
讀《深度探索C++物件模型》之物件成員的效率
阿新 • • 發佈:2019-02-11
測試平臺:華碩N53S(五年前的老機子)
編譯環境:VS2010
接下來我將會有多個測試,在多個不同環境下的所消耗的時間比較:
五個測試分別為:個別的區域性變數、區域性陣列、struct之的Public、class 之中的inline Get函式、 class之中的inline Get & Set函式:
程式碼片段如下:
struct Point { Point(float mx, float my, float mz) { x = mx; y = my; z = mz; } float x, y, z; }; class Point3D { public: Point3D(float xx = 0.0f, float yy = 0.0f, float zz = 0.0f) :_x(xx), _y(yy), _z(zz) { } float &x () {return _x;} float &y () {return _y;} float &z () {return _z;} void x(float nx) {_x = nx;} void y(float ny) {_y = ny;} void z(float nz) {_z = nz;} private: float _x, _y, _z; }; int main() { double dur; clock_t start, end; //local float pA_x = 1.725f, pA_y = 0.875f, pA_z = 0.478f; float pB_x = 0.315f, PB_y = 0.317f, PB_z = 0.838f; start = clock(); for (unsigned i = 0; i < 100000000; ++i) { pB_x = pA_x - PB_z; PB_y = pA_y - pB_x; PB_z = pA_z - PB_y; } end = clock(); dur = double(end - start); printf("Use time 1 : %f\n", (dur/CLOCKS_PER_SEC)); // enum fussy{x, y, z}; float pA[3] = {1.725f, 0.875f, 0.478f}; float pB[3] = {0.315f, 0.317f, 0.838f}; start = clock(); for (unsigned i = 0; i < 100000000; ++i) { pB[x] = pA[x] - pB[z]; pB[y] = pA[y] + pB[x]; pB[z] = pA[z] + pB[y]; } end = clock(); dur = double(end - start); printf("Use time 2 : %f\n", (dur/CLOCKS_PER_SEC)); Point sPa(1.725f, 0.875f, 0.478f); Point sPb(0.315f, 0.317f, 0.838f); start = clock(); for (unsigned i = 0; i < 100000000; ++i) { sPb.x = sPa.x - sPb.z; sPb.y = sPa.y + sPb.x; sPb.z = sPa.z + sPb.y; } end = clock(); dur = double(end - start); printf("Use time 3 : %f\n", (dur/CLOCKS_PER_SEC)); Point3D cpA(1.725f, 0.875f, 0.478f); Point3D cpB(0.315f, 0.317f, 0.838f); start = clock(); for (unsigned i = 0; i < 100000000; ++i) { cpB.x() = cpA.x() - cpB.z(); cpB.y() = cpA.y() + cpB.x(); cpB.z() = cpA.z() + cpB.y(); } end = clock(); dur = double(end - start); printf("Use time 4 : %f\n", (dur/CLOCKS_PER_SEC)); Point3D cpA1(1.725f, 0.875f, 0.478f); Point3D cpB1(0.315f, 0.317f, 0.838f); start = clock(); for (unsigned i = 0; i < 100000000; ++i) { cpB1.x(cpA1.x() - cpB1.z()); cpB1.y(cpA1.y() + cpB1.x()); cpB1.z(cpA.z() + cpB.y()); } end = clock(); dur = double(end - start); printf("Use time 5 : %f\n", (dur/CLOCKS_PER_SEC)); system("pause"); return 0; }
在不開啟如何優化的時間下,所用的時間如下:
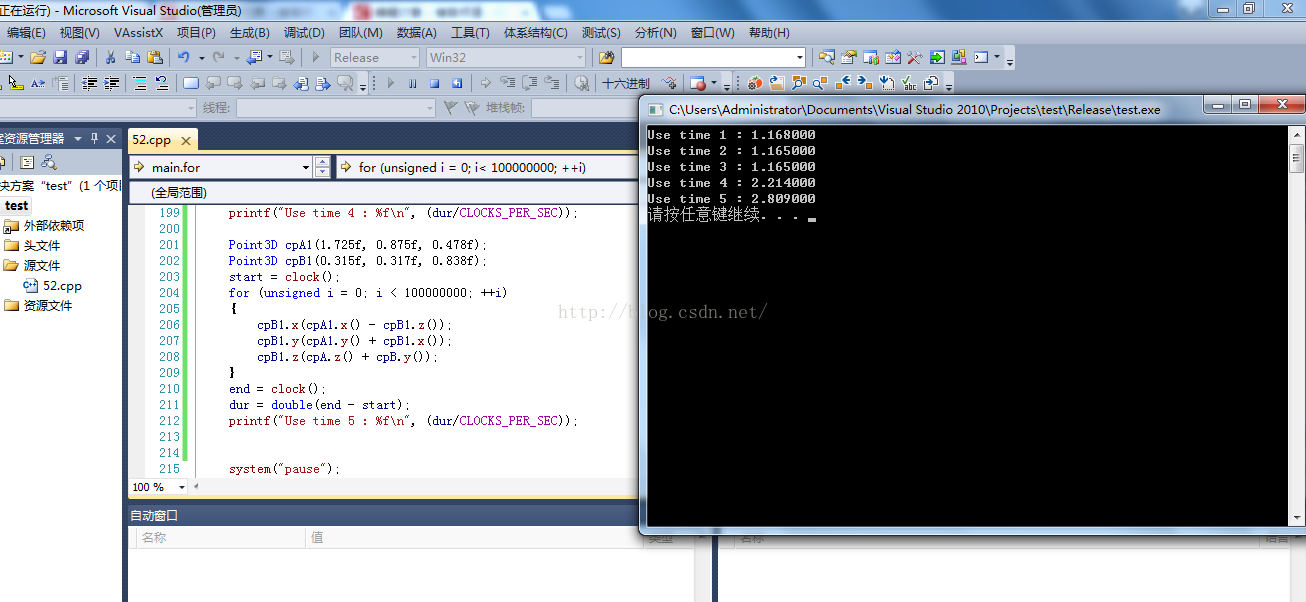
可以看出,在不優化的情況下,前面三種幾乎時間是一樣的,因為可以說是C的用法,後面兩種是C++的用法,所消耗的時間幾乎是前兩種的2倍,應該是由於封裝所帶來的時間吧。下面在打卡vs2010的全部優化開關的情況下所用的時間:
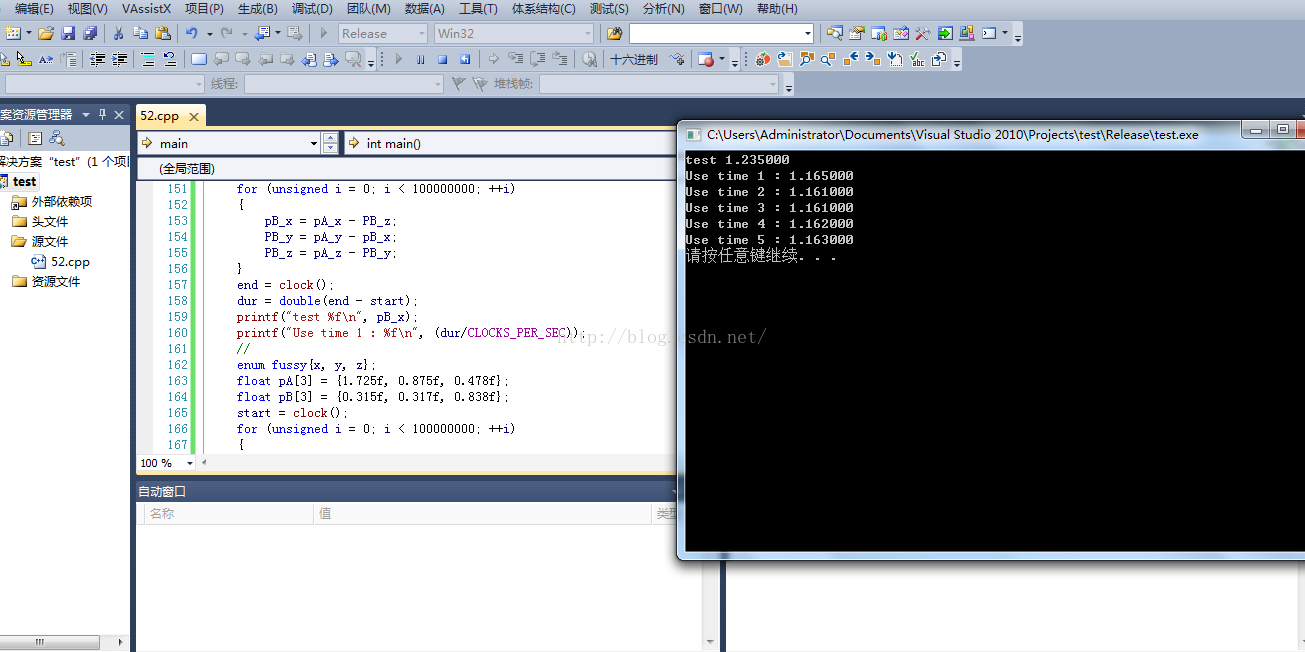
可以看到,在優化全部開啟的情況下,五種情況下的時間,基本上都為1.165ms,類所帶來的封裝也就沒有帶來什麼執行期的效率成本了。
那如果加上繼承呢,那我們再次來驗證一下:
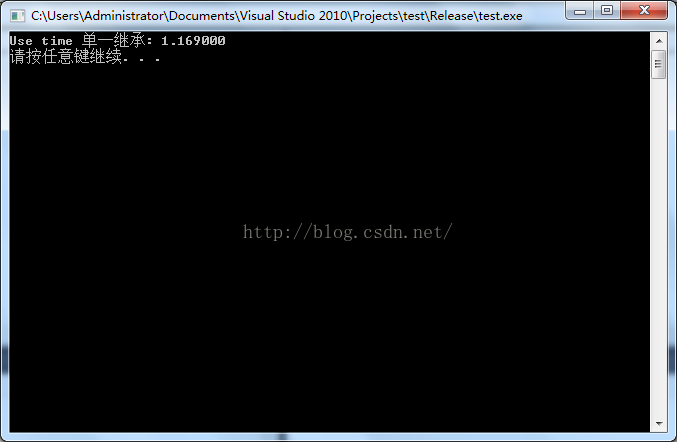
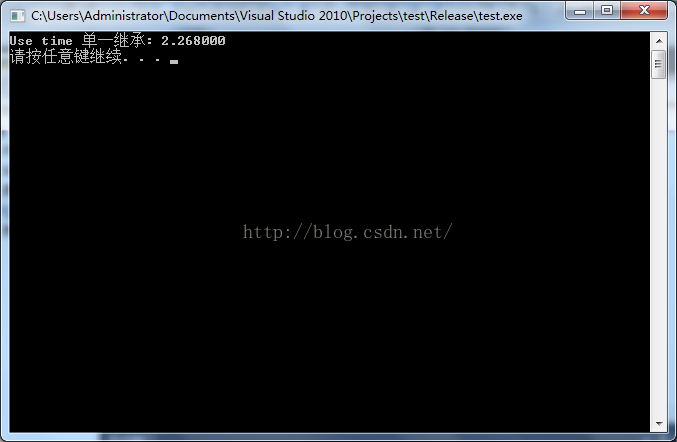
單一的繼承:
優化的情況下:
未優化的情況下:
虛擬繼承(單一)(指的是Point2d虛擬繼承於Point1d):
優化的情況下:
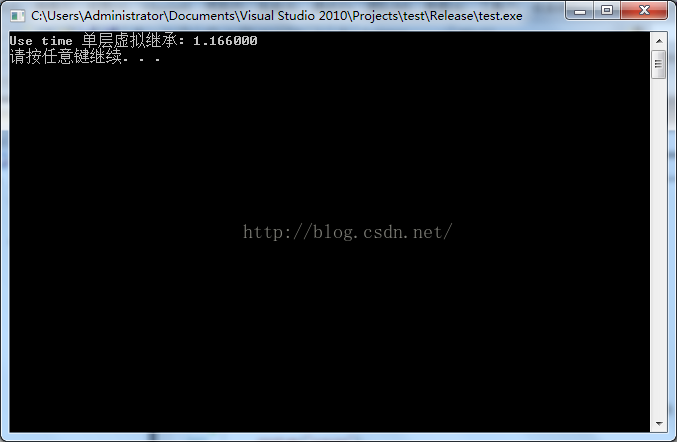
未優化的情況下:
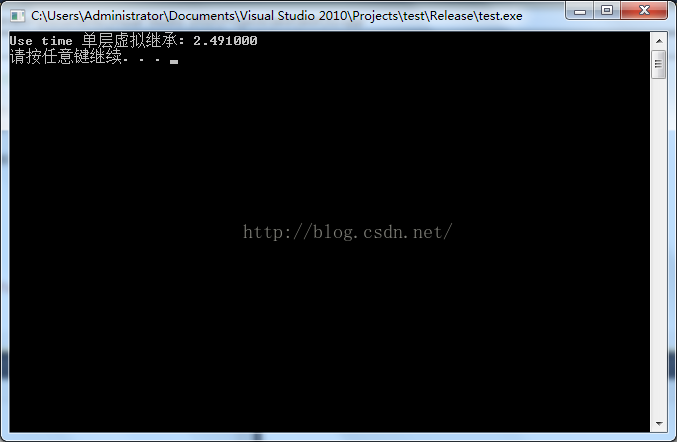
在多層的虛擬繼承情況下呢:
優化的情況下:
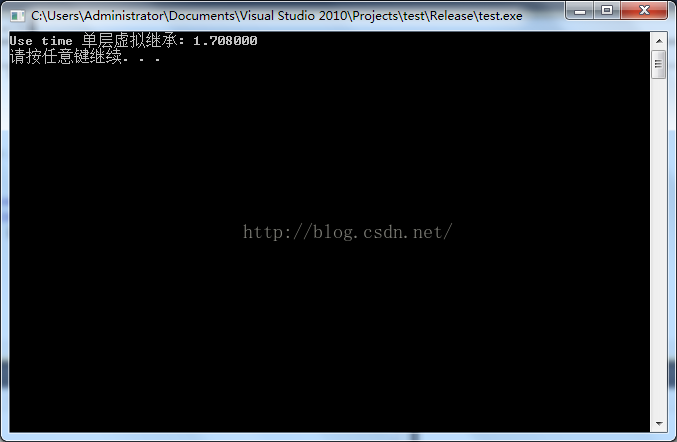
未優化的情況下:
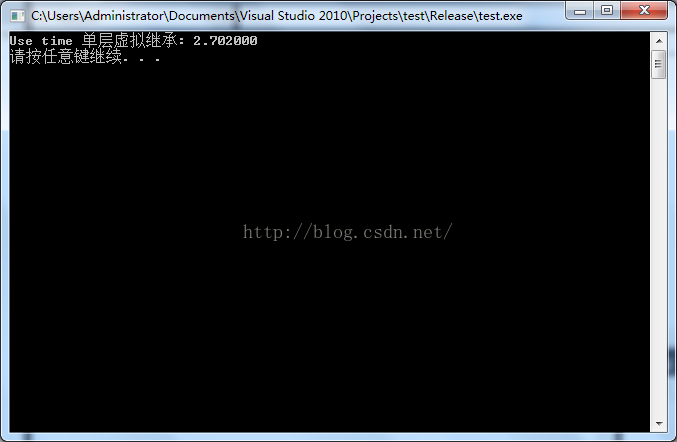
可以看到,對於虛擬繼承來說,所消耗的時間會比較多些,可能是因為我的測試比較簡單,不是很明顯。
所以能不用虛擬繼承,就不要用吧,除非沒辦法了。