
單例模式與全域性唯一id的思考----c++ ,c ,python 實現
前段時間去考了系統架構師,排錯題基本全是設計模式的內容。設計模式真的這麼重要麼?答案是肯定的,沒有設計模式就沒有現在複雜的軟體系統。
於是,我想要慢慢的花兩個月時間,重拾語言關,再者c++的設計模式網上實現比較少,我就來幫助大家蒐集一下,當然實現方式還是我喜歡的c,c++,python三種語言分別實現。
Christopher Alexander 說過:“每一個模式描述了一個在我們周圍不斷重複發生的問題,以及該問題的解決方案的核心,這樣,你就能一次又一次地使用該方案而不必做重複勞動。”第一個設計模式,我選擇單例模式

1.設計模式縱覽
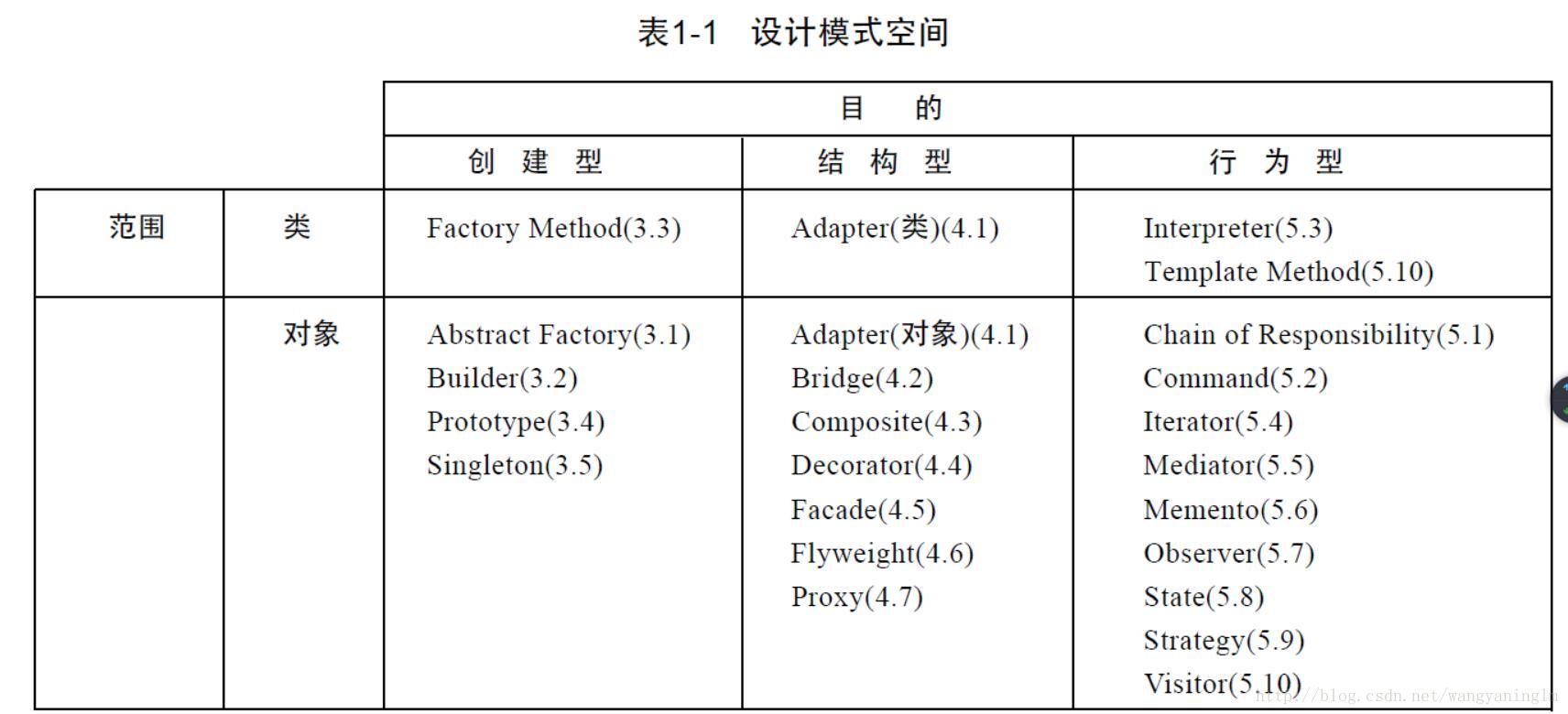
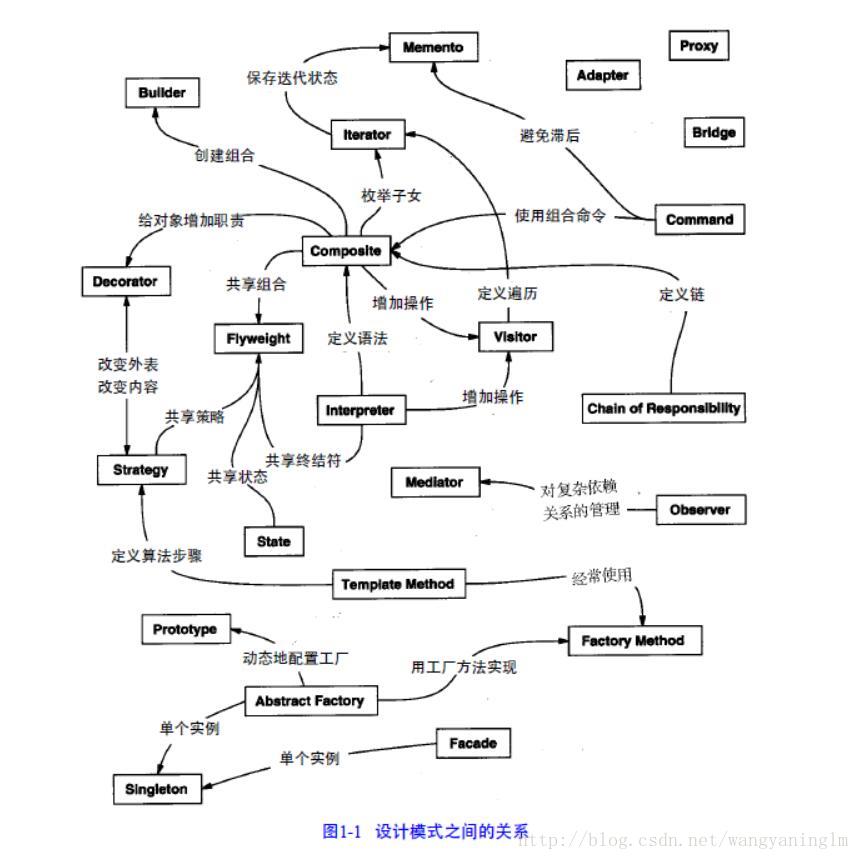
1、單一職責原則(Single Responsibility Principle)
就一個類而言,應該僅有一個引起它變化的原因。一個類只做一件事。
2、開閉原則(Open Close Principle)
對擴充套件開放,對修改關閉。
3、里氏代換原則(Liskov Substitution Principle)
任何基類可以出現的地方,子類一定可以出現。
4、依賴倒轉原則(Dependence Inversion Principle)
真對介面程式設計,依賴於抽象而不依賴於具體。
5、介面隔離原則(Interface Segregation Principle)
使用多個隔離的介面,比使用單個介面要好。
6、迪米特法則(最少知道原則)(Demeter Principle)
一個實體應當儘量少的與其他實體之間發生相互作用,使得系統功能模組相對獨立。
2.單例模式應該考慮執行緒安全!
單例模式的應用場景
有很多地方需要單例模式這樣的功能模組,如系統的日誌輸出,GUI應用必須是單滑鼠,MODEM的聯接需要一條且只需要一條電話線,作業系統只能有一個視窗管理器,一臺PC連一個鍵盤。
通過單例模式, 可以做到:
(1)確保一個類只有一個例項被建立
(2)提供了一個對物件的全域性訪問指標
(3)在不影響單例類的客戶端的情況下允許將來有多個例項
2.1 教科書裡的單例模式
我們都很清楚一個簡單的單例模式該怎樣去實現:建構函式宣告為private或protect防止被外部函式例項化,內部儲存一個private static的類指標儲存唯一的例項,例項的動作由一個public的類方法代勞,該方法也返回單例類唯一的例項。
上程式碼:
class singleton
{
protected:
singleton(){}
private:
static singleton* p;
public:
static singleton* instance();
};
singleton* singleton::p = NULL;
singleton* singleton::instance()
{
if (p == NULL)
p = new singleton();
return p;
}這是一個很棒的實現,簡單易懂。但這是一個完美的實現嗎?不!該方法是執行緒不安全的,考慮兩個執行緒同時首次呼叫instance方法且同時檢測到p是NULL值,則兩個執行緒會同時構造一個例項給p,這是嚴重的錯誤!同時,這也不是單例的唯一實現!
2.2 懶漢與餓漢
單例大約有兩種實現方法:懶漢與餓漢。
懶漢:故名思義,不到萬不得已就不會去例項化類,也就是說在第一次用到類例項的時候才會去例項化,所以上邊的經典方法被歸為懶漢實現;
餓漢:餓了肯定要飢不擇食。所以在單例類定義的時候就進行例項化。
特點與選擇:
由於要進行執行緒同步,所以在訪問量比較大,或者可能訪問的執行緒比較多時,採用餓漢實現,可以實現更好的效能。這是以空間換時間。
在訪問量較小時,採用懶漢實現。這是以時間換空間。
2.3 執行緒安全的懶漢實現
執行緒不安全,怎麼辦呢?最直觀的方法:加鎖。訪問量大有可能成為嚴重的效能瓶頸
方法1:
加鎖的經典懶漢實現:
class singleton
{
protected:
singleton() {}
private:
static singleton* p;
public:
static pthread_mutex_t mutex;
static singleton* initance();
};
pthread_mutex_t singleton::mutex;
singleton* singleton::p = NULL;
singleton* singleton::initance()
{
if (p == NULL)
{
pthread_mutex_lock(&mutex);
if (p == NULL)
p = new singleton();
pthread_mutex_unlock(&mutex);
}
return p;
}
方法2:內部靜態變數的懶漢實現
此方法也很容易實現,在instance函式裡定義一個靜態的例項,也可以保證擁有唯一例項,在返回時只需要返回其指標就可以了。推薦這種實現方法,真得非常簡單。
class singleton
{
protected:
singleton()
{
pthread_mutex_init(&mutex);
}
public:
static pthread_mutex_t mutex;
static singleton* initance();
int a;
};
pthread_mutex_t singleton::mutex;
singleton* singleton::initance()
{
pthread_mutex_lock(&mutex);
static singleton obj;
pthread_mutex_unlock(&mutex);
return &obj;
}
4 餓漢實現
為什麼我不講“執行緒安全的餓漢實現”?因為餓漢實現本來就是執行緒安全的,不用加鎖。為啥?自己想!
class singleton
{
protected:
singleton() {}
private:
static singleton* p;
public:
static singleton* initance();
};
singleton* singleton::p = new singleton;
singleton* singleton::initance()
{
return p;
}是不是特別簡單呢?以空間換時間,你說簡單不簡單?
面試的時候,執行緒安全的單例模式怎麼寫?肯定怎麼簡單怎麼寫呀!餓漢模式反而最懶!
windows 下這麼寫:
#include "stdafx.h"
using namespace std;
class SingletonStatic
{
private:
static const SingletonStatic* m_instance;
SingletonStatic() {}
public:
static const SingletonStatic* getInstance()
{
return m_instance;
}
};
//外部初始化 before invoke main
const SingletonStatic* SingletonStatic::m_instance = new SingletonStatic;
int main()
{
const SingletonStatic* temp_instance = SingletonStatic::getInstance();
return 0;
}
單例的析構
C++單例模式類CSingleton有以下特徵:
它有一個指唯一例項的靜態指標m_pInstance,並且是私有的。
它有一個公有的函式,可以獲取這個唯一的例項,並在需要的時候建立該例項。
它的建構函式是私有的,這樣就不能從別處建立該類的例項。
大多時候,這樣的實現都不會出現問題。有經驗的讀者可能會問,m_pInstance指向的空間什麼時候釋放呢?更嚴重的問題是,這個例項的析構操作什麼時候執行?
如果在類的析構行為中有必須的操作,比如關閉檔案,釋放外部資源,那麼上面所示的程式碼無法實現這個要求。我們需要一種方法,正常地刪除該例項。
可以在程式結束時呼叫GetInstance並對返回的指標呼叫delete操作。這樣做可以實現功能,但是不僅很醜陋,而且容易出錯。因為這樣的附加程式碼很容易被忘記,而且也很難保證在delete之後,沒有程式碼再呼叫GetInstance函式。
一個妥善的方法是讓這個類自己知道在合適的時候把自己刪除。或者說把刪除自己的操作掛在系統中的某個合適的點上,使其在恰當的時候自動被執行。
我們知道,程式在結束的時候,系統會自動析構所有的全域性變數。事實上,系統也會析構所有的類的靜態成員變數,就像這些靜態成員也是全域性變數一樣。利用這個特徵,我們可以在單例類中定義一個這樣的靜態成員變數,而它的唯一工作就是在解構函式中刪除單例類的例項。如下面的程式碼中的CGarbo類(Garbo意為垃圾工人):
class CSingleton:
{
// 其它成員
public:
static CSingleton * GetInstance()
private:
CSingleton(){};
static CSingleton * m_pInstance;
class CGarbo // 它的唯一工作就是在解構函式中刪除CSingleton的例項
{
public:
~CGarbo()
{
if (CSingleton::m_pInstance)
delete CSingleton::m_pInstance;
}
};
static CGarbo Garbo; // 定義一個靜態成員,在程式結束時,系統會呼叫它的解構函式
};類CGarbo被定義為CSingleton的私有內嵌類,以防該類被在其它地方濫用。
在程式執行結束時,系統會呼叫CSingleton的靜態成員Garbo的解構函式,該解構函式會刪除單例的唯一例項。
使用這種方法釋放C++單例模式物件有以下特徵:
在單例類內部定義專有的巢狀類。
在單例類內定義私有的專門用於釋放的靜態成員。
利用程式在結束時析構全域性變數的特性,選擇最終的釋放時機。
3.python需要單例麼?
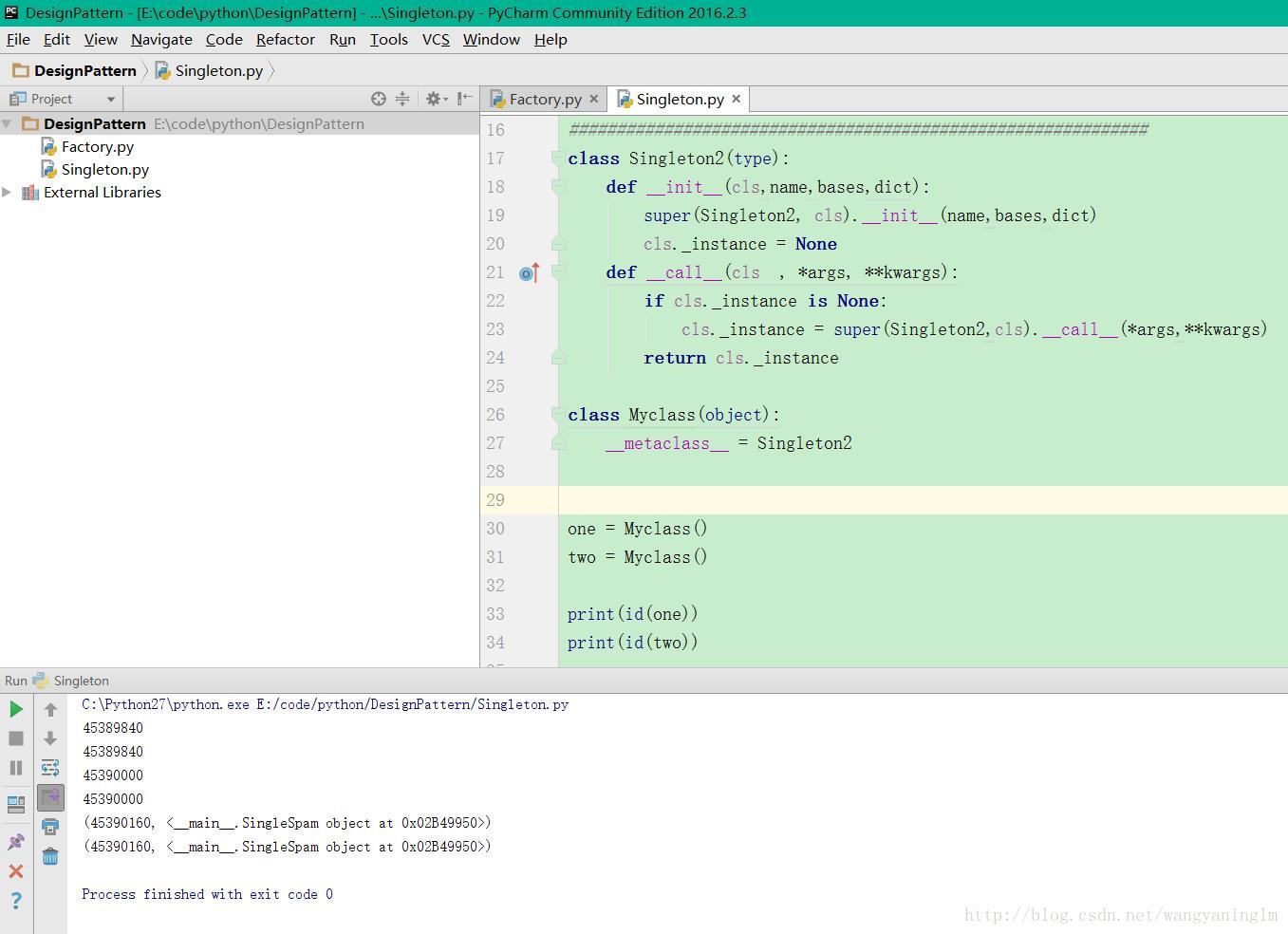
python2和python3的執行結果還有差異
#-*- encoding=utf-8 -*-
'''
date = 20171127
Singleton pattern
'''
###經典單例模式的實現
class Singleton(object):
def __new__(cls, *args, **kwargs):
if not hasattr(cls,'_instance'):
org = super(Singleton,cls)
cls._instance = org.__new__(cls)#cls,*args,**kwargs)
return cls._instance
#############################################################
class Singleton2(type):
def __init__(cls,name,bases,dict):
super(Singleton2, cls).__init__(name,bases,dict)
cls._instance = None
def __call__(cls , *args, **kwargs):
if cls._instance is None:
cls._instance = super(Singleton2,cls).__call__(*args,**kwargs)
return cls._instance
class Myclass(object):
__metaclass__ = Singleton2
one = Myclass()
two = Myclass()
print(id(one))
print(id(two))
###############################################
def singleton3(cls, *args, **kw):
instances = {}
def _singleton():
if cls not in instances:
instances[cls] = cls(*args, **kw)
return instances[cls]
return _singleton
@singleton3
class Myclass2(object):
a = 1
def __init__(self, x=0):
self.x = x
three = Myclass2()
four = Myclass2()
print(id(three))
print(id(four))
#######################################
if __name__=='__main__':
class SingleSpam(Singleton):
def __init__(self,s):
self.s = s
def __str__(self):
return self.s
s1 = SingleSpam('shiter')
print( id(s1),s1)
s2 = SingleSpam('wynshiter')
print(id(s2), s2)
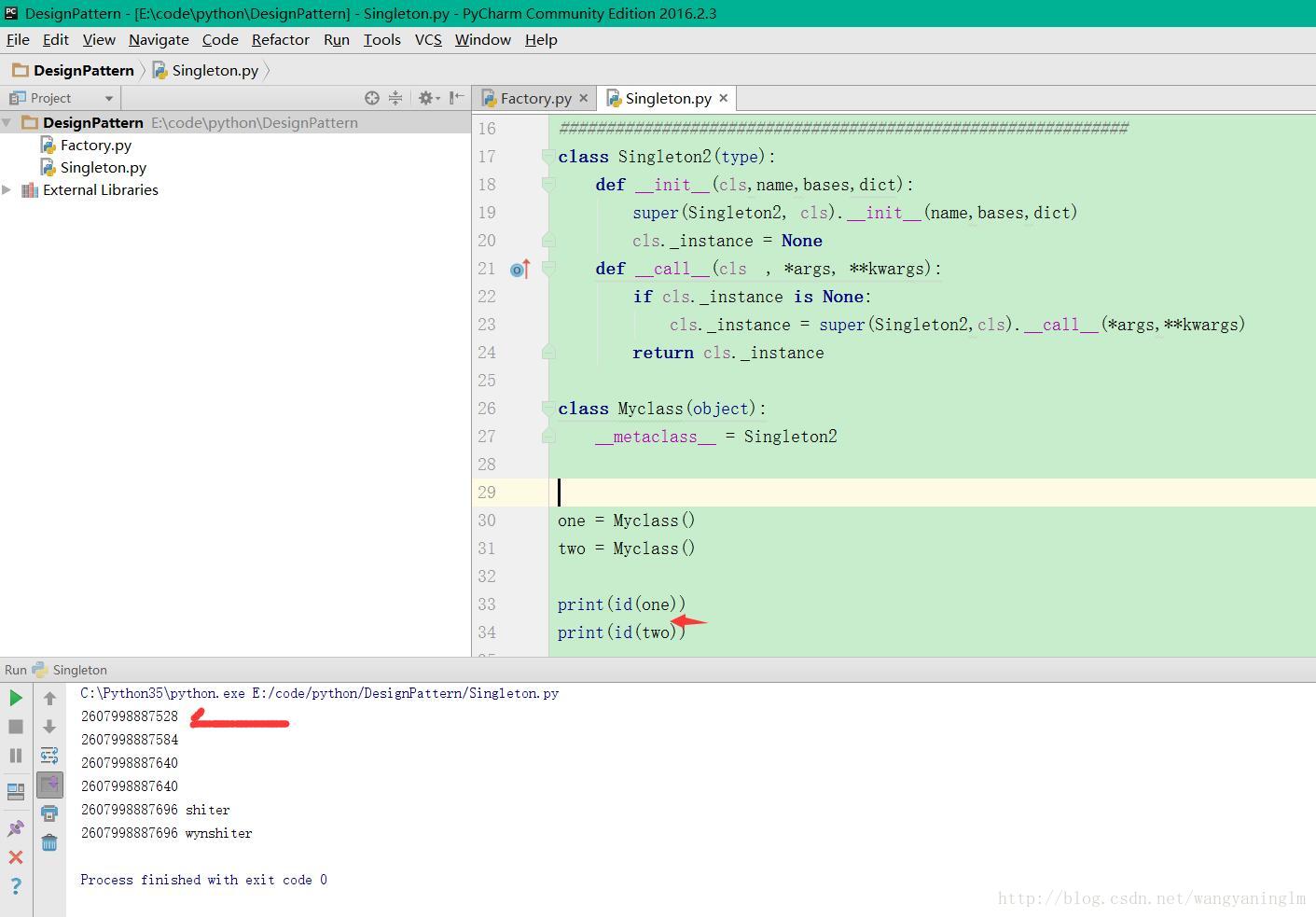
python3執行結果
python2執行結果
4.c語言設計模式也存在嗎?
討論帖子:
zookeeper分散式協調服務
分散式系統唯一ID生成方案彙總(下一篇)
1. 資料庫自增長序列或欄位
最常見的方式。利用資料庫,全資料庫唯一。
優點:
1)簡單,程式碼方便,效能可以接受。
2)數字ID天然排序,對分頁或者需要排序的結果很有幫助。
缺點:
1)不同資料庫語法和實現不同,資料庫遷移的時候或多資料庫版本支援的時候需要處理。
2)在單個數據庫或讀寫分離或一主多從的情況下,只有一個主庫可以生成。有單點故障的風險。
3)在效能達不到要求的情況下,比較難於擴充套件。
4)如果遇見多個系統需要合併或者涉及到資料遷移會相當痛苦。
5)分表分庫的時候會有麻煩。
優化方案:
1)針對主庫單點,如果有多個Master庫,則每個Master庫設定的起始數字不一樣,步長一樣,可以是Master的個數。比如:Master1 生成的是 1,4,7,10,Master2生成的是2,5,8,11 Master3生成的是 3,6,9,12。這樣就可以有效生成叢集中的唯一ID,也可以大大降低ID生成資料庫操作的負載。
2. UUID
常見的方式。可以利用資料庫也可以利用程式生成,一般來說全球唯一。
優點:
1)簡單,程式碼方便。
2)生成ID效能非常好,基本不會有效能問題。
3)全球唯一,在遇見資料遷移,系統資料合併,或者資料庫變更等情況下,可以從容應對。
缺點:
1)沒有排序,無法保證趨勢遞增。
2)UUID往往是使用字串儲存,查詢的效率比較低。
3)儲存空間比較大,如果是海量資料庫,就需要考慮儲存量的問題。
4)傳輸資料量大
5)不可讀。
- UUID的變種
1)為了解決UUID不可讀,可以使用UUID to Int64的方法。及
///
/// 根據GUID獲取唯一數字序列
///
public static long GuidToInt64()
{
byte[] bytes = Guid.NewGuid().ToByteArray();
return BitConverter.ToInt64(bytes, 0);
}
1
2)為了解決UUID無序的問題,NHibernate在其主鍵生成方式中提供了Comb演算法(combined guid/timestamp)。保留GUID的10個位元組,用另6個位元組表示GUID生成的時間(DateTime)。
///
/// Generate a new using the comb algorithm.
///
private Guid GenerateComb()
{
byte[] guidArray = Guid.NewGuid().ToByteArray();
DateTime baseDate = new DateTime(1900, 1, 1);
DateTime now = DateTime.Now;
// Get the days and milliseconds which will be used to build
//the byte string
TimeSpan days = new TimeSpan(now.Ticks - baseDate.Ticks);
TimeSpan msecs = now.TimeOfDay;
// Convert to a byte array
// Note that SQL Server is accurate to 1/300th of a
// millisecond so we divide by 3.333333
byte[] daysArray = BitConverter.GetBytes(days.Days);
byte[] msecsArray = BitConverter.GetBytes((long)
(msecs.TotalMilliseconds / 3.333333));
// Reverse the bytes to match SQL Servers ordering
Array.Reverse(daysArray);
Array.Reverse(msecsArray);
// Copy the bytes into the guid
Array.Copy(daysArray, daysArray.Length - 2, guidArray,
guidArray.Length - 6, 2);
Array.Copy(msecsArray, msecsArray.Length - 4, guidArray,
guidArray.Length - 4, 4);
return new Guid(guidArray);
}
用上面的演算法測試一下,得到如下的結果:作為比較,前面3個是使用COMB演算法得出的結果,最後12個字串是時間序(統一毫秒生成的3個UUID),過段時間如果再次生成,則12個字串會比圖示的要大。後面3個是直接生成的GUID。
如果想把時間序放在前面,可以生成後改變12個字串的位置,也可以修改演算法類的最後兩個Array.Copy。
4. Redis生成ID
當使用資料庫來生成ID效能不夠要求的時候,我們可以嘗試使用Redis來生成ID。這主要依賴於Redis是單執行緒的,所以也可以用生成全域性唯一的ID。可以用Redis的原子操作 INCR和INCRBY來實現。
可以使用Redis叢集來獲取更高的吞吐量。假如一個叢集中有5臺Redis。可以初始化每臺Redis的值分別是1,2,3,4,5,然後步長都是5。各個Redis生成的ID為:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
這個,隨便負載到哪個機確定好,未來很難做修改。但是3-5臺伺服器基本能夠滿足器上,都可以獲得不同的ID。但是步長和初始值一定需要事先需要了。使用Redis叢集也可以方式單點故障的問題。
另外,比較適合使用Redis來生成每天從0開始的流水號。比如訂單號=日期+當日自增長號。可以每天在Redis中生成一個Key,使用INCR進行累加。
優點:
1)不依賴於資料庫,靈活方便,且效能優於資料庫。
2)數字ID天然排序,對分頁或者需要排序的結果很有幫助。
缺點:
1)如果系統中沒有Redis,還需要引入新的元件,增加系統複雜度。
2)需要編碼和配置的工作量比較大。
- Twitter的snowflake演算法
snowflake是Twitter開源的分散式ID生成演算法,結果是一個long型的ID。其核心思想是:使用41bit作為毫秒數,10bit作為機器的ID(5個bit是資料中心,5個bit的機器ID),12bit作為毫秒內的流水號(意味著每個節點在每毫秒可以產生 4096 個 ID),最後還有一個符號位,永遠是0。具體實現的程式碼可以參看https://github.com/twitter/snowflake。
snowflake演算法可以根據自身專案的需要進行一定的修改。比如估算未來的資料中心個數,每個資料中心的機器數以及統一毫秒可以能的併發數來調整在演算法中所需要的bit數。
優點:
1)不依賴於資料庫,靈活方便,且效能優於資料庫。
2)ID按照時間在單機上是遞增的。
缺點:
1)在單機上是遞增的,但是由於涉及到分散式環境,每臺機器上的時鐘不可能完全同步,也許有時候也會出現不是全域性遞增的情況。
- 利用zookeeper生成唯一ID
zookeeper主要通過其znode資料版本來生成序列號,可以生成32位和64位的資料版本號,客戶端可以使用這個版本號來作為唯一的序列號。
很少會使用zookeeper來生成唯一ID。主要是由於需要依賴zookeeper,並且是多步呼叫API,如果在競爭較大的情況下,需要考慮使用分散式鎖。因此,效能在高併發的分散式環境下,也不甚理想。
- MongoDB的ObjectId
MongoDB的ObjectId和snowflake演算法類似。它設計成輕量型的,不同的機器都能用全域性唯一的同種方法方便地生成它。MongoDB 從一開始就設計用來作為分散式資料庫,處理多個節點是一個核心要求。使其在分片環境中要容易生成得多。
其格式如下:
前4 個位元組是從標準紀元開始的時間戳,單位為秒。時間戳,與隨後的5 個位元組組合起來,提供了秒級別的唯一性。由於時間戳在前,這意味著ObjectId 大致會按照插入的順序排列。這對於某些方面很有用,如將其作為索引提高效率。這4 個位元組也隱含了文件建立的時間。絕大多數客戶端類庫都會公開一個方法從ObjectId 獲取這個資訊。
接下來的3 位元組是所在主機的唯一識別符號。通常是機器主機名的雜湊值。這樣就可以確保不同主機生成不同的ObjectId,不產生衝突。
為了確保在同一臺機器上併發的多個程序產生的ObjectId 是唯一的,接下來的兩位元組來自產生ObjectId 的程序識別符號(PID)。
前9 位元組保證了同一秒鐘不同機器不同程序產生的ObjectId 是唯一的。後3 位元組就是一個自動增加的計數器,確保相同程序同一秒產生的ObjectId 也是不一樣的。同一秒鐘最多允許每個程序擁有2563(16 777 216)個不同的ObjectId。
實現的原始碼可以到MongoDB官方網站下載。