,對頁面中的連結記得使用response.encodeURL() 。
3.1.3在J2EE專案中Session失效的幾種情況
1)Session超時:Session在指定時間內失效,例如30分鐘,若在30分鐘內沒有操作,則Session會失效,例如在web.xml中進行了如下設定:
<session-config>
<session-timeout>30</session-timeout> //單位:分鐘
</session-config>
2)使用session.invalidate()明確的去掉Session。
3.1.4與Cookie相關的HTTP擴充套件頭
1)Cookie:客戶端將伺服器設定的Cookie返回到伺服器;
2)Set-Cookie:伺服器向客戶端設定Cookie;
3)Cookie2 (RFC2965)):客戶端指示伺服器支援Cookie的版本;
4)Set-Cookie2 (RFC2965):伺服器向客戶端設定Cookie。
3.1.5Cookie的流程
伺服器在響應訊息中用Set-Cookie頭將Cookie的內容回送給客戶端,客戶端在新的請求中將相同的內容攜帶在Cookie頭中傳送給伺服器。從而實現會話的保持。
流程如下圖所示: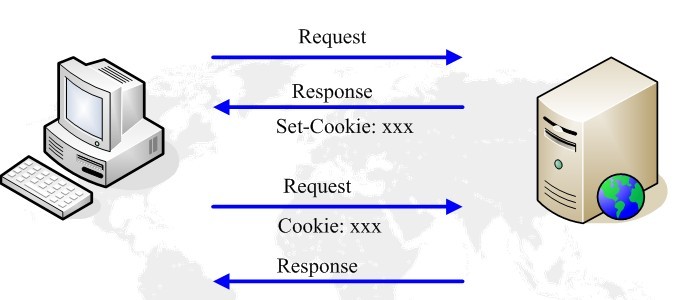
3.2 快取的實現原理
3.2.1什麼是Web快取
WEB快取(cache)位於Web伺服器和客戶端之間。
快取會根據請求儲存輸出內容的副本,例如html頁面,圖片,檔案,當下一個請求來到的時候:如果是相同的URL,快取直接使用副本響應訪問請求,而不是向源伺服器再次傳送請求。
HTTP協議定義了相關的訊息頭來使WEB快取儘可能好的工作。
3.2.2快取的優點
q 減少相應延遲:因為請求從快取伺服器(離客戶端更近)而不是源伺服器被相應,這個過程耗時更少,讓web伺服器看上去相應更快。
q 減少網路頻寬消耗:當副本被重用時會減低客戶端的頻寬消耗;客戶可以節省頻寬費用,控制頻寬的需求的增長並更易於管理。
3.2.3與快取相關的HTTP擴充套件訊息頭
q Expires:指示響應內容過期的時間,格林威治時間GMT
q Cache-Control:更細緻的控制快取的內容
q Last-Modified:響應中資源最後一次修改的時間
q ETag:響應中資源的校驗值,在伺服器上某個時段是唯一標識的。
q Date:伺服器的時間
q If-Modified-Since:客戶端存取的該資源最後一次修改的時間,同Last-Modified。
q If-None-Match:客戶端存取的該資源的檢驗值,同ETag。
3.2.4客戶端快取生效的常見流程
伺服器收到請求時,會在200OK中回送該資源的Last-Modified和ETag頭,客戶端將該資源儲存在cache中,並記錄這兩個屬性。當客戶端需要傳送相同的請求時,會在請求中攜帶If-Modified-Since和If-None-Match兩個頭。兩個頭的值分別是響應中Last-Modified和ETag頭的值。伺服器通過這兩個頭判斷本地資源未發生變化,客戶端不需要重新下載,返回304響應。常見流程如下圖所示:
3.2.5 Web快取機制
HTTP/1.1中快取的目的是為了在很多情況下減少傳送請求,同時在許多情況下可以不需要傳送完整響應。前者減少了網路迴路的數量;HTTP利用一個“過期(expiration)”機制來為此目的。後者減少了網路應用的頻寬;HTTP用“驗證(validation)”機制來為此目的。
HTTP定義了3種快取機制:
1)Freshness:允許一個迴應訊息可以在源伺服器不被重新檢查,並且可以由伺服器和客戶端來控制。例如,Expires迴應頭給了一個文件不可用的時間。Cache-Control中的max-age標識指明瞭快取的最長時間;
2)Validation:用來檢查以一個快取的迴應是否仍然可用。例如,如果一個迴應有一個Last-Modified迴應頭,快取能夠使用If-Modified-Since來判斷是否已改變,以便判斷根據情況傳送請求;
3)Invalidation: 在另一個請求通過快取的時候,常常有一個副作用。例如,如果一個URL關聯到一個快取迴應,但是其後跟著POST、PUT和DELETE的請求的話,快取就會過期。
3.3 斷點續傳和多執行緒下載的實現原理
q HTTP協議的GET方法,支援只請求某個資源的某一部分;
q 206 Partial Content 部分內容響應;
q Range 請求的資源範圍;
q Content-Range 響應的資源範圍;
q 在連線斷開重連時,客戶端只請求該資源未下載的部分,而不是重新請求整個資源,來實現斷點續傳。
分塊請求資源例項:
Eg1:Range: bytes=306302- :請求這個資源從306302個位元組到末尾的部分;
Eg2:Content-Range: bytes 306302-604047/604048:響應中指示攜帶的是該資源的第306302-604047的位元組,該資源共604048個位元組;
客戶端通過併發的請求相同資源的不同片段,來實現對某個資源的併發分塊下載。從而達到快速下載的目的。目前流行的FlashGet和迅雷基本都是這個原理。
多執行緒下載的原理:
q 下載工具開啟多個發出HTTP請求的執行緒;
q 每個http請求只請求資原始檔的一部分:Content-Range: bytes 20000-40000/47000;
q 合併每個執行緒下載的檔案。
3.4 https通訊過程
3.4.1什麼是https
HTTPS(全稱:Hypertext Transfer Protocol over Secure Socket Layer),是以安全為目標的HTTP通道,簡單講是HTTP的安全版。即HTTP下加入SSL層,HTTPS的安全基礎是SSL,因此加密的詳細內容請看SSL。
見下圖:

https所用的埠號是443。
3.4.2 https的實現原理
有兩種基本的加解密演算法型別:
1)對稱加密:金鑰只有一個,加密解密為同一個密碼,且加解密速度快,典型的對稱加密演算法有DES、AES等;
2)非對稱加密:金鑰成對出現(且根據公鑰無法推知私鑰,根據私鑰也無法推知公鑰),加密解密使用不同金鑰(公鑰加密需要私鑰解密,私鑰加密需要公鑰解密),相對對稱加密速度較慢,典型的非對稱加密演算法有RSA、DSA等。
下面看一下https的通訊過程:
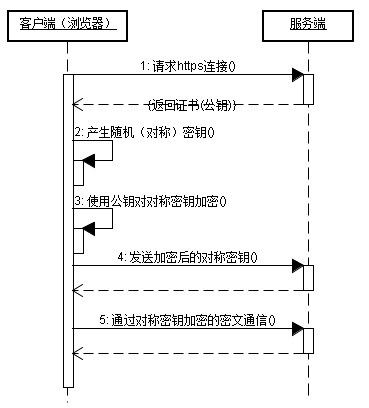
https通訊的優點:
1)客戶端產生的金鑰只有客戶端和伺服器端能得到;
2)加密的資料只有客戶端和伺服器端才能得到明文;
3)客戶端到服務端的通訊是安全的。
3.5 http代理
3.5.1 http代理伺服器
代理伺服器英文全稱是Proxy Server,其功能就是代理網路使用者去取得網路資訊。形象的說:它是網路資訊的中轉站。
代理伺服器是介於瀏覽器和Web伺服器之間的一臺伺服器,有了它之後,瀏覽器不是直接到Web伺服器去取回網頁而是向代理伺服器發出請求,Request訊號會先送到代理伺服器,由代理伺服器來取回瀏覽器所需要的資訊並傳送給你的瀏覽器。
而且,大部分代理伺服器都具有緩衝的功能,就好象一個大的Cache,它有很大的儲存空間,它不斷將新取得資料儲存到它本機的儲存器上,如果瀏覽器所請求的資料在它本機的儲存器上已經存在而且是最新的,那麼它就不重新從Web伺服器取資料,而直接將儲存器上的資料傳送給使用者的瀏覽器,這樣就能顯著提高瀏覽速度和效率。
更重要的是:Proxy Server(代理伺服器)是Internet鏈路級閘道器所提供的一種重要的安全功能,它的工作主要在開放系統互聯(OSI)模型的對話層。
3.5.2 http代理伺服器的主要功能
主要功能如下:
1)突破自身IP訪問限制,訪問國外站點。如:教育網、169網等網路使用者可以通過代理訪問國外網站;
2)訪問一些單位或團體內部資源,如某大學FTP(前提是該代理地址在該資源的允許訪問範圍之內),使用教育網內地址段免費代理伺服器,就可以用於對教育 網開放的各類FTP下載上傳,以及各類資料查詢共享等服務;
3)突破中國電信的IP封鎖:中國電信使用者有很多網站是被限制訪問的,這種限制是人為的,不同Serve對地址的封鎖是不同的。所以不能訪問時可以換一個國 外的代理伺服器試試;
4)提高訪問速度:通常代理伺服器都設定一個較大的硬碟緩衝區,當有外界的資訊通過時,同時也將其儲存到緩衝區中,當其他使用者再訪問相同的資訊時, 則直接由緩衝區中取出資訊,傳給使用者,以提高訪問速度;
5)隱藏真實IP:上網者也可以通過這種方法隱藏自己的IP,免受攻擊。
3.5.3 http代理圖示
http代理的圖示見下圖:
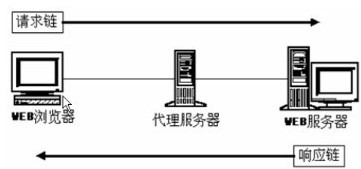
對於客戶端瀏覽器而言,http代理伺服器相當於伺服器。
而對於Web伺服器而言,http代理伺服器又擔當了客戶端的角色。
3.6 虛擬主機的實現
3.6.1什麼是虛擬主機
虛擬主機:是在網路伺服器上劃分出一定的磁碟空間供使用者放置站點、應用元件等,提供必要的站點功能與資料存放、傳輸功能。
所謂虛擬主機,也叫“網站空間”就是把一臺執行在網際網路上的伺服器劃分成多個“虛擬”的伺服器,每一個虛擬主機都具有獨立的域名和完整的Internet伺服器(支援WWW、FTP、E-mail等)功能。一臺伺服器上的不同虛擬主機是各自獨立的,並由使用者自行管理。但一臺伺服器主機只能夠支援一定數量的虛擬主機,當超過這個數量時,使用者將會感到效能急劇下降。
3.6.2虛擬主機的實現原理
虛擬主機是用同一個WEB伺服器,為不同域名網站提供服務的技術。Apache、Tomcat等均可通過配置實現這個功能。
相關的HTTP訊息頭:Host。
客戶端傳送HTTP請求的時候,會攜帶Host頭,Host頭記錄的是客戶端輸入的域名。這樣伺服器可以根據Host頭確認客戶要訪問的是哪一個域名。
附錄:參考資料
《理解Cookie和Session機制》:
《淺析HTTP協議》:
《http代理_百度百科》:
《虛擬主機_百度百科》:
《https_百度百科》: