
谷歌技術"三寶"之BigTable
Bigtable不是關係型資料庫,但是卻沿用了很多關係型資料庫的術語,像table(表)、row(行)、column(列)等。這容易讓讀者誤入歧途,將其與關係型資料庫的概念對應起來,從而難以理解論文。Understanding
HBase and BigTable是篇很優秀的文章,可以幫助讀者從關係型資料模型的思維定勢中走出來。
本質上說,Bigtable是一個鍵值(key-value)對映。按作者的說法,Bigtable是一個稀疏的,分散式的,持久化的,多維的排序對映。
先來看看多維、排序、對映。Bigtable的鍵有三維,分別是行鍵(row key)、列鍵(column key)和時間戳(timestamp),行鍵和列鍵都是位元組串,時間戳是64位整型;而值是一個位元組串。可以用 (row:string,
column:string, time:int64)→string
行鍵可以是任意位元組串,通常有10-100位元組。行的讀寫都是原子性的。Bigtable按照行鍵的字典序儲存資料。Bigtable的表會根據行鍵自動劃分為片(tablet),片是負載均衡的單元。最初表都只有一個片,但隨著表不斷增大,片會自動分裂,片的大小控制在100-200MB。行是表的第一級索引,我們可以把該行的列、時間和值看成一個整體,簡化為一維鍵值對映,類似於:
table{
"1" : {sth.},//一行
"aaaaa" : {sth.},
"aaaab" : {sth.},
"xyz" : {sth.},
"zzzzz" : {sth.}
}列是第二級索引,每行擁有的列是不受限制的,可以隨時增加減少。為了方便管理,列被分為多個列族(column family,是訪問控制的單元),一個列族裡的列一般儲存相同型別的資料。一行的列族很少變化,但是列族裡的列可以隨意新增刪除。列鍵按照family:qualifier格式命名的。這次我們將列拿出來,將時間和值看成一個整體,簡化為二維鍵值對映,類似於:
table{
// ...
"aaaaa" : { //一行
"A:foo" : {sth.},//一列
"A:bar" : {sth.},//一列
"B:" : {sth.} //一列,列族名為B,但是列名是空字串
},
"aaaab" : { //一行
"A:foo" : {sth.},
"B:" : {sth.}
},
// ...
}或者可以將列族當作一層新的索引,類似於:
table{ // ... "aaaaa" : { //一行 "A" : { //列族A "foo" : {sth.}, //一列 "bar" : {sth.} }, "B" : { //列族B "" : {sth.} } }, "aaaab" : { //一行 "A" : { "foo" : {sth.}, }, "B" : { "" : "ocean" } }, // ... }
時間戳是第三級索引。Bigtable允許儲存資料的多個版本,版本區分的依據就是時間戳。時間戳可以由Bigtable賦值,代表資料進入Bigtable的準確時間,也可以由客戶端賦值。資料的不同版本按照時間戳降序儲存,因此先讀到的是最新版本的資料。我們加入時間戳後,就得到了Bigtable的完整資料模型,類似於:
table{
// ...
"aaaaa" : { //一行
"A:foo" : { //一列
15 : "y", //一個版本
4 : "m"
},
"A:bar" : { //一列
15 : "d",
},
"B:" : { //一列
6 : "w"
3 : "o"
1 : "w"
}
},
// ...
}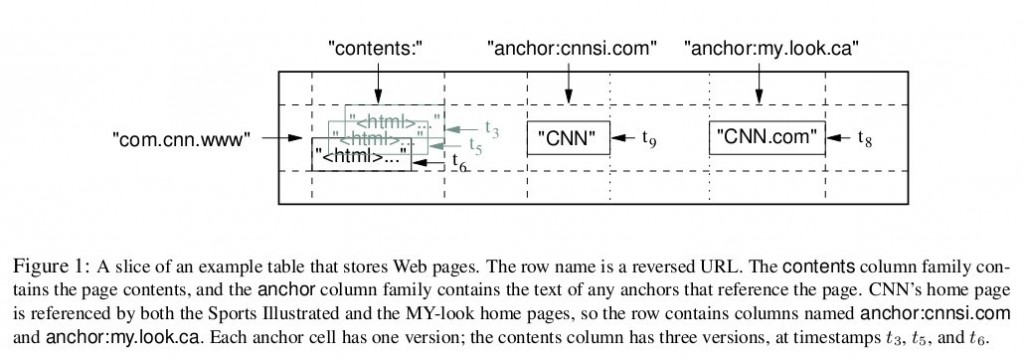
圖1是Bigtable論文裡給出的例子,Webtable表儲存了大量的網頁和相關資訊。在Webtable,每一行儲存一個網頁,其反轉的url作為行鍵,比如maps.google.com/index.html的資料儲存在鍵為com.google.maps/index.html的行裡,反轉的原因是為了讓同一個域名下的子域名網頁能聚集在一起。圖1中的列族"anchor"儲存了該網頁的引用站點(比如引用了CNN主頁的站點),qualifier是引用站點的名稱,而資料是連結文字;列族"contents"儲存的是網頁的內容,這個列族只有一個空列"contents:"。圖1中"contents:"列下儲存了網頁的三個版本,我們可以用("com.cnn.www", "contents:", t5)來找到CNN主頁在t5時刻的內容。
再來看看作者說的其它特徵:稀疏,分散式,持久化。持久化的意思很簡單,Bigtable的資料最終會以檔案的形式放到GFS去。Bigtable建立在GFS之上本身就意味著分散式,當然分散式的意義還不僅限於此。稀疏的意思是,一個表裡不同的行,列可能完完全全不一樣。
3 支撐技術
Bigtable依賴於google的幾項技術。用GFS來儲存日誌和資料檔案;按SSTable檔案格式儲存資料;用Chubby管理元資料。
GFS參見谷歌技術"三寶"之谷歌檔案系統。BigTable的資料和日誌都是寫入GFS的。
SSTable的全稱是Sorted Strings Table,是一種不可修改的有序的鍵值對映,提供了查詢、遍歷等功能。每個SSTable由一系列的塊(block)組成,Bigtable將塊預設設為64KB。在SSTable的尾部儲存著塊索引,在訪問SSTable時,整個索引會被讀入記憶體。BigTable論文沒有提到SSTable的具體結構,LevelDb日知錄之四: SSTable檔案這篇文章對LevelDb的SSTable格式進行了介紹,因為LevelDB的作者JeffreyDean正是BigTable的設計師,所以極具參考價值。每一個片(tablet)在GFS裡都是按照SSTable的格式儲存的,每個片可能對應多個SSTable。
Chubby是一種高可用的分散式鎖服務,Chubby有五個活躍副本,同時只有一個主副本提供服務,副本之間用Paxos演算法維持一致性,Chubby提供了一個名稱空間(包括一些目錄和檔案),每個目錄和檔案就是一個鎖,Chubby的客戶端必須和Chubby保持會話,客戶端的會話若過期則會丟失所有的鎖。關於Chubby的詳細資訊可以看google的另一篇論文:The Chubby lock service for loosely-coupled distributed systems。Chubby用於片定位,片伺服器的狀態監控,訪問控制列表儲存等任務。
4 Bigtable叢集
Bigtable叢集包括三個主要部分:一個供客戶端使用的庫,一個主伺服器(master server),許多片伺服器(tablet server)。
正如資料模型小節所說,Bigtable會將表(table)進行分片,片(tablet)的大小維持在100-200MB範圍,一旦超出範圍就將分裂成更小的片,或者合併成更大的片。每個片伺服器負責一定量的片,處理對其片的讀寫請求,以及片的分裂或合併。片伺服器可以根據負載隨時新增和刪除。這裡片伺服器並不真實儲存資料,而相當於一個連線Bigtable和GFS的代理,客戶端的一些資料操作都通過片伺服器代理間接訪問GFS。
主伺服器負責將片分配給片伺服器,監控片伺服器的新增和刪除,平衡片伺服器的負載,處理表和列族的建立等。注意,主伺服器不儲存任何片,不提供任何資料服務,也不提供片的定位資訊。
客戶端需要讀寫資料時,直接與片伺服器聯絡。因為客戶端並不需要從主伺服器獲取片的位置資訊,所以大多數客戶端從來不需要訪問主伺服器,主伺服器的負載一般很輕。
5 片的定位
前面提到主伺服器不提供片的位置資訊,那麼客戶端是如何訪問片的呢?來看看論文給的示意圖,Bigtable使用一個類似B+樹的資料結構儲存片的位置資訊。
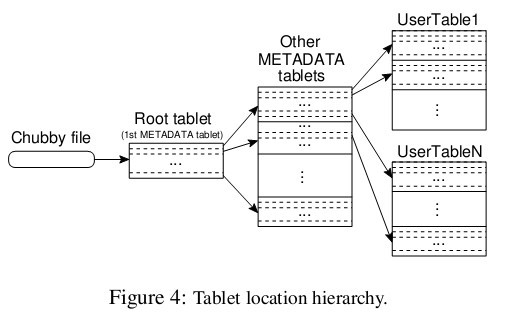
首先是第一層,Chubby file。這一層是一個Chubby檔案,它儲存著root tablet的位置。這個Chubby檔案屬於Chubby服務的一部分,一旦Chubby不可用,就意味著丟失了root tablet的位置,整個Bigtable也就不可用了。
第二層是root tablet。root tablet其實是元資料表(METADATA table)的第一個分片,它儲存著元資料表其它片的位置。root tablet很特別,為了保證樹的深度不變,root tablet從不分裂。
第三層是其它的元資料片,它們和root tablet一起組成完整的元資料表。每個元資料片都包含了許多使用者片的位置資訊。
可以看出整個定位系統其實只是兩部分,一個Chubby檔案,一個元資料表。注意元資料表雖然特殊,但也仍然服從前文的資料模型,每個分片也都是由專門的片伺服器負責,這就是不需要主伺服器提供位置資訊的原因。客戶端會快取片的位置資訊,如果在快取裡找不到一個片的位置資訊,就需要查詢這個三層結構了,包括訪問一次Chubby服務,訪問兩次片伺服器。