
將在Windows環境下編寫的sh檔案格式轉化為Linux下的sh檔案
先演示一個翻車的現場:
這個是在Linux下編寫的一個shell(B)指令碼:

執行看看:

沒問題,現在在Windows下編寫一個:
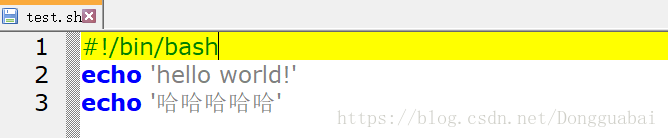
儲存後上傳至虛擬機器,執行發現居然報錯了:

檢視一下test.sh內容:

根本沒什麼問題啊,這時候再用cat -A檢視看看:

cat -A是檢視檔案中的所有內容,包括隱藏字元!
在Linux中回車符識別為$符號,但是在test.sh檔案中由於是在Windows下編寫的,回車為^M$,所以就發生了格式不匹配,無法執行指令碼。
將Windows格式轉化為Linux格式
其實很簡單,執行一個命令dos2unix即可:
額,我這裡沒有,安裝一下:

cat -A看看:

發現格式已經轉換過來了,可以直接執行了:

相關推薦
將在Windows環境下編寫的sh檔案格式轉化為Linux下的sh檔案
先演示一個翻車的現場: 這個是在Linux下編寫的一個shell(B)指令碼: 執行看看: 沒問題,現在在Windows下編寫一個: 儲存後上傳至虛擬機器,執行發現居然報錯了: 檢視一下test.sh內容: 根本沒什麼問題啊,這時候再用cat -A檢視
如何實現在Windows下編寫的程式碼,直接在Linux下編譯
方法一: 如何實現在Windows7下編寫Linux程式,寫完程式以後,不用拷貝檔案,直接在Linux(RHEL6.5)機器上編譯最新的程式碼。 1.首先將Windows的程式碼資料夾設定為共享資料夾: 2.在RHEL6.5上,利用mount命令把Win7下的資料夾給mount到本地的一個
在Windows下編寫的程式碼,實時在Linux下編譯
方法一: 如何實現在Windows7下編寫Linux程式,寫完程式以後,不用拷貝檔案,直接在Linux(RHEL6.5)機器上編譯最新的程式碼。 1.首先將Windows的程式碼資料夾設定為共享資料夾: 2.在RHEL6.5上,利用mount命令
用fastjson將物件的列表轉換成json格式,並讀寫.json檔案
import com.alibaba.fastjson.JSON; import org.json.JSONArray; import org.json.JSONObject; public static void main(String[] args) {
利用python實現 CAD STEP格式轉化為STL格式--update 對整個資料夾下的所有檔案進行轉換格式
update # 匯入FreeCAD 路徑為FreeCAD安裝路徑,bin檔案裡有個檔案叫 FreeCad.pyd 這是關鍵 import sys sys.path.append('C:\\Software\\FreeCAD 0.17\\bin') import FreeC
Http請求格式(在Linux下使用telnet親測,通過這篇我才明白)
語法 設置 rdquo 我們 令行 ati 訪問性 idl lib 命令行窗口中用telnet測試HTTP協議請求消息格式響應消息格式1. 命令行窗口中用telnet測試HTTP協議 HTTP消息是由普通ASCII文本組成。消息包括消息頭和數據體部分。消息頭以行為單位,每行
TensorFlow 自定義模型導出:將 .ckpt 格式轉化為 .pb 格式
clear sin onf iat arr keys 部分 use oci 本文承接上文 TensorFlow-slim 訓練 CNN 分類模型(續),闡述通過 tf.contrib.slim 的函數 slim.learning.train 訓練的模型,怎麽通過人為的
ubuntu 18.04下greenplum安裝筆記(一)Linux下基礎環境的搭建
背景 需要構建一個用於資料倉庫的分散式資料庫叢集。 每一個節點暫時不需要進行備份,同時也不考慮壞掉的情況。 每一個數據節點最好都不用進行過多的配置,安裝起來方便。 Greenplum的Shared-Nothing的設計思路很適合我目前的業務場景。 物理環境 4檯安裝了Linux的主機,安裝的作業系統的版本均為
將自己手動標註的資料集(PascalVOC格式)轉化為.TFRecord格式
“ 一個人如果不能學會遺忘,那將是很痛苦的事,別再自尋煩惱,快把痛苦的事給忘了吧!” 為了能夠使用Object Detection API~ 需要將資料集格式轉化為.TFRecord再進行訓練~ 至於, 如何使用Tensorflow官方的Objec
tensorflow2caffe(3) : 如何將tensorflow框架下訓練得到的權重轉化為caffe框架下的權重引數
在前兩期專欄tensorflow2caffe(1)和tensorflow2caffe(2)中,筆者向大家介紹了caffemodel檔案型別下的引數架構和如何取出tensorflow框架下訓練引數。在本期中,筆者將向大家闡述,如何去將tensorflow框架下訓練得到的引
【轉發】centos 7開啟FTP以及新增使用者配置許可權,只允許訪問自身目錄,不能跳轉根目錄 linux下ftp配置檔案詳解
1.切換到root使用者 2.檢視是否安裝vsftp,我這個是已經安裝的。 [[email protected] vsftpd]# rpm -qa |grep vsftpd vsftpd-3.0.2-11.el7_2.x86_64 3.如果沒有發現,則安裝。 yum ins
windows下用caffe載入二進位制模型(linux下訓練)的問題
最近,需要移植faster-rcnn的detect部分到android平臺上,為方便刪減程式碼與除錯,需要跨平臺相容到windows下執行,windows下除錯的時候,用的是linux下的模型定義proto與訓練好的二進位制模型,但是,一直載入模型不成功,逐步解決方法如下:
java amr格式轉mp3格式(完美解決Linux下轉換0K問題)
因專案需求,需要將 amr 格式的檔案轉成 mp3格式。 網路上提供的思路大多是使用jave-x-x.jar。 這個包確實有用,因為開發時是在windows環境中,測試轉換雖然報了異常: 1 it.sauronsoftware.jave.EncoderExcepti
MP4檔案格式的解析,以及MP4檔案的分割演算法
mp4應該算是一種比較複雜的媒體格式了,起源於QuickTime。以前研究的時候就花了一番的功夫,尤其是如何把它完美的融入到視訊點播應用中,更是費盡了心思,主要問題是處理mp4檔案龐大的“媒體頭”。當然,流媒體點播也可以採用flv格式來做,flv也可以封裝H.264視訊資料的
【轉】Linux下配置檔案讀取操作流程及其C程式碼實現
轉自:http://blog.csdn.net/zhouzhaoxiong1227/article/details/45563263#comments 一、概述 Linux具有免費、可靠、安全、穩定、多平臺等特點,因此深受廣大程式設計師的歡迎。 為了體現軟體產品的靈活性,可新增配置檔案存放某些重要的
將Windows本機的thinkPHP專案上傳到Linux伺服器(阿里雲伺服器)
之前還沒買伺服器的時候,同學將他的伺服器借我玩玩,我就將自己之前寫的thinkPHP簡陋的部落格專案上傳到上面試了一下, 雖然也碰到錯誤,最後通過百度都成功解決,詳見前面的博文。前幾天買
windows下登入samba伺服器後無法訪問linux下共享目錄,提示沒有許可權。
1、確保linux下防火牆關閉或者是開放共享目錄許可權 iptalbes -F 2、確保samba伺服器配置檔案smb.conf設定沒有問題,可網上查閱資料看配置辦法 3、確保setlinux關閉,可以用setenforce 0命令執行。 預設的,SELinux禁止網路上對Samba伺服器上的共享目錄進行
將UCS-2 Little Endian(即 utf-16)編碼的txt檔案批量轉化為utf-8編碼(python)
折騰了好久,終於搞定了。參考連結:python使用codecs模組進行檔案操作-讀寫中英文字元 - CSDN部落格 http://blog.csdn.net/chenyxh2005/article/details/72465758#t0程式碼:import os import
windows下eclipse工程轉到linux下原始碼註釋以及輸出字串中中文亂碼解決方法
問題出在在windows上面原始碼檔案的編碼方式用cp936,也就是gbk字符集的編碼方式。而linux下預設是utf-8的編碼方式。所以產生了亂碼。 我的解決辦法是: 用vim開啟要轉碼的檔案,在vim中沒有亂碼,必須要無亂碼,如果還有亂碼說明檔案解碼
將xml檔案物件轉化為Map物件
一、基本思路 先將xml檔案轉化為document物件,並獲取到根節點,然後依次遍歷二級節點 如果二級節點擁有子節點的話:進入遞迴 如果二級節點沒有子節點的話:將資料封裝在本層Map 中 如果二級節點部分擁有子節點,部分沒有子節點,那麼進行特殊處理。 二、具體程式碼