
關於MapReduce join操作
阿新 • • 發佈:2019-02-11
使用者表:ID+name+sex
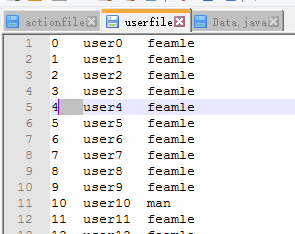
使用者行為表:ID+City+action+notes
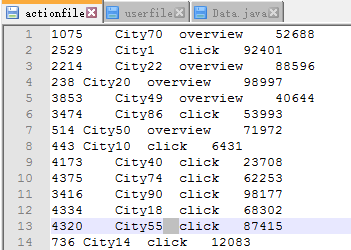
Join完成後的形式:ID+name+sex+city+action+notes
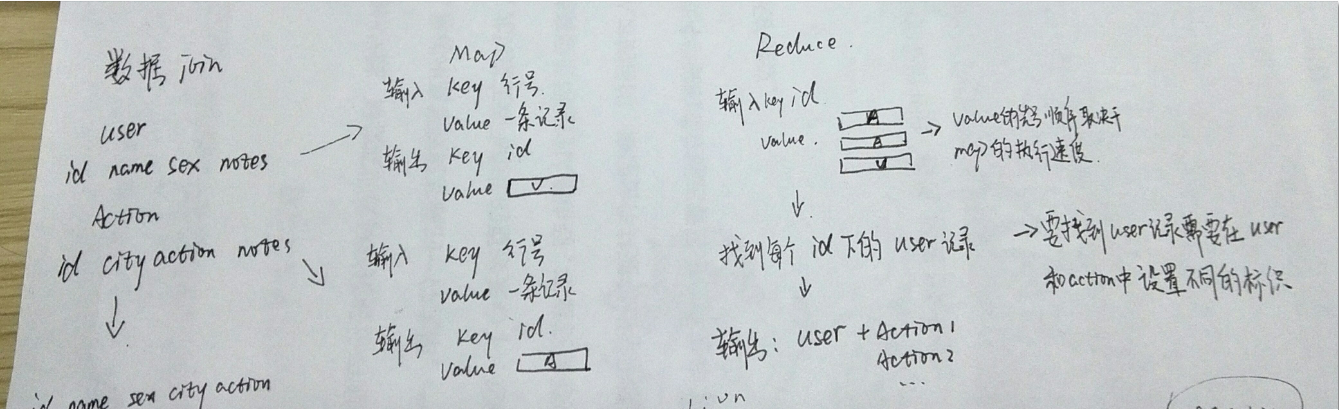
package com.qst.DateJoin;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable