
Java常見面試題(二)JAVA集合類
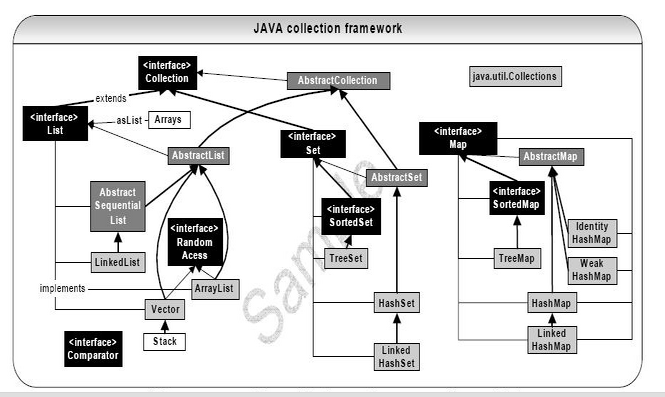
JAVA集合類圖:
1. hashmap原理,與hashtable區別
Java中的HashMap是以鍵值對(key-value)的形式儲存元素的。HashMap需要一個hash函式,它使用hashCode()和equals()方法來向集合/從集合新增和檢索元素。當呼叫put()方法的時候,HashMap會計算key的hash值,然後把鍵值對儲存在集合中合適的索引上。如果key已經存在了,value會被更新成新值。HashMap的一些重要的特性是它的容量(capacity),負載因子(load factor)和擴容極限(threshold resizing)。附上put的原始碼:
addEntry:public V put(K key, V value) { // HashMap允許存放null鍵和null值。 // 當key為null時,呼叫putForNullKey方法,將value放置在陣列第一個位置。 if (key == null) return putForNullKey(value); // 根據key的keyCode重新計算hash值。 int hash = hash(key.hashCode()); // 搜尋指定hash值在對應table中的索引。 int i = indexFor(hash, table.length); // 如果 i 索引處的 Entry 不為 null,通過迴圈不斷遍歷 e 元素的下一個元素。 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } // 如果i索引處的Entry為null,表明此處還沒有Entry。 modCount++; //這個mod是用於執行緒安全的,下文有講述 // 將key、value新增到i索引處。 addEntry(hash, key, value, i); return null; }
void addEntry(int hash, K key, V value, int bucketIndex) { // 獲取指定 bucketIndex 索引處的 Entry Entry<K,V> e = table[bucketIndex]; // <strong><span style="color:#ff0000;">將新建立的 Entry 放入 bucketIndex 索引處,並讓新的 Entry 指向原來的 Entry </span></strong> table[bucketIndex] = new Entry<K,V>(hash, key, value, e); // 如果 Map 中的 key-value 對的數量超過了極限 if (size++ >= threshold) // 把 table 物件的長度擴充到原來的2倍。 resize(2 * table.length); }
更詳細的原理請看: http://zhangshixi.iteye.com/blog/672697
區別:
http://blog.csdn.net/shohokuf/article/details/3932967
- HashMap允許鍵和值是null,而Hashtable不允許鍵或者值是null。
- Hashtable是同步的,而HashMap不是。因此,HashMap更適合於單執行緒環境,而Hashtable適合於多執行緒環境。
- HashMap提供了可供應用迭代的鍵的集合,因此,HashMap是快速失敗(具體看下文)的。另一方面,Hashtable提供了對鍵的列舉(Enumeration)。
- 一般認為Hashtable是一個遺留的類。
- 一般認為Hashtable是一個遺留的類。
2.讓hashmap變成執行緒安全的兩種方法
方法一:通過Collections.synchronizedMap()返回一個新的Map,這個新的map就是執行緒安全的. 這個要求大家習慣基於介面程式設計,因為返回的並不是HashMap,而是一個Map的實現.
Map map = Collections.synchronizedMap(new HashMap());方法二:使用ConcurrentHashMap
Map<String, Integer> concurrentHashMap = new ConcurrentHashMap<String, Integer>(); 3.ArrayList也是非執行緒安全的
一個 ArrayList 類,在新增一個元素的時候,它可能會有兩步來完成:1. 在 Items[Size] 的位置存放此元素;2. 增大 Size 的值。在單執行緒執行的情況下,如果 Size = 0,新增一個元素後,此元素在位置 0,而且 Size=1;
而如果是在多執行緒情況下,比如有兩個執行緒,執行緒 A 先將元素存放在位置 0。但是此時 CPU 排程執行緒A暫停,執行緒 B 得到執行的機會。執行緒B也將元素放在位置0,(因為size還未增長),完了之後,兩個執行緒都是size++,結果size變成2,而只有 items[0]有元素。
util.concurrent包也提供了一個執行緒安全的ArrayList替代者CopyOnWriteArrayList。
4. hashset原理
基於HashMap實現的,HashSet底層使用HashMap來儲存所有元素(看了原始碼之後我發現就是用hashmap的keyset來儲存的),因此HashSet 的實現比較簡單,相關HashSet的操作,基本上都是直接呼叫底層HashMap的相關方法來完成, HashSet的原始碼如下:public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
// 底層使用HashMap來儲存HashSet中所有元素。
private transient HashMap<E,Object> map;
// 定義一個虛擬的Object物件作為HashMap的value,將此物件定義為static final。
private static final Object PRESENT = new Object();
/**
* 預設的無參構造器,構造一個空的HashSet。
*
* 實際底層會初始化一個空的HashMap,並使用預設初始容量為16和載入因子0.75。
*/
public HashSet() {
map = new HashMap<E,Object>();
}
/**
* 構造一個包含指定collection中的元素的新set。
*
* 實際底層使用預設的載入因子0.75和足以包含指定
* collection中所有元素的初始容量來建立一個HashMap。
* @param c 其中的元素將存放在此set中的collection。
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<E,Object>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* 以指定的initialCapacity和loadFactor構造一個空的HashSet。
*
* 實際底層以相應的引數構造一個空的HashMap。
* @param initialCapacity 初始容量。
* @param loadFactor 載入因子。
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<E,Object>(initialCapacity, loadFactor);
}
/**
* 以指定的initialCapacity構造一個空的HashSet。
*
* 實際底層以相應的引數及載入因子loadFactor為0.75構造一個空的HashMap。
* @param initialCapacity 初始容量。
*/
public HashSet(int initialCapacity) {
map = new HashMap<E,Object>(initialCapacity);
}
/**
* 以指定的initialCapacity和loadFactor構造一個新的空連結雜湊集合。
* 此建構函式為包訪問許可權,不對外公開,實際只是是對LinkedHashSet的支援。
*
* 實際底層會以指定的引數構造一個空LinkedHashMap例項來實現。
* @param initialCapacity 初始容量。
* @param loadFactor 載入因子。
* @param dummy 標記。
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<E,Object>(initialCapacity, loadFactor);
}
/**
* 返回對此set中元素進行迭代的迭代器。返回元素的順序並不是特定的。
*
* 底層實際呼叫底層HashMap的keySet來返回所有的key。
* 可見HashSet中的元素,只是存放在了底層HashMap的key上,
* value使用一個static final的Object物件標識。
* @return 對此set中元素進行迭代的Iterator。
