
日誌資訊收集框架--FLUME基本使用
FLUME的產生背景
- 對於關係型資料庫和HDFS,Hive,等的資料,我們可以使用sqoop將資料進行匯入匯出操作,但對於一些日誌資訊(源端)的定時收集,這種方式顯然不能給予滿足,這時有人會想到使用shell指令碼的定時作業排程將日誌收集出來,但是這種方式在處理大的資料和可靠性方面也顯現出很多缺點,再比如日誌資訊的儲存與壓縮格式,任務的監控,這些顯然也不能滿足。
- 基於以上,FLUME這個分散式,高可靠,高可用,已經非常成熟的日誌資訊收集框架隨之誕生,他的簡單,輕便,健壯等特性使得他在資料收集方面使用的較為廣泛。
哪些方面可以使用到FLUME
- FLUME自身提供了多種sources(源端型別),多種sinks(傳輸端型別)使得他可以處理很多型別端的資料,並傳輸到多種指定的輸出端,基於輸出端的不同,可以大致分為:1)傳輸到HDFS(離線批處理);2)傳輸到kafka等訊息中介軟體,再由像sparkstreaming流式化處理系統進行處理
FLUME基本架構
Event概念
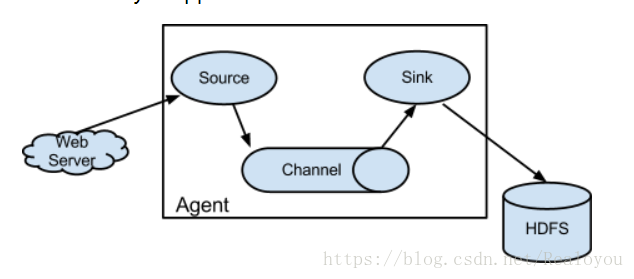
- flume的核心是把資料從資料來源(source)收集過來,在將收集到的資料送到指定的目的地(sink)。為了保證輸送的過程一定成功,在送到目的地(sink)之前,會先快取資料(channel),待資料真正到達目的地(sink)後,flume在刪除自己快取的資料。
- 在整個資料的傳輸的過程中,流動的是event,即事務保證是在event級別進行的。那麼什麼是event呢?—–event將傳輸的資料進行封裝,是flume傳輸資料的基本單位,如果是文字檔案,通常是一行記錄,event也是事務的基本單位。event從source,流向channel,再到sink,本身為一個位元組陣列,並可攜帶headers(頭資訊)資訊。event代表著一個數據的最小完整單元,從外部資料來源來,向外部的目的地去。
Agent
- 一個Agent就是一個Flume程序,agent本身是一個java程序,執行在日誌收集節點—所謂日誌收集節點就是伺服器節點。
- 一個Agent有三大元件:Source,Channel,Sink.但是一個Agent可以由多個Source,多個Channel,多個Sink構成,一個Source可以對應多個Channel,但是一個Channel只能對應一個Sink。最簡單的Agent是由一個Source,一個Channel,一個Sink構成。
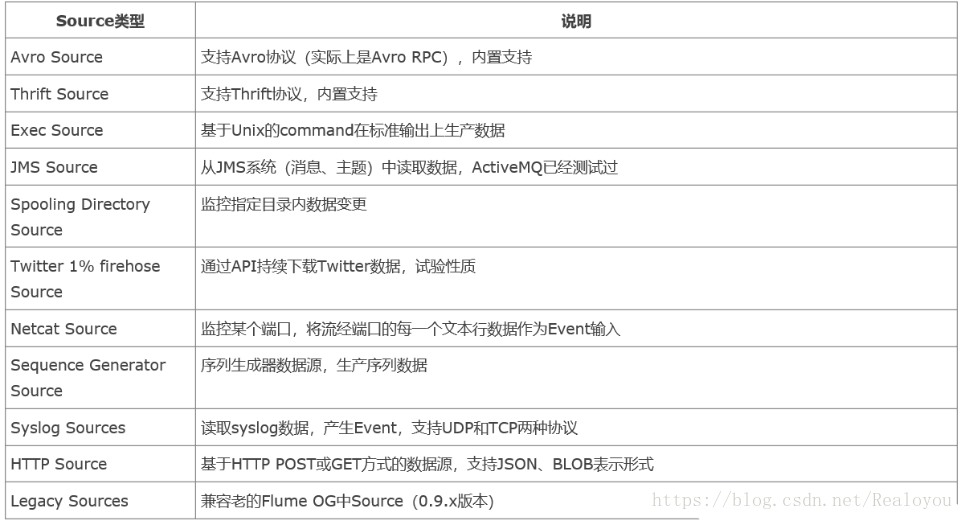
- Source :負責從源端採集資料,輸出到channel中,常用的Source有exec/Spooling Directory/Taildir Source/NetCat
- Channel :負責快取Source端來的資料,常用的Channel有Memory/File
- Sink : 處理Channel而來的資料寫到目標端,常用的Sink有HDFS/Logger/Avro/Kafka
元件種類
Sources
Channels
Sinks


使用
- Flume的使用就是寫一個Agent配置檔案,根據場景和需求指定不同得元件型別,通過Channel將Source端和Sink端繫結串聯起來,然後用flume -ng 啟動flume程序
eg:
1. vi hello.conf 2. # Name the components on this agent 3. a1.sources = r1 4. a1.sinks = k1 5. a1.channels = c1 6. # Describe/configure the source 7. a1.sources.r1.type = netcat 8. a1.sources.r1.bind = 0.0.0.0 9. a1.sources.r1.port = 44444 10. # Describe the sink 11. a1.sinks.k1.type = logger 12. # Use a channel which buffers events in memory 13. a1.channels.c1.type = memory 14. # Bind the source and sink to the channel 15. a1.sources.r1.channels = c1 16. a1.sinks.k1.channel = c1啟動:
1. ./flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/hello.conf -Dflume.root.logger=INFO,console
FLUME部署
- 下載:下載CDH版本 apache-flume-1.6.0-cdh5.7.0-bin
配置環境變數:
1. export FLUME_HOME=/opt/software/apache-flume-1.6.0-cdh5.7.0-bin 2. export PATH=$FLUME_HOME/bin:$PATH指定JAVA_HOME:
1. cp flume-env.sh.template flume-env.sh 2. export JAVA_HOME=/usr/java/jdk1.8.0_45
測試案例
使用Exec Source Sink 到HDFS
- Exec Source:監聽一個指定的命令,獲取一條命令的結果作為它的資料來源
常用的是tail -F file指令,即只要應用程式向日志(檔案)裡面寫資料,source元件就可以獲取到日誌(檔案)中最新的內容 。 配置檔案:
1. # Name the components on this agent 2. a1.sources = r1 3. a1.sinks = k1 4. a1.channels = c1 5. # Describe/configure the source 6. a1.sources.r1.type = exec 7. a1.sources.r1.command = tail -F /home/hadoop/data/data.log 8. # Describe the sink 9. a1.sinks.k1.type = hdfs 10. a1.sinks.k1.hdfs.path = hdfs://hadoop:9000/flume 11. a1.sinks.k1.hdfs.writeFormat = Text 12. a1.sinks.k1.hdfs.fileType = DataStream 13. a1.sinks.k1.hdfs.rollInterval = 10 14. a1.sinks.k1.hdfs.rollSize = 0 15. a1.sinks.k1.hdfs.rollCount = 0 16. a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H-%M-%S 17. a1.sinks.k1.hdfs.useLocalTimeStamp = true 18. # Use a channel which buffers events in memory 19. a1.channels.c1.type=memory 20. a1.channels.c1.capacity=10000 21. a1.channels.c1.transactionCapacity=1000 22. # Bind the source and sink to the channel 23. a1.sources.r1.channels = c1 24. a1.sinks.k1.channel = c1啟動:
1. ./flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/test3.conf -Dflume.root.logger=INFO,console 2. echo hadoop >data.log檢視結果:
1. [[email protected] ~]$ hdfs dfs -text /flume/2018-04-21-20-13-38.1524370418338 hadoop
使用Avro進行資料傳輸
- 以上的flume的使用方式都是啟動的agent和sink端在一個節點之上,對於多節點的方式資料傳輸,flume給我們提供了Avro的Sink端和Avro的Source端,這樣在多個Agent對接就提供瞭解決方案,在生產中的實際部署也多是使用Avro的方式。
使用Avro-client對接Avro source
A機器向B機器傳輸日誌
A機器:avro-client
B機器:avro-source ,channel(memory) ,sink(logger)配置資訊
1. B機器的agent檔案: 2. a1.sources=r1 3. a1.sinks=k1 4. a1.channels=c1 5. a1.sources.r1.type=avro 6. a1.sources.r1.bind=0.0.0.0 7. a1.sources.r1.port=44444 8. a1.channels.c1.type=memory 9. a1.sinks.k1.type=logger 10. a1.sinks.k1.channel=c1 11. a1.sources.r1.channels=c1執行命令:
1. B機器上: 2. ./flume-ng agent \ 3. --name a1 \ 4. --conf $FLUME_HOME/conf \ 5. --conf-file $FLUME_HOME/conf/avro.conf \ 6. -Dflume.root.logger=INFO,console 7. 在A機器上: 8. ./flume-ng avro-client --host 0.0.0.0 --port 44444 --filename /home/hadoop/data/input.txt使用此種方式只能一次性傳輸檔案,傳輸結束,程序也就自動結束了。
使用Avro Source和Avro Sink
定義A機器的agent:
1. a1.sources=r1 2. a1.sinks=k1 3. a1.channels=c1 4. a1.sources.r1.type=exec 5. a1.sources.r1.command=tail -F /home/hadoop/data/data.log 6. a1.channels.c1.type=memory 7. a1.sinks.k1.type=avro 8. a1.sinks.k1.bind=0.0.0.0 //與B機器相對應 9. a1.sinks.k1.port=44444 //與B機器相對應 10. a1.sinks.k1.channel=c1 11. a1.sources.r1.channels=c1定義B機器的agent:
1. b1.sources=r1 2. b1.sinks=k1 3. b1.channels=c1 4. b1.sources.r1.type=avro 5. a1.sources.r1.bind = 0.0.0.0 6. a1.sources.r1.port = 44444 7. b1.channels.c1.type=memory 8. b1.sinks.k1.type=logger 9. b1.sinks.k1.channel=c1 10. b1.sources.r1.channels=c1
*啟動:
1. b機器先執行:
2. ./flume-ng agent \
3. --name b1 \
4. --conf $FLUME_HOME/conf \
5. --conf-file $FLUME_HOME/conf/avro_source.conf \
6. -Dflume.root.logger=INFO,console
7. 然後在A機器上執行:
8. ./flume-ng agent \
9. --name a1 \
10. --conf $FLUME_HOME/conf \
11. --conf-file $FLUME_HOME/conf/avro_sink.conf \
12. -Dflume.root.logger=INFO,console
13. [[email protected] data]$ echo aaa > data.log
14. [[email protected] data]$ echo 112121 > data.log
15. A機器目標目錄下檔案內容會被列印在B機器的控制檯上
相關推薦
日誌資訊收集框架--FLUME基本使用
FLUME的產生背景 對於關係型資料庫和HDFS,Hive,等的資料,我們可以使用sqoop將資料進行匯入匯出操作,但對於一些日誌資訊(源端)的定時收集,這種方式顯然不能給予滿足,這時有人會想到使用shell指令碼的定時作業排程將日誌收集出來,但是這種方式在
日誌收集框架 Flume 組件之Source使用
exp component imm 更新 作用 多少 收集 under onf 上一篇簡單介紹了Flume幾個組件,今天介紹下組件其一的source,整理這些,也是二次學習的過程,也是梳理知識的過程。 Source 中文譯為來源,源作用:采集數據,然後把數據傳輸到chann
分散式日誌收集框架flume實戰
實戰一:從指定網路埠採集資料輸出到控制檯 flume框架架構 Source:指定資料來源,有NetCat TCP(專案用到),kafka,JMS,Avro,Syslog等等 Channel:資料管道,有Kafka,Memory,File等等 Sink:日誌資料存放,有Avro,HBa
分散式日誌收集框架Flume
文章目錄 Flume概述 Flume架構及核心元件 Flume&JDK環境部署 Flume實戰案例一 Flume實戰案例二 Flume實戰案例三(重點掌握) 業務現狀:公司有Hadoop
分散式日誌收集框架Flume環境部署
最近在做一個基於Spark Streaming的實時流處理專案,之間用到了Flume來收集日誌資訊,所以在這裡總結一下Flume的用法及原理. Flume是一個分散式、高可靠、高可用、負載均衡的進行大量
大資料實時日誌收集框架Flume案例之抽取日誌檔案到HDFS
上節介紹了Flume的作用以及如何使用,本文主要通過一個簡單的案例來更好地運用Flume框架。在實際開發中,我們有時需要實時抽取一些資料夾下的檔案來分析,比如今天的日誌檔案需要抽取出來做分析。這時,如何自動實時的抽取每天的日誌檔案呢?我們可以使用Flume來完成
大資料日誌檔案實時收集框架Flume介紹及其使用
大資料中,我們經常會將一些日誌檔案收集分析,比如網站的日誌檔案等等,我們需要一個工具收集資料並且上傳到HDFS,HIVE,HBASE等大資料倉庫中,Apache為我們提供了一個很好的檔案實時收集框架供我們使用。 一、Flume的介紹 官網的介紹如下:
分散式日誌收集框架Flume:從指定網埠採集資料輸出到控制檯
A)配置Source B)配置Channel C)配置Sink D)把以上三個元件串起來 變數: a1:agent名稱r1:source的名稱k1:sink的名稱c1:channel的名稱 #以下為配
分散式日誌收集框架 Flume
1 需求分析 WebServer/ApplicationServer分散在各個機器上,然而我們依舊想在Hadoop平臺上進行統計
日誌采集框架Flume
transacti 單元 table 需求 解壓 數據傳輸 取數據 event 事件 概述 Flume是一個分布式、可靠、和高可用的海量日誌采集、聚合和傳輸的系統。 Flume可以采集文件,socket數據包等各種形式源數據,又可以將采集到的數據輸出到HDFS、hb
安卓崩潰資訊收集框架ACRA
版權宣告:本文為博主高遠原創文章,轉載請註明出處:http://blog.csdn.net/wgyscsf https://blog.csdn.net/wgyscsf/article/details/54314899 簡介 ACRA is a library
Android-Fk:[開源框架] 安卓崩潰資訊收集框架ACRA原理流程
Android-Fk:[開源框架] 安卓崩潰資訊收集框架ACRA原理流程 本文主要梳理ACRA原理及程式碼流程 順序圖的uml檔案 簡化圖的draw.io原始檔 分享至百度網盤 https://pan.baidu.com/s/1zAapEu9mmOZsTMDlCRCRQg 一. 學習
資訊收集框架——recon-ng
背景:在滲透測試前期做攻擊面發現(資訊收集)時候往往需要用到很多工具,最後再將蒐集到的資訊彙總到一塊。 現在有這樣一個現成的框架,裡面集成了許多資訊收集模組、資訊儲存資
大資料-Flume(分散式日誌收集框架)
這裡主要是三個常見的需求:監聽埠收集資料監聽檔案收集資料監聽檔案資料轉向其他機器Flume安裝前置條件 Java Runtime Environment - Java 1.7 or later Memory - Sufficient memory for conf
Flume+Kafka+Zookeeper搭建大數據日誌采集框架
flume+kafka+zookeeper1. JDK的安裝 參考jdk的安裝,此處略。2. 安裝Zookeeper 參考我的Zookeeper安裝教程中的“完全分布式”部分。3. 安裝Kafka 參考我的Kafka安裝教程中的“完全分布式搭建”部分。4. 安裝Flume 參考
日誌收集系統Flume及其應用
註意 內存緩存 外部 ner 流動 場景 啟動 net conf Apache Flume概述 Flume 是 Cloudera 提供的一個高可用的,高可靠的,分布式的海量日誌采集、聚合和傳輸的系統。Flume 支持定制各類數據發送方,用於收集各類型數據;同時,Flu
asp.Net Core免費開源分布式異常日誌收集框架Exceptionless安裝配置以及簡單使用圖文教程
true 類型 全部 界面 目錄 () 程序包 light set 最近在學習張善友老師的NanoFabric 框架的時了解到Exceptionless : https://exceptionless.com/ !因此學習了一下這個開源框架!下面對Exceptionless
Apache flume+Kafka獲取實時日誌資訊
Flume簡介以及安裝 Flume是一個分散式的對海量日誌進行採集,聚合和傳輸的系統。Flume系統分為三個元件,分別是source,sink,channel:source表明資料的來源,可能來自檔案,Avro等,channel作為source和sink的橋樑,作為資料的臨時儲存地,channal是
電商大資料分析平臺(三)nginx配置及flume讀取日誌資訊
一、nginx配置 在本專案中nginx的作用只是接收客戶端傳送的事件,並將相應的session寫入日誌檔案中,所以配置較為簡單,只需要配置寫入的日誌檔案和寫入的格式 1.地址配置 server { listen