
scrapy研究探索(二)——爬w3school.com.cn
下午被一個問題困擾了好一陣,最終使用另一種方式解決。
在開始之前假設你已經成功安裝一切所需,整懷著一腔熱血想要抓取某網站。一起來have a try。
1. 前期基礎準備。
Oh,不能在準備了,直接來。
(1) 建立專案。
輸入:
scapy startproject w3school以上建立專案w3school。這時會產生w3school資料夾,資料夾下檔案如下:
scrapy.cfg w3school/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py
其中scrapy.cfg目的配置檔案。主要改寫的是w3school中的三個檔案以及其中spiders中需要編寫的爬蟲。
一個一個來。
(2) 在items.py中定義Item容器。也就是編寫items.py內容。
所謂Item容器就是將在網頁中獲取的資料結構化儲存的資料結構,類似於python中字典。下面為items.py中程式碼。
#project: w3school #file : items.py #author : younghz #brief : define W3schoolItem. from scrapy.item import Item,Field class W3schoolItem(Item): title = Field() link = Field() desc = Field()
上面定義了自己的W3schoolItem類,它繼承自scrapy的Item(這裡沒有顯示定義W3schoolItem的__init__()方法,也正因為如此,python也會為你自動呼叫基類的__init__(),否則必須顯式在子類的__init__()中呼叫基類__init__())。
之後宣告W3schoolItem中元素並使用Field定義。到此items.py就OK了。
(3) 在pipelines.py中編寫W3schoolPipeline實現對item的處理。
在其中主要完成資料的查重、丟棄,驗證item中資料,將得到的item資料儲存等工作。程式碼如下:
import json import codecs class W3SchoolPipeline(object): def __init__(self): self.file = codecs.open('w3school_data_utf8.json', 'wb', encoding='utf-8') def process_item(self, item, spider): line = json.dumps(dict(item)) + '\n' # print line self.file.write(line.decode("unicode_escape")) return item
其中的process_item方法是必須呼叫的用來處理item,並且返回值必須為Item類的物件,或者是丟擲DropItem異常。並且上述方法將得到的item實現解碼,以便正常顯示中文,最終儲存到json檔案中。
注意:在編寫完pipeline後,為了能夠啟動它,必須將其加入到ITEM_PIPLINES配置中,即在settings.py中加入下面一句:
ITEM_PIPELINES = {
'w3school.pipelines.W3SchoolPipeline':300
}2.編寫爬蟲。
爬蟲編寫是在spider/資料夾下編寫w3cshool_spider.py。
先上整個程式在慢慢解釋:
#!/usr/bin/python
# -*- coding:utf-8 -*-
from scrapy.spider import Spider
from scrapy.selector import Selector
from scrapy import log
from w3school.items import W3schoolItem
class W3schoolSpider(Spider):
"""爬取w3school標籤"""
#log.start("log",loglevel='INFO')
name = "w3school"
allowed_domains = ["w3school.com.cn"]
start_urls = [
"http://www.w3school.com.cn/xml/xml_syntax.asp"
]
def parse(self, response):
sel = Selector(response)
sites = sel.xpath('//div[@id="navsecond"]/div[@id="course"]/ul[1]/li')
items = []
for site in sites:
item = W3schoolItem()
title = site.xpath('a/text()').extract()
link = site.xpath('a/@href').extract()
desc = site.xpath('a/@title').extract()
item['title'] = [t.encode('utf-8') for t in title]
item['link'] = [l.encode('utf-8') for l in link]
item['desc'] = [d.encode('utf-8') for d in desc]
items.append(item)
#記錄
log.msg("Appending item...",level='INFO')
log.msg("Append done.",level='INFO')
return items
(1)需要注意的是編寫的spider必須繼承自scrapy的Spider類。
屬性name即spider唯一名字,start_url可以理解為爬取入口。
(2)parse方法。
parse()是對scrapy.Spider類的override。
(3)網頁中的資料提取機制。
scrapy使用選擇器Selector並通過XPath實現資料的提取。關於XPath 推薦w3school的教程。
小工具:
關於網頁程式碼中意向資訊的查詢可以藉助幾個工具:
第一個——Firefox外掛Firebug。
第二個——Firefox外掛XPath。可以快速的在網頁中對xpath表示式的正確性進行驗證。
第三個——scrapy shell.關於其使用可以檢視教程。
分析:
在這裡我提取的是http://www.w3school.com.cn/xml/xml_syntax.asp網頁中下圖部分。

即“XML 基礎”下所有目錄結構的名字、連結和描述。使用Firebug找到次部分對應的程式碼塊後就可以使用XPath執行資訊提取。Xpath表示式如上面程式碼中所示。
上面還涉及到了對item中資訊的編碼,是為了中文資訊在json檔案中的正確顯示。
(4)在parse方法中還使用到了log功能實現資訊記錄。使用log.mes()函式即可。
3.執行。
一切就緒。進入到專案目錄下,執行:
scrapy crawl w3school --set LOG_FILE=log在目錄下生成log和w3school_data_utf8.json檔案。
檢視生成的json檔案:
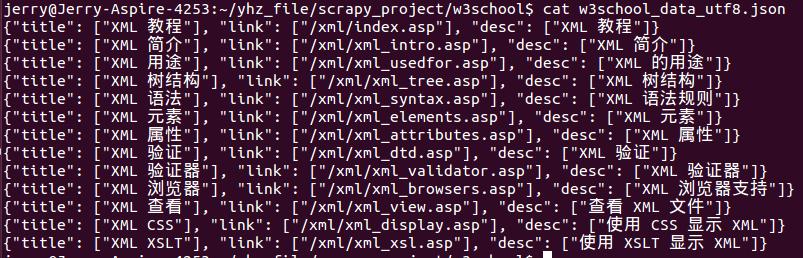
關於scrapy的其它文章: