
雲端計算&大資料&人工智慧相關概念
雲端計算相關概念
首先做雲端計算平臺的公司會買很多的物理機放在自己的資料中心中,再通過虛擬化的技術(如閉源的VMware,開源的Xen、KVM),將物理機分割成不同大小的資源(計算資源(CPU)、網路資源(頻寬)、儲存資源(硬碟))以滿足不同使用者的需求,如個人使用者可能只需要一個CPU、1G記憶體、10G的硬碟、一兆的頻寬
但是建立一臺虛擬的電腦,需要人工指定這臺虛擬電腦放在哪臺物理機上的。這一過程可能還需要比較複雜的人工配置,所以僅僅憑虛擬化軟體所能管理的物理機的叢集規模都不是特別大,一般在十幾臺、幾十臺、最多百臺這麼一個規模。而幾十上百萬臺機器要靠人去選一個位置放這臺虛擬化的電腦並做相應的配置,幾乎是不可能的事情,還是需要機器去做這個事情
所以人們發明了一種叫做排程(Scheduler)的演算法,通俗一點說,就是有一個排程中心,幾千臺機器都在一個池子裡面,無論使用者需要多少CPU、記憶體、硬碟的虛擬電腦,排程中心都會自動在大池子裡面找一個能夠滿足使用者需求的地方,把虛擬電腦啟動起來做好配置,使用者就直接能用了。這個階段稱為池化或者雲化
私有云:把虛擬化和雲化的這套軟體部署在別人的資料中心裡面。使用私有云的使用者往往很有錢,自己買地建機房、自己買伺服器,然後讓雲廠商部署在自己這裡
公有云:把虛擬化和雲化軟體部署在雲廠商自己資料中心裡面的,使用者不需要很大的投入,只要註冊一個賬號,就能在一個網頁上點一下建立一臺虛擬電腦。例如AWS即亞馬遜的公有云;例如國內的阿里雲、騰訊雲、網易雲等
OpenStack:公有云第二名Rackspace和美國航空航天局合作創辦了開源軟體OpenStack,一個計算、網路、儲存的雲化管理平臺。所有想做雲的IT廠商都加入到這個社群中來,對這個雲平臺進行貢獻,包裝成自己的產品,連同自己的硬體裝置一起賣。有的做了私有云,有的做了公有云,OpenStack已經成為開源雲平臺的事實標準
隨著OpenStack的技術越來越成熟,可以管理的規模也越來越大,並且可以有多個OpenStack叢集部署多套。在這個規模下,對於普通使用者的感知來講,基本能夠做到想什麼時候要就什麼什麼要,想要多少就要多少。還是拿雲盤舉例子,每個使用者雲盤都分配了5T甚至更大的空間,如果有1億人,那加起來空間多大啊。
IaaS(Infranstracture As A Service):到了這個階段,雲端計算基本上實現了時間靈活性和空間靈活性;實現了計算、網路、儲存資源的彈性。計算、網路、儲存常稱為基礎設施Infranstracture, 因而這個階段的彈性稱為資源層面的彈性。管理資源的雲平臺,稱為基礎設施服務,也就是我們常聽到的IaaS
PaaS(Platform As A Service):
- 自己的應用自動安裝:安裝的過程平臺幫不了忙,但能夠幫你做自動化,如用容器技術(Docker)
- 通用的應用不用安裝:通用的應用可以變成標準的PaaS層的應用放在雲平臺的介面上。當用戶需要時(如資料庫),一點就出來了,使用者就可以直接用了
大資料相關概念
資料的應用分為四個步驟:資料、資訊、知識、智慧
最終的階段是很多商家都想要的。你看我收集了這麼多的資料,能不能基於這些資料來幫我做下一步的決策,改善我的產品。例如讓使用者看視訊的時候旁邊彈出廣告,正好是他想買的東西;再如讓使用者聽音樂時,另外推薦一些他非常想聽的其他音樂
資料的處理分幾個步驟,完成了才最後會有智慧
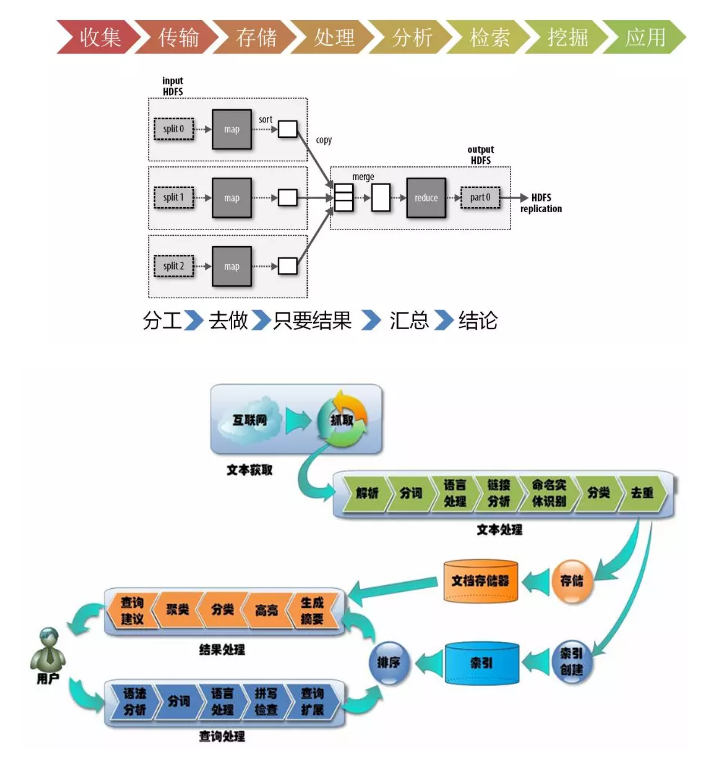
第一個步驟叫資料的收集。首先得有資料,資料的收集有兩個方式:
- 抓取或者爬取
- 推送,如小米手環,可以將你每天跑步的資料,心跳的資料,睡眠的資料都上傳到資料中心裡面
第二個步驟是資料的傳輸
第三個步驟是資料的儲存
第四個步驟是資料的處理和分析。通過清洗和過濾垃圾資料,得到一些高質量的資料。對於高質量的資料,就可以進行分析,從而對資料進行分類,或者發現數據之間的相互關係,得到知識
第五個步驟是對於資料的檢索和挖掘
人工智慧相關概念
機器是和人是完全不一樣的物種,想要告訴計算機人類的推理能力是很難的,所以乾脆讓機器自己學習
基於統計學習:從大量的數字中發現一定的規律
統計學習比較容易理解簡單的相關性:例如一個詞和另一個詞總是一起出現,兩個詞應該有關係;而無法表達複雜的相關性。並且統計方法的公式往往非常複雜,為了簡化計算,常常做出各種獨立性的假設,來降低公式的計算難度,然而現實生活中,具有獨立性的事件是相對較少的
模擬大腦的工作方式:神經網路學習
人類的腦子裡面不是儲存著大量的規則,也不是記錄著大量的統計資料,而是通過神經元的觸發實現的,每個神經元有從其它神經元的輸入,當接收到輸入時,會產生一個輸出來刺激其它神經元。於是大量的神經元相互反應,最終形成各種輸出的結果
例如當人們看到美女瞳孔會放大,絕不是大腦根據身材比例進行規則判斷,也不是將人生中看過的所有的美女都統計一遍,而是神經元從視網膜觸發到大腦再回到瞳孔。在這個過程中,其實很難總結出每個神經元對最終的結果起到了哪些作用,反正就是起作用了
於是人們開始用一個數學單元模擬神經元。這個神經元有輸入,有輸出,輸入和輸出之間通過一個公式來表示,輸入根據重要程度不同(權重),影響著輸出。於是將n個神經元通過像一張神經網路一樣連線在一起。n這個數字可以很大很大,所有的神經元可以分成很多列,每一列很多個排列起來。每個神經元對於輸入的權重可以都不相同,從而每個神經元的公式也不相同。當人們從這張網路中輸入一個東西的時候,希望輸出一個對人類來講正確的結果
學習的過程就是,輸入大量的圖片,如果結果不是想要的結果,則進行調整。如何調整呢?就是每個神經元的每個權重都向目標進行微調,由於神經元和權重實在是太多了,所以整張網路產生的結果很難表現出非此即彼的結果,而是向著結果微微地進步,最終能夠達到目標結果。當然,這些調整的策略還是非常有技巧的,需要演算法的高手來仔細的調整
神經網路的普遍性定理是這樣說的,假設某個人給你某種複雜奇特的函式,f(x):不管這個函式是什麼樣的,總會確保有個神經網路能夠對任何可能的輸入x,其值f(x)(或者某個能夠準確的近似)是神經網路的輸出。如果這個函式代表著規律,也意味著這個規律無論多麼奇妙,多麼不能理解,都是能通過大量的神經元,通過大量權重的調整,表示出來的
人工智慧可以做的事情非常多,例如可以鑑別垃圾郵件、鑑別黃色暴力文字和圖片等。這也是經歷了三個階段的:
第一個階段依賴於關鍵詞黑白名單和過濾技術,包含哪些詞就是黃色或者暴力的文字。隨著這個網路語言越來越多,詞也不斷地變化,不斷地更新這個詞庫就有點顧不過來
第二個階段時,基於一些新的演算法,比如說貝葉斯過濾等,你不用管貝葉斯演算法是什麼,但是這個名字你應該聽過,這個一個基於概率的演算法
第三個階段就是基於大資料和人工智慧,進行更加精準的使用者畫像和文字理解和影象理解
SaaS (Software AS A Service):軟體即服務,人工智慧演算法多是依賴於大量的資料的,如果沒有資料,就算有人工智慧演算法也白搭,而雲端計算廠商往往積累了大量資料的,於是就可以暴露一個服務介面,比如您想鑑別一個文字是不是涉及黃色和暴力,直接用這個線上服務就可以了
參考:
為什麼說21世紀是一場ABC的革命?
作者:劉超