*/
public Iterator<E> iterator() {
return map.keySet().iterator();
}
/**
* 返回此set中的元素的數量(set的容量)。
*
* 底層實際呼叫HashMap的size()方法返回Entry的數量,就得到該Set中元素的個數。
* @return 此set中的元素的數量(set的容量)。
*/
public int size() {
return map.size();
}
/**
* 如果此set不包含任何元素,則返回true。
*
* 底層實際呼叫HashMap的isEmpty()判斷該HashSet是否為空。
* @return 如果此set不包含任何元素,則返回true。
*/
public boolean isEmpty() {
return map.isEmpty();
}
/**
* 如果此set包含指定元素,則返回true。
* 更確切地講,當且僅當此set包含一個滿足(o==null ? e==null : o.equals(e))
* 的e元素時,返回true。
*
* 底層實際呼叫HashMap的containsKey判斷是否包含指定key。
* @param o 在此set中的存在已得到測試的元素。
* @return 如果此set包含指定元素,則返回true。
*/
public boolean contains(Object o) {
return map.containsKey(o);
}
/**
* 如果此set中尚未包含指定元素,則新增指定元素。
* 更確切地講,如果此 set 沒有包含滿足(e==null ? e2==null : e.equals(e2))
* 的元素e2,則向此set 新增指定的元素e。
* 如果此set已包含該元素,則該呼叫不更改set並返回false。
*
* 底層實際將將該元素作為key放入HashMap。
* 由於HashMap的put()方法新增key-value對時,當新放入HashMap的Entry中key
* 與集合中原有Entry的key相同(hashCode()返回值相等,通過equals比較也返回true),
* 新新增的Entry的value會將覆蓋原來Entry的value,但key不會有任何改變,
* 因此如果向HashSet中新增一個已經存在的元素時,新新增的集合元素將不會被放入HashMap中,
* 原來的元素也不會有任何改變,這也就滿足了Set中元素不重複的特性。
* @param e 將新增到此set中的元素。
* @return 如果此set尚未包含指定元素,則返回true。
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
/**
* 如果指定元素存在於此set中,則將其移除。
* 更確切地講,如果此set包含一個滿足(o==null ? e==null : o.equals(e))的元素e,
* 則將其移除。如果此set已包含該元素,則返回true
* (或者:如果此set因呼叫而發生更改,則返回true)。(一旦呼叫返回,則此set不再包含該元素)。
*
* 底層實際呼叫HashMap的remove方法刪除指定Entry。
* @param o 如果存在於此set中則需要將其移除的物件。
* @return 如果set包含指定元素,則返回true。
*/
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
/**
* 從此set中移除所有元素。此呼叫返回後,該set將為空。
*
* 底層實際呼叫HashMap的clear方法清空Entry中所有元素。
*/
public void clear() {
map.clear();
}
/**
* 返回此HashSet例項的淺表副本:並沒有複製這些元素本身。
*
* 底層實際呼叫HashMap的clone()方法,獲取HashMap的淺表副本,並設定到HashSet中。
*/
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
}
}5. ArrayList,Vector, LinkedList的儲存效能和特性
ArrayList 和Vector都是使用陣列方式儲存資料,此陣列元素數大於實際儲存的資料以便增加和插入元素,它們都允許直接按序號索引元素,但是插入元素要涉及陣列元素移動等記憶體操作,所以索引資料快而插入資料慢,Vector由於使用了synchronized方法(執行緒安全),通常效能上較ArrayList差,而LinkedList使用雙向連結串列實現儲存,按序號索引資料需要進行前向或後向遍歷,但是插入資料時只需要記錄本項的前後項即可,所以插入速度較快。
6.快速失敗(fail-fast)和安全失敗(fail-safe)
Fail-Fast機制:
我們知道java.util.HashMap不是執行緒安全的,因此如果在使用迭代器的過程中有其他執行緒修改了map,那麼將拋ConcurrentModificationException,這就是所謂fail-fast策略。
這一策略在原始碼中的實現是通過modCount域,modCount顧名思義就是修改次數,對HashMap內容的修改都將增加這個值,那麼在迭代器初始化過程中會將這個值賦給迭代器的expectedModCount。
Java程式碼- HashIterator() {
- expectedModCount = modCount;
- if (size > 0) { // advance to first entry
- Entry[] t = table;
- while (index < t.length && (next = t[index++]) == null)
- ;
- }
- }
在迭代過程中,判斷modCount跟expectedModCount是否相等,如果不相等就表示已經有其他執行緒修改了Map:
注意到modCount宣告為volatile,保證執行緒之間修改的可見性。
Java程式碼- final Entry<K,V> nextEntry() {
- if (modCount != expectedModCount)
- throw new ConcurrentModificationException();
在HashMap的API中指出:
由所有HashMap類的“collection 檢視方法”所返回的迭代器都是快速失敗的:在迭代器建立之後,如果從結構上對對映進行修改,除非通過迭代器本身的 remove 方法,其他任何時間任何方式的修改,迭代器都將丟擲ConcurrentModificationException。因此,面對併發的修改,迭代器很快就會完全失敗,而不冒在將來不確定的時間發生任意不確定行為的風險。
注意,迭代器的快速失敗行為不能得到保證,一般來說,存在非同步的併發修改時,不可能作出任何堅決的保證。快速失敗迭代器盡最大努力丟擲 ConcurrentModificationException。因此,編寫依賴於此異常的程式的做法是錯誤的,正確做法是:迭代器的快速失敗行為應該僅用於檢測程式錯誤。
Fail-Safe機制:Iterator的安全失敗是基於對底層集合做拷貝,因此,它不受源集合上修改的影響。java.util包下面的所有的集合類都是快速失敗(一般的集合類)的,而java.util.concurrent包下面的所有的類(比如CopyOnWriteArrayList,ConcurrentHashMap
)都是安全失敗的。快速失敗的迭代器會丟擲ConcurrentModificationException異常,而安全失敗的迭代器永遠不會丟擲這樣的異常。
7.傳遞一個集合作為引數給函式時,我們如何能確保函式將無法對其進行修改
我們可以建立一個只讀集合,使用Collections.unmodifiableCollection作為引數傳遞給使用它的方法,這將確保任何改變集合的操作將丟擲UnsupportedOperationException。
8.Collections類的方法們
上面說到了很多了collections的方法,我們來深究一下這個類
Collections則是集合類的一個工具類/幫助類,其中提供了一系列靜態方法,用於對集合中元素進行排序、搜尋以及執行緒安全等各種操作。
1) 排序(Sort)
使用sort方法可以根據元素的自然順序 對指定列表按升序進行排序。列表中的所有元素都必須實現 Comparable介面。此列表內的所有元素都必須是使用指定比較器可相互比較的
可以直接Collections.sort(...)
或者可以指定一個比較器,讓這個列表遵照在比較器當中所設定的排序方式進行排序,這就提供了更大的靈活性
public static void sort(List l, Comparatorc)
這個Comparator同樣是一個在java.util包中的介面。這個介面中有兩個方法:int compare(T o1, T o2 )和boolean equals(Object obj)
2)很多常用的,沒必要多講的方法
shuffle(Collection) :對集合進行隨機排序
binarySearch(Collection,Object)方法的使用(含義:查詢指定集合中的元素,返回所查詢元素的索引)
max(Collection),max(Collection,Comparator)方法的使用(前者採用Collection內含自然比較法,後者採用Comparator進行比較)
min(Collection),min(Collection,Comparator)方法的使用(前者採用Collection內含自然比較法,後者採用Comparator進行比較)。
indexOfSubList(List list,List subList)方法的使用(含義:查詢subList在list中首次出現位置的索引)。
lastIndexOfSubList(List source,List target)方法的使用與上例方法的使用相同,在此就不做介紹了。
replaceAll(List list,Object old,Object new)方法的使用(含義:替換批定元素為某元素,若要替換的值存在剛返回true,反之返回false)。
