
Hadoop作業初始化過程
排程器呼叫JobTracker.initJob();函式對新作業進行初始化,作業初始化的主要工作是構造Map Task和Reduce Task並對它們進行初始化。
hadoop將每一個作業分解成4種類型的任務,分別是Setup Task、Map Task、Reduce Task和Cleanup Task .它們的執行時資訊由TaskInprogress類維護。因此,建立這些任務實際上是建立TaskInProgress物件。
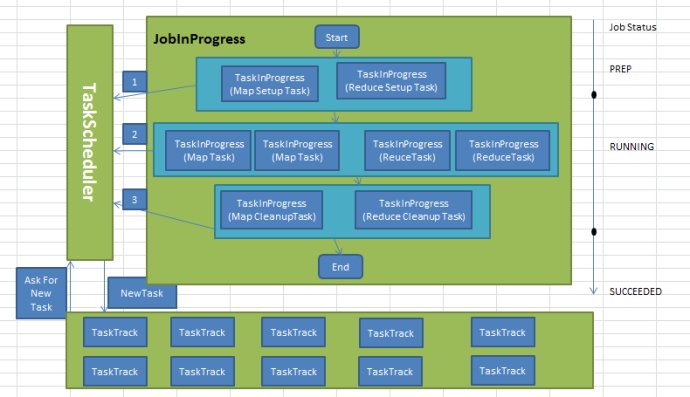
4中任務的作用以及建立過程如下:
1、Setup Task :作業初始化標識性任務,它進行一些非常簡單的作業初始化工作,比如將作業狀態設定為”setup”,呼叫OutputCommitter.setupjob()函式等。該任務執行完後,作業由PREP狀態變為RUNNING狀態。並開始執行Map Task。該型別任務又被分為Map Setup Task和Reduce Setup Task兩種,且每個作業各有一個,他們執行時分別佔用一個Map slot和reduce slot。由於這兩種任務功能相同,因此有且只有一個可以獲取執行的機會(即只要有一個開始執行,另一個馬上被kill掉,而具體哪一個能夠執行,取決於當前存在的空閒slot種類以排程策略)。
建立該類任務的相關程式碼如下:JobInProgess
// create two setup tips, one map and one reduce.
setup = new TaskInProgress[2];
// setup map tip. This map doesn't use any split. Just assign an empty split.
setup[0] = new TaskInProgress(jobId, jobFile, emptySplit,
jobtracker, conf, this, numMapTasks + 1 2、Map Task:map階段處理資料的任務,其數目及對應的處理資料分片由應用程式中的InputFormat元件確定。
相關程式碼如下:
TaskSplitMetaInfo[] splits = createSplits(jobId);
if (numMapTasks != splits.length) {
throw new IOException("Number of maps in JobConf doesn't match number of " +
"recieved splits for job " + jobId + "! " +
"numMapTasks=" + numMapTasks + ", #splits=" + splits.length);
}
numMapTasks = splits.length;
// Sanity check the locations so we don't create/initialize unnecessary tasks
for (TaskSplitMetaInfo split : splits) {
NetUtils.verifyHostnames(split.getLocations());
}
jobtracker.getInstrumentation().addWaitingMaps(getJobID(), numMapTasks);
jobtracker.getInstrumentation().addWaitingReduces(getJobID(), numReduceTasks);
this.queueMetrics.addWaitingMaps(getJobID(), numMapTasks);
this.queueMetrics.addWaitingReduces(getJobID(), numReduceTasks);
maps = new TaskInProgress[numMapTasks];
for(int i=0; i < numMapTasks; ++i) {
inputLength += splits[i].getInputDataLength();
maps[i] = new TaskInProgress(jobId, jobFile,
splits[i],
jobtracker, conf, this, i, numSlotsPerMap);
}3、Reduce Task Reduce階段處理資料的任務,其數目有使用者通過引數Mapred.reduce.tasks(預設數目為1)指定,考慮到Reduce Task能否執行依賴於Map Task的輸出結果,因此,hadoop剛開始只會排程Map Task,直到Map Task完成數目達到一定比例(由引數Mapred.reduce.slowstart.completed.maps指定,預設是0.05,即5%)
相關程式碼如 // Create reduce tasks
this.reduces = new TaskInProgress[numReduceTasks];
for (int i = 0; i < numReduceTasks; i++) {
reduces[i] = new TaskInProgress(jobId, jobFile,
numMapTasks, i,
jobtracker, conf, this, numSlotsPerReduce);
nonRunningReduces.add(reduces[i]);
}
4、Cleanup Task:作業結束標誌性任務,主要完成一些作業清理工作,比如刪除作業執行過程中用到的一些臨時目錄(比如 Temporary目錄)。一旦該任務執行成功後,作業由RUNNING狀態變為SUCCEEDED狀態。這個和Setup Task 類似 會建立2個Task 一個Map Cleanup Task和Reduce Cleanup Task
程式碼如下:
// create cleanup two cleanup tips, one map and one reduce.
cleanup = new TaskInProgress[2];
// cleanup map tip. This map doesn't use any splits. Just assign an empty
// split.
TaskSplitMetaInfo emptySplit = JobSplit.EMPTY_TASK_SPLIT;
cleanup[0] = new TaskInProgress(jobId, jobFile, emptySplit,
jobtracker, conf, this, numMapTasks, 1);
cleanup[0].setJobCleanupTask();
// cleanup reduce tip.
cleanup[1] = new TaskInProgress(jobId, jobFile, numMapTasks,
numReduceTasks, jobtracker, conf, this, 1);
cleanup[1].setJobCleanupTask();有人發現引入Setup/Cleanup Task會拖慢作業執行進度且降低作業的可靠性,這主要是因為hadoop除了需要保證每個Map/Reduce Task執行成功外,還要保證Setup/Cleanup Task成功。對於Map/Reduce Task而言,可通過推測執行機制避免出現”拖後腿”的任務。然而,由於Setup/Cleanup Task不會處理任何資料,兩種任務的進度只有0%和100%兩個值,從而使得推測式任務機制對之不適用,為了解決這個問題,從0.21.0版本開始,hadoop將是否開啟Setup/Cleanup Task 變成了可配置的選項,使用者可通過引數 mapred.committer.job.set.cleanup.needed配置是否為作業建立Setup/Cleanup Task