
python讀取各種檔案資料解析
阿新 • • 發佈:2019-02-12
python讀取.txt(.log)檔案 、.xml 檔案 、excel檔案資料,並將資料型別轉換為需要的型別,新增到list中詳解
1.讀取文字檔案資料(.txt結尾的檔案)或日誌檔案(.log結尾的檔案)
以下是檔案中的內容,檔名為data.txt(與data.log內容相同),且處理方式相同,呼叫時改個名稱就可以了:
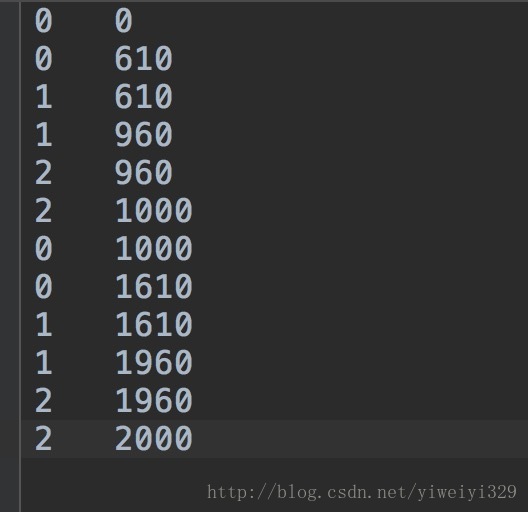
以下是python實現程式碼:
# -*- coding:gb2312 -*-
import json
def read_txt_high(filename):
with open(filename, 'r') as file_to_read:
list0 = [] #檔案中的第一列資料 list0與list1分別為文件中的第一列資料與第二列資料。執行若是文字檔案(.txt結尾的檔案)輸入以下:
aa,bb = read_txt_high('data.txt')
print aa
print bb若是日誌檔案(.log結尾的檔案),輸入以下:
aa,bb = read_txt_high('data.log')
print aa
print bb執行結果如下:

2.讀取.xml結尾的檔案
XML檔案的名稱為abc.xml, 內容如下圖所示:
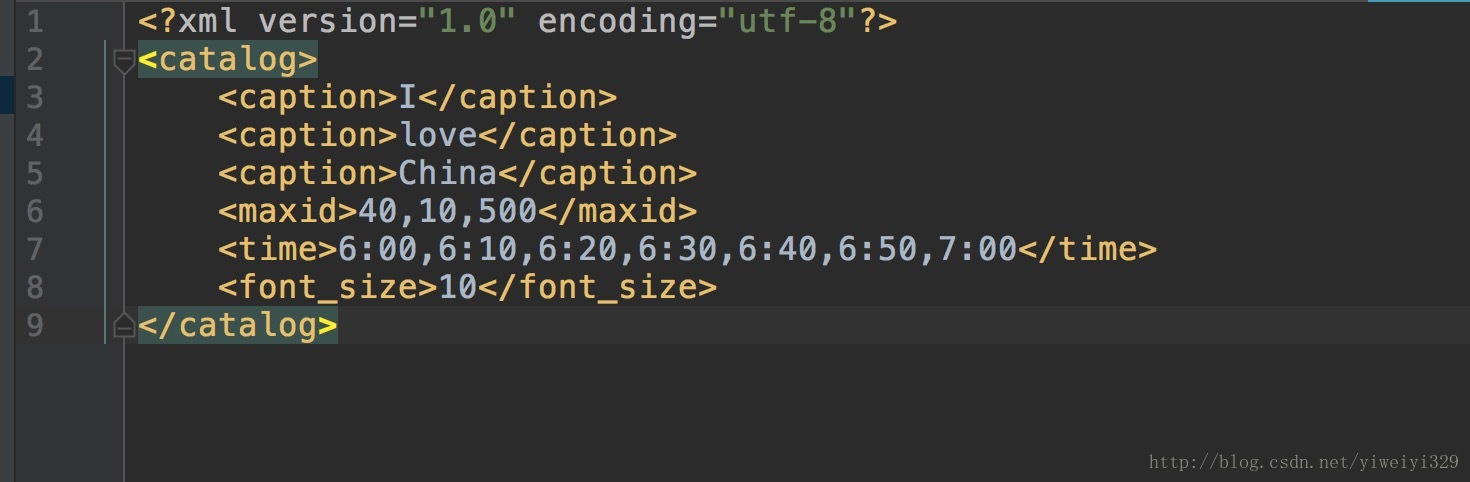
以下是實現程式碼:
# -*- coding:gb2312 -*-
# coding = utf-8 呼叫此函式如下所示:
a,b,c,d = read_xml()
print a
print b
print c
print d輸出結果如下圖所示:

3.讀取excel檔案資料,並將其存入list列表中
excel表格中的資料如下圖所示,表格命名為data.xlsx:
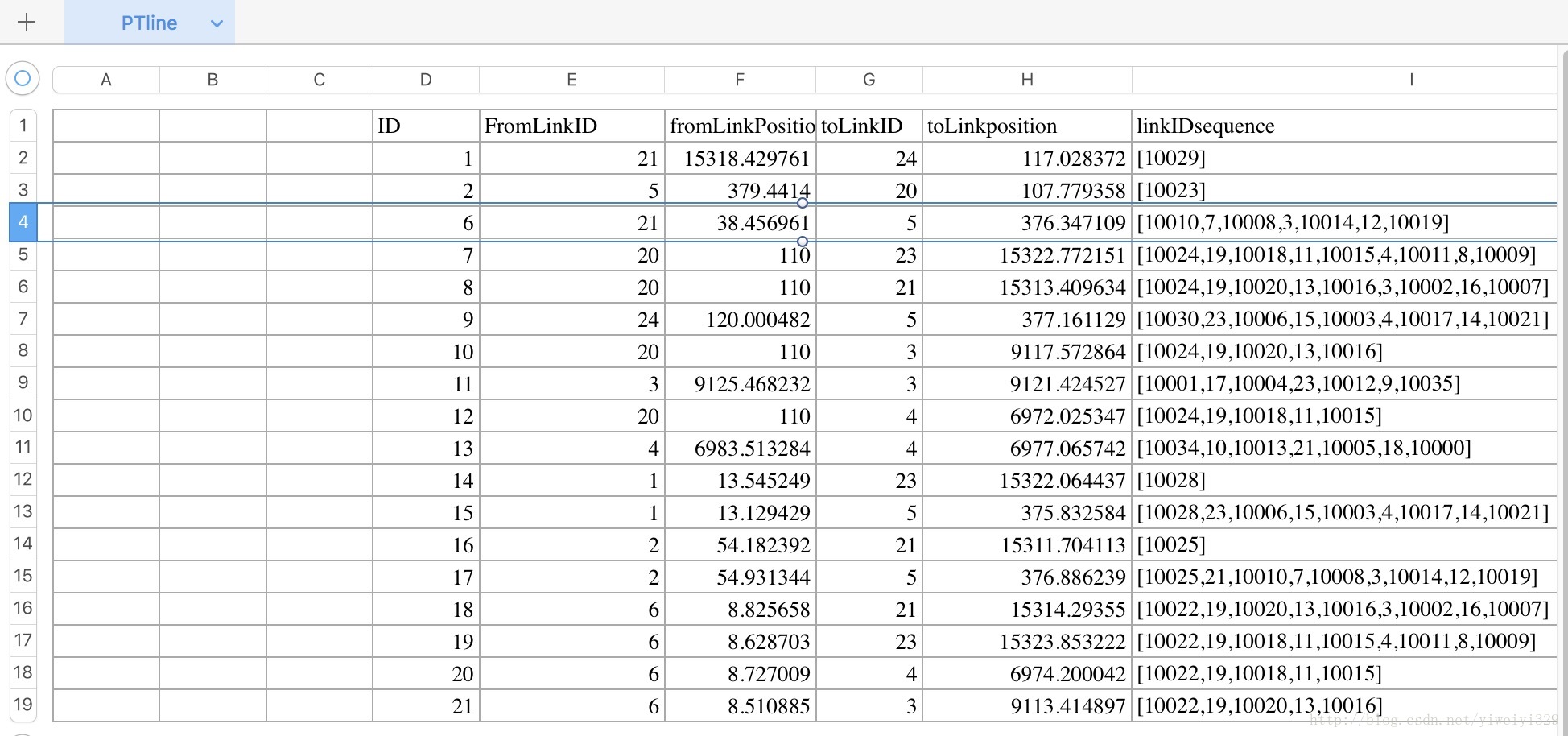
首先將ID列中的資料儲存到列表list_col中,實現程式碼如下所示:
# -*- coding: utf-8 -*-
import xlrd
import json
def read_ex_stop_PTline():
# 開啟檔案
workbook = xlrd.open_workbook(r'data.xlsx')
sheet = workbook.sheet_by_name('PTline')
list_col = []
for i in range(1,sheet.nrows):
c = sheet.cell(i,3).value
list_col.append(int(c))
print list_col
呼叫此函式,輸出結果如下:

以下將linkIDsequence列資料存放到一個list中,即list_ele中,實現程式碼如下:
# -*- coding: utf-8 -*-
import xlrd
import json
def read_ex_stop_PTline():
# 開啟檔案
workbook = xlrd.open_workbook(r'data.xlsx')
sheet = workbook.sheet_by_name('PTline')
list_ele = [] #第八列的所有資料放入一個list中
for i in range(1,sheet.nrows):
c = sheet.cell(i, 8).value
cc = json.loads(c) #第八列的每個單元格處理為一個list
for j in range(len(cc)):
list_ele.append(cc[j])
print list_ele呼叫函式read_ex_stop_PTline,輸出結果如下圖所示:
