
Transfer-Encoding:chunked 返回資料過長導致中文亂碼
最近在寫一個專案的後臺時,前端請求指定資源後,返回JSON格式的資料,突然發現在返回的位元組數過大時,最後的message中文資料亂碼了,對於同一個介面的請求:當資料小時不會亂碼,當資料量大了中文就亂碼了。
@RequestMapping(value = "record/{id}",method = RequestMethod.GET)
public void showUserRecord(@PathVariable String id, HttpServletRequest request, HttpServletResponse response){
try - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
基本的Controller程式碼如上,有的人也許一眼發現了問題所在,有人會質疑我的寫法,但是在這裡我想找的不是這個。
對於這個情況,在抓包後得到的狀況如下:(記住大概你覺得陌生的地方,繼續往下看)
HTTP請求過程:

非正常HTTP請求過程:

可以明顯的觀察到,這裡在中文亂碼時出現了更多的TCP資料報。
HTTP報文分析:
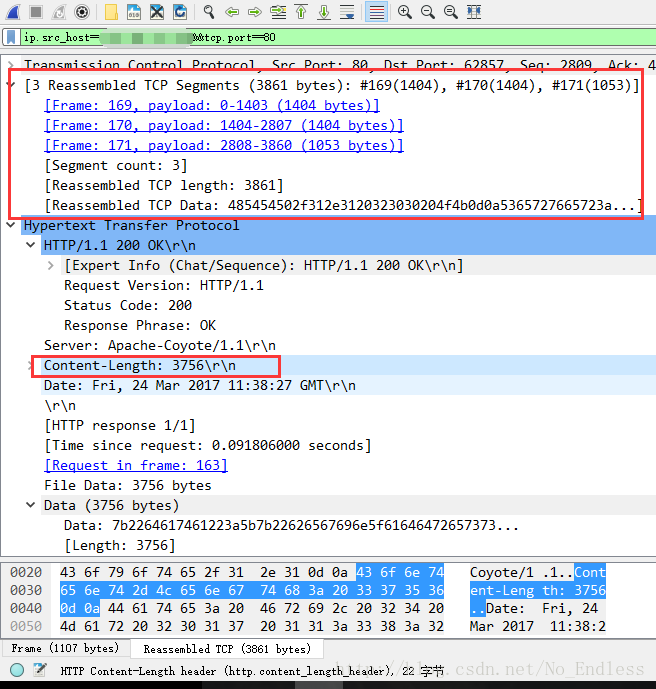
非正常HTTP報文分析:
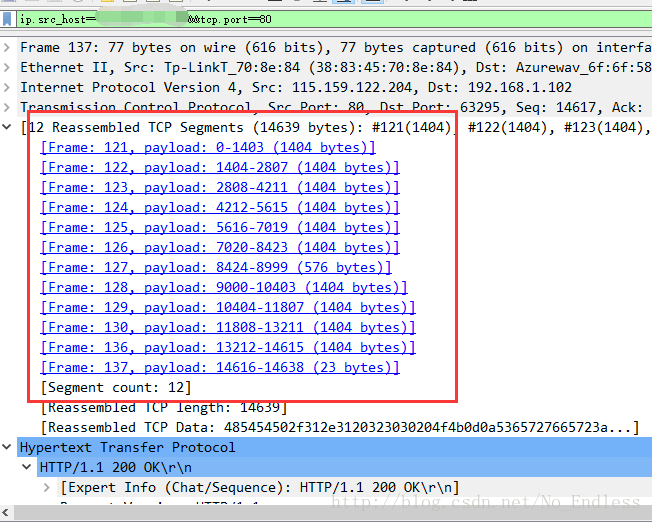
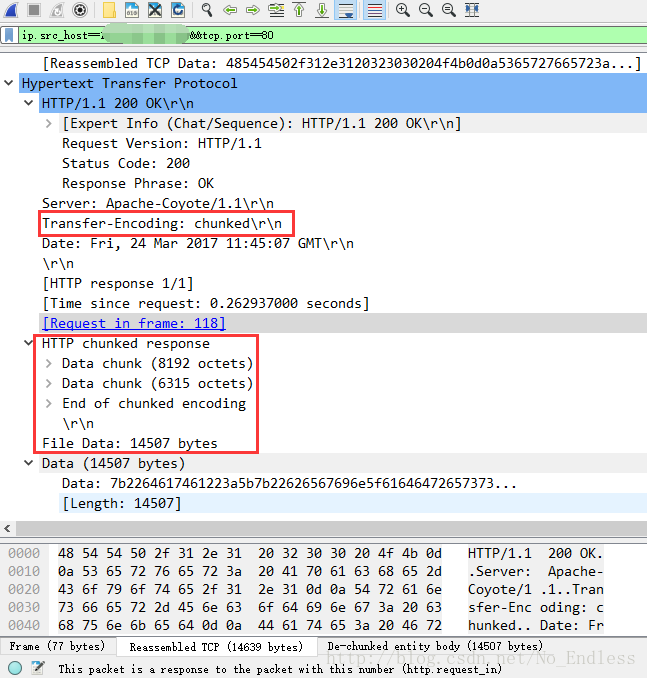
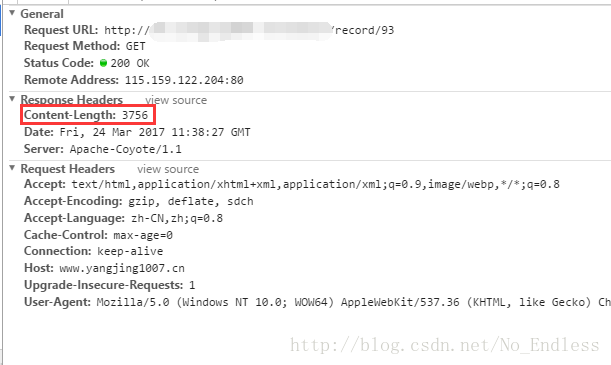
到了抓包的地方,我們就可以觀察到HTTP響應頭髮生了變化,在正常狀態下,會返回Content-Length,但是在資料很多,即中文亂碼的情況下,Content-Length屬性被Transfer-Encoding:chunked屬性取代了。
Chrome瀏覽器分析:
非正常Chrome瀏覽器分析:

執行結果:

非正常執行結果:

結果分析:
一開始想修改一下Chrome瀏覽器的編碼試試,但是發現在Chrome 55之後的版本,字符集編碼的修改功能被移除了。按照Google方面的說法如下:
1) "Auto Detect" option in the hamburger menu. It's a sticky global boolean that turns on a heavy text analyzer to guess the encoding better. It's off by default because it regresses page load time by 10%-20%. By selecting this, users see less gibberish but they make Chrome slower (and don't realize that).
2) Manual encoding selection in the hamburger menu. This is a temporary setting that forces the current tab to the specified encoding, no matter what. It will turn pages into gibberish if the user selects the wrong one.
3) "Default encoding" selector buried in chrome://settings. This specifies which encoding is selected if "Auto Detect" is disabled and the web page doesn't specify its encoding. It defaults to the UI language of the Chrome installation.
- 1
- 2
- 3
- 4
- 5
- 6
大概就是,自動檢查分析字符集的功能雖然使出現亂碼的情況減少,但是拖慢了頁面載入時間大概10%~20%;選擇功能同時會在頁面已經宣告其編碼的情況下有機率地,使使用者因為自己設定的編碼而看到亂碼,所以頁面宣告編碼時,直接呼叫選擇,否則,預設使用Chrome的UI語言。
那麼我們先說說Transfer-Encoding:chunked:
當不能預先確定報文體的長度時,或是報文長度過長時,無法使用Content-Length來指明報文體長度,此時就需要通過Transfer-Encoding域來代替。
Transfer-Encoding:chunked用於http傳送過程的分塊傳輸技術,原因是http伺服器響應的報文長度經常是不可預測的,使用Content-length的實體搜捕並不是總是管用。
分塊技術的意思是說,實體被分成許多的塊(Data chunk),也就是應用層的資料,TCP在傳送的過程中,不對它們做任何的解釋,而是把應用層產生資料全部理解成二進位制流,然後按照一定的長度切成一段的,然後一次性給TCP協議去傳輸,而具體這些二進位制的資料如何做解釋,需要應用層來完成,所以在這之前,一快整體應用層的資料需要等它分成的所有TCP segment到達對方,重新組裝後,應用程式才使用自己的解碼方法還原它們。
而當使用了Transfer-Encoding:chunked時,編碼的格式改變了
分塊傳輸時,我們設定的CharacterEncoding無效了,其實當Transfer-Encoding時,編碼格式就是它的值——chunked,採用chunked編碼方式來進行報文體的傳輸,基本方法是將大塊資料分解成多塊小資料,每塊都可以自指定長度。chunked編碼是HTTP/1.1 RFC裡定義的一種編碼方式,因此所有的HTTP/1.1應用都應當支援此方式。
chunked編碼方式
chunked編碼格式在RFC中定義如下:

chunked編碼為了分塊傳輸資料,將一個數據信息分成多個有自己長度的塊,這樣就允許在不知道長度的情況下動態的去傳輸資料資訊,Chunked-Body分塊由CRLF(回車換行符)進行分隔,包含有一個16進位制的長度size資訊和一個數據為“0”的chunk塊來表示資料傳輸完畢。
寫了這麼多,如果我們回頭看就會發現一些對應的HTTP報文,以及問題的根源!
好吧…對於最後,記得在返回JSON時中加入程式碼段取代簡單的設定字符集:
response.setContentType("text/json; charset=utf-8");- 1
這是我失誤的地方,字符集的指定最後還是被chunk給打敗了,也許是優先順序不夠吧,但是也學到了很多東西。