
3 SparkStreaming執行機制和架構進階
內容:
1. 解密Spark Streaming Job架構和執行機制
2. 機密Spark Streaming容錯架構和執行機制
一、SparkStreaming Job架構與執行機制
為了更好的理解SparkStreaming Job架構,我們先來看一個例子:
package com.dt.spark.Streaming import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} /** *使用foreachRDD將Spark Streaming處理的結果放到DataBase中 * @author DT大資料夢工廠 * 新浪微博:http://weibo.com/ilovepains/ * Created by pc-Hipparic on 2016/5/22. */ object OnlineForeachRDD2DB { def main(args: Array[String]) { val conf = new SparkConf() conf.setAppName("OnlineforeachRDD2DB").setMaster(“local[6]”) //設定batchDuration時間間隔來控制Job生成的頻率並且建立Spark Streaming執行的入口 val ssc = new StreamingContext(conf, Seconds(5)) val lines = ssc.socketTextStream("Master",9999) //設計處理邏輯 val words = lines.flatMap(_.split(" ")) val wordCounts = words.map(x => (x,1)).reduceByKey(_ + _) //呼叫foreachRDD進行資料持久化操作 wordCounts.foreachRDD(rdd => rdd.foreachPartition{ partitionOfRecords => { //呼叫簡單實現的資料庫連線執行緒池 val connection = ConnectionPool.getConnection() partitionOfRecords.foreach(record => { val sql = "insert into streaming_itemcount(word,count) values('" + record._1 + "'," + record._2 + ")" val stmt = connection.createStatement() stmt.executeUpdate(sql); }) ConnectionPool.returnConnection(connection) } }) /** *在StreamingContext#start內部會呼叫JobScheduler#star,進行訊息迴圈,在 *JobScheduler#start內部會構造JobGenerator和ReceiverTacker,並呼叫JobGenerator#start和 *ReceiverTacker#start(見2) */ ssc.start() ssc.awaitTermination() } }
這裡,我們將資料持久化到了mysql中。
結果如下:


為了更好了解每一步以及涉及的核心元件,來看下日誌資訊。
16/05/24 01:07:46 INFO scheduler.ReceiverTracker: All of the receivers have deregistered successfully 16/05/24 01:07:46 INFO scheduler.ReceiverTracker: ReceiverTracker stopped 16/05/24 01:07:46 INFO scheduler.JobGenerator: Stopping JobGenerator immediately 16/05/24 01:07:46 INFO util.RecurringTimer: Stopped timer for JobGenerator after time 1464023265000 16/05/24 01:07:46 INFO scheduler.JobGenerator: Stopped JobGenerator 16/05/24 01:07:46 INFO scheduler.JobScheduler: Stopped JobScheduler 16/05/24 01:07:46 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/streaming,null} //省略部分日誌
這裡可以看見,在SparkStreaming程式被停止時,有Receviver被停掉,還有ReceiveTracker、JobGenerator、RecurringTime、Scheduler等元件一起控制Spark Streaming。
接下來我們再來看看上節課的SparkStreaming的執行圖:
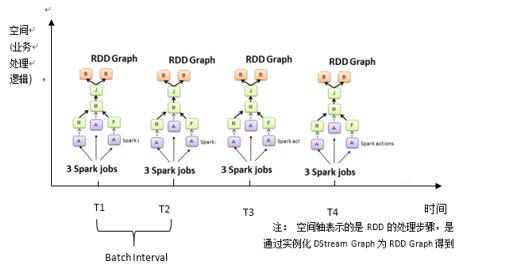

正如上節課所述,隨著時間的流逝,SparkStreaming會不斷的生成Job,那麼問題來了,這些Job是怎麼生成的呢?
在StreamingContext中,首先會呼叫過載構造器,然後在過載構造其中對一些成員進行初始化操作。
例如graph(DStream Graph):
private[streaming] val graph: DStreamGraph = { //如果進行了Checkpoint操作,則從相應的目錄進行恢復 if (isCheckpointPresent) { cp_.graph.setContext(this) cp_.graph.restoreCheckpointData() cp_.graph } else { //否則構建DstreamGraph物件,並設定BatchDuration(時間間隔) require(batchDur_ != null, "Batch duration for StreamingContext cannot be null") val newGraph = new DStreamGraph() newGraph.setBatchDuration(batchDur_) newGraph } }
Scheduler(作業排程器)
//建立JobScheduler物件。
private[streaming] val scheduler = new JobScheduler(this)
progressListener(事件監聽器)
private[streaming] val progressListener = new StreamingJobProgressListeneStreamingSource等等。
/* Initializing a streamingSource to register metrics */
private val streamingSource = new StreamingSource(this)
但是,我們在檢視這裡的原始碼中沒有發現與作業真正進行執行排程的程式碼,說明此事作業(Job)還未真正開始執行。
返回我們所寫的程式碼,發現在StreamingContext初始化後,就是我們的業務邏輯的程式碼了,這是我們所書寫的業務邏輯即資料處理方式步驟,這其中並沒有action,它也未觸發作業的執行。那麼,作業的真正執行只能是最後一部分的程式碼了,即
// OnlineForeachRDD2DB#main
ssc.start()
ssc.awaitTermination()
為了驗證這個假設,來看看ssc#start方法的原始碼:
//啟動Spark Streaming的執行過程
def start(): Unit = synchronized {
state match {
case INITIALIZED =>
startSite.set(DStream.getCreationSite())
StreamingContext.ACTIVATION_LOCK.synchronized {//省略部分程式碼
//呼叫scheduler#start方法
scheduler.start() //1
}
state = StreamingContextState.ACTIVE
} //省略部分程式碼
}
//JobScheduler#start 1處被呼叫
def start(): Unit = synchronized {
//若訊息迴圈器不為空,表示SparkStreaming已啟動,直接返回
if (eventLoop != null) return
logDebug("Starting JobScheduler")
//建立訊息迴圈器,用來接收訊息
eventLoop = new EventLoop[JobSchedulerEvent]("JobScheduler") {
override protected def onReceive(event: JobSchedulerEvent): Unit = processEvent(event)
override protected def onError(e: Throwable): Unit = reportError("Error in job scheduler", e)
}
//啟動訊息迴圈器,開始接收訊息
eventLoop.start()
// 控制批量接收資料,來更新完成的Batch
for {
inputDStream <- ssc.graph.getInputStreams
rateController <- inputDStream.rateController
} ssc.addStreamingListener(rateController)
//啟動監聽器
listenerBus.start(ssc.sparkContext)
receiverTracker = new ReceiverTracker(ssc)
inputInfoTracker = new InputInfoTracker(ssc)
//呼叫receiveTracker#start啟動receiverTracker
//首先它會在Spark Cluster中啟動Receiver(其實是在Executor中先啟動ReceiverSupervisor來
//啟動Receiver)
receiverTracker.start() //2
//啟動JobGenerator,JobGenerator啟動後會不斷根據batchDuration生成一個個Job
jobGenerator.start()
logInfo("Started JobScheduler")
}
從這裡開始,作業被啟動了,此時Spark Streaming便可以依據時間間隔(Batch Interval)來產生作業了。
通過我們對案例的深入研究發現,對於Spark Streaming來講,需要關注以下幾方面(元件):
(1)JobGenerator
它啟動後,會不斷的產生Job,處理流入的資料;
(2)receiverTracker
receiverTracker啟動的時候會啟動receiver,receiver會接收流入的資料;
(3)JobScheduler
SparkStreaming最為重要的一個元件,JobGenerator和receiverTracker都是由JobScheduler產生的。所以要了解Spark Streaming的核心就必須要掌握這個元件。
執行流程:
JobScheduler在啟動的時候啟動了JobGenerator,通過JobGenerator來不斷產生Job。Job產生時需要輸入資料(RDD),而JobScheduler也會在啟動時啟動receiverTracker,然後Tracker會在Spark 叢集中各個worker上Executor中啟動相應的receiver,receiver在接收到外界輸入的資料時,會通過receiversupervise儲存到Executor,並將Metedata資訊傳送給Driver中的receiverTracker。(receiverTracker負責啟動receiver並且負責接收元資料)。ReceiverTracker內部會通過ReceivedBlockTracker來管理接收到的元資料資訊。Drive在進行作業排程時會通過ReceiverBlockTracker的元資料資訊,來指定Job處理的資料。這樣流入的資料就可以儲存到Spark底層的儲存系統了,此時便可以基於這些資料來產生RDD了。
接下來就是要將處理邏輯作用於資料上進行資料的處理,也就是定時產生Job了。當每個BatchInterval會產生一個具體的Job,其實這裡的Job不是Spark Core中所指的Job,它只是基於DStreamGraph而生成的RDD的DAG而已(從Java的角度來講,就相當Runnable介面的例項),此時想要執行Job需要提交給JobScheduler中通過執行緒池的方式找到一個單獨的執行緒來提交Job到叢集執行(其實是線上程中基於RDD的Action觸發真正的作業的執行)。
1. 為什麼使用執行緒?
1)因為作業不斷產生,所以為了提升效率,需要執行緒池,這和在Executor中通過執行緒池執行由異曲同工之妙。
2)有可能設定Job的FAIR公平排程的方式,這個時候也需要多執行緒的支援。
在JobGenerator中會有一個定時器timer,都過開發者設定的BatchInterval不斷的生成Job。
//JobGenerator#timer
// RecurringTimer不斷地將接收的資料進行分配來生成Job(基於DstreamGraph產生Job)
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds,
longTime => eventLoop.post(GenerateJobs(new Time(longTime))), "JobGenerator")

二 容錯
1.Executor級別容錯
a)接受資料的安全性
SparkStreaming預設情況下,接受到的資料都採用MEMORY_AND_DISK_TWO的方式。即預設情況下,資料會儲存在兩臺機器的記憶體中,如果有一臺機器掛掉,則框架會立即切換到另一臺機器上來執行。在大多數情況下這種策略是比較可靠的,並且框架的切換基本上有切換時間;另一種方式是WAL(writer ahead log)方式,在資料到來時,先把資料通過WAL機制做一個日誌記錄,以後有問題便可以基於日誌恢復,然後在存入Executor中,然後在進行其他機器副本的複製。這種方式是先寫日誌在進行其他操作,如果資料丟失便可通過WAL機制把資料恢復回來。(生產環境下,採用Kafka的回放來實現資料恢復。)
b)執行的安全性
任務(Job)執行的安全性則依賴於RDD的容錯。
2.Driver級別的容錯
Driver級別的容錯需要考慮DStreamGraph(DAG生成的模板)、 ReceiverTracker(接收的資料處理了哪些資料)、JobGenerator(生成作業的進度)等等方面,對於這些容錯,只需要在每個作業生成前進行checkpoint,生成之後再做一次checkpoint即可。如果出錯,則直接從checkpoint中恢復即可。