以及等等等等。
3)我自己看看有哪些方法。 (這一段可以直接參考JAVA API說明 http://www.apihome.cn/api/java/Collections.html )
除了2)中講到的一些零碎的,可以看到還分成了checked , empty , singleton, synchronized unmodifiable這幾類。
checked:2個用途:
返回指定 collection 的一個動態型別安全檢視。試圖插入一個錯誤型別的元素將導致立即丟擲 ClassCastException。假設在生成動態型別安全檢視之前,collection 不包含任何型別不正確的元素,並且所有對該 collection 的後續訪問都通過該檢視進行,則可以保證 該 collection 不包含型別不正確的元素。
一般的程式語言機制中都提供了編譯時(靜態)型別檢查,但是一些未經檢查的強制轉換可能會使此機制無效。通常這不是一個問題,因為編譯器會在所有這類未經檢查的操作上發出警告。但有的時候,只進行單獨的靜態型別檢查並不夠。例如,假設將 collection 傳遞給一個第三方庫,則庫程式碼不能通過插入一個錯誤型別的元素來毀壞 collection。
動態型別安全檢視的另一個用途是除錯。假設某個程式執行失敗並丟擲 ClassCastException,這指示一個型別不正確的元素被放入已引數化 collection 中。不幸的是,該異常可以發生在插入錯誤元素之後的任何時間,因此,這通常只能提供很少或無法提供任何關於問題真正來源的資訊。如果問題是可再現的,那麼可以暫時修改程式,使用一個動態型別安全檢視來包裝該 collection,通過這種方式可快速確定問題的來源。
unmodifiable:
返回指定 集合的不可修改檢視。此方法允許模組為使用者提供對內部 集合的“只讀”訪問。在返回的 集合 上執行的查詢操作將“讀完”指定的集合。試圖修改返回的集合(不管是直接修改還是通過其迭代器進行修改)將導致丟擲 UnsupportedOperationException。
synchronized:
public static <T> Collection<T> synchronizedCollection(Collection<T> c)
-
返回指定 collection 支援的同步(執行緒安全的)collection。為了保證按順序訪問,必須通過返回的 collection 完成所有對底層實現 collection 的訪問。
在返回的 collection 上進行迭代時,使用者必須手工在返回的 collection 上進行同步:
Collection c = Collections.synchronizedCollection(myCollection); ... synchronized(c) { Iterator i = c.iterator(); // Must be in the synchronized block while (i.hasNext()) foo(i.next()); }
empty: (以set 為例,我沒看懂到底是幹嘛的。。)
public static final <T> Set<T> emptySet()
-
返回空的 set(不可變的)。此 set 是可序列化的。與 like-named(找不到關於這個東西的資料。。) 欄位不同,此方法是引數化的。
以下示例演示了獲得空 set 的型別安全 (type-safe) 方式:
Set<String> s = Collections.emptySet();
9.Tree, Hash ,Linked
再看看這個圖。
發現set和map的實現分成了 Tree,Hash,和Linked。
以map為例,來看看這三者的區別.
TreeMap用紅黑樹實現,能夠把它儲存的記錄根據鍵排序,預設是按升序排序,也可以指定排序的比較器。當用Iteraor遍歷TreeMap時,得到的記錄是排過序的。TreeMap的鍵和值都不能為空。
HashMap上文有說。
LinkedHashmap:它繼承與HashMap、底層使用雜湊表與雙向連結串列來儲存所有元素。其基本操作與父類HashMap相似,它通過重寫父類相關的方法,來實現自己的連結列表特性。put方法沒有重寫,重寫了addEntry()。(因為加入的時候要維護好一個雙向連結串列的結構)LinkedHashMap重寫了父類HashMap的get方法,實際在呼叫父類getEntry()方法取得查詢的元素後,再判斷當排序模式accessOrder為true時,記錄訪問順序,將最新訪問的元素新增到雙向連結串列的表頭,並從原來的位置刪除。由於的連結串列的增加、刪除操作是常量級的,故並不會帶來效能的損失(accessOrder是LinkedHashmap中的一個屬性,用來判斷是否要根據讀取順序來重寫調整結構。如果為false,就按照插入的順序排序,否則按照最新訪問的放在連結串列前面的順序,以提高效能)。
我個人的理解是:LinedHashMap的作用就是在讓經常訪問的元素更快的被訪問到。用雙向連結串列可以方便地執行連結串列中元素的插入刪除操作。