
常用卷積神經網路從基本原理到結構彙總
先明確一點就是,Deep Learning是全部深度學習演算法的總稱,CNN是深度學習演算法在影象處理領域的一個應用。
第一點,在學習Deep learning和CNN之前,總以為它們是很了不得的知識,總以為它們能解決很多問題,學習了之後,才知道它們不過與其他機器學習演算法如svm等相似,仍然可以把它當做一個分類器,仍然可以像使用一個黑盒子那樣使用它。
第二點,Deep Learning強大的地方就是可以利用網路中間某一層的輸出當做是資料的另一種表達,從而可以將其認為是經過網路學習到的特徵。基於該特徵,可以進行進一步的相似度比較等。
第三點,Deep Learning演算法能夠有效的關鍵其實是大規模的資料,這一點原因在於每個DL都有眾多的引數,少量資料無法將引數訓練充分。
接下來話不多說,直接奔入主題開始CNN之旅。

卷積神經網路簡介(Convolutional Neural Networks,簡稱CNN)
卷積神經網路是近年發展起來,並引起廣泛重視的一種高效識別方法。20世紀60年代,Hubel和Wiesel在研究貓腦皮層中用於區域性敏感和方向選擇的神經元時發現其獨特的網路結構可以有效地降低反饋神經網路的複雜性,繼而提出了卷積神經網路(Convolutional Neural Networks-簡稱CNN)。現在,CNN已經成為眾多科學領域的研究熱點之一,特別是在模式分類領域,由於該網路避免了對影象的複雜前期預處理,可以直接輸入原始影象,因而得到了更為廣泛的應用。 K.Fukushima在1980年提出的新識別機是卷積神經網路的第一個實現網路。隨後,更多的科研工作者對該網路進行了改進。其中,具有代表性的研究成果是Alexander和Taylor提出的“改進認知機”,該方法綜合了各種改進方法的優點並避免了耗時的誤差反向傳播。
一般地,CNN的基本結構包括兩層,其一為特徵提取層,每個神經元的輸入與前一層的區域性接受域相連,並提取該區域性的特徵。一旦該區域性特徵被提取後,它與其它特徵間的位置關係也隨之確定下來;其二是特徵對映層,網路的每個計算層由多個特徵對映組成,每個特徵對映是一個平面,平面上所有神經元的權值相等。特徵對映結構採用影響函式核小的sigmoid函式作為卷積網路的啟用函式,使得特徵對映具有位移不變性。此外,由於一個對映面上的神經元共享權值,因而減少了網路自由引數的個數。卷積神經網路中的每一個卷積層都緊跟著一個用來求區域性平均與二次提取的計算層,這種特有的兩次特徵提取結構減小了特徵解析度。
CNN主要用來識別位移、縮放及其他形式扭曲不變性的二維圖形。由於CNN的特徵檢測層通過訓練資料進行學習,所以在使用CNN時,避免了顯示的特徵抽取,而隱式地從訓練資料中進行學習;再者由於同一特徵對映面上的神經元權值相同,所以網路可以並行學習,這也是卷積網路相對於神經元彼此相連網路的一大優勢。卷積神經網路以其區域性權值共享的特殊結構在語音識別和影象處理方面有著獨特的優越性,其佈局更接近於實際的生物神經網路,權值共享降低了網路的複雜性,特別是多維輸入向量的影象可以直接輸入網路這一特點避免了特徵提取和分類過程中資料重建的複雜度。
1. 神經網路
首先介紹神經網路,這一步的詳細可以參考資源1。簡要介紹下。神經網路的每個單元如下:

其對應的公式如下:
![]()
其中,該單元也可以被稱作是Logistic迴歸模型。當將多個單元組合起來並具有分層結構時,就形成了神經網路模型。下圖展示了一個具有一個隱含層的神經網路。

其對應的公式如下:

比較類似的,可以拓展到有2,3,4,5,…個隱含層。
神經網路的訓練方法也同Logistic類似,不過由於其多層性,還需要利用鏈式求導法則對隱含層的節點進行求導,即梯度下降+鏈式求導法則,專業名稱為反向傳播。關於訓練演算法,本文暫不涉及。
2 卷積神經網路
在影象處理中,往往把影象表示為畫素的向量,比如一個1000×1000的影象,可以表示為一個1000000的向量。在上一節中提到的神經網路中,如果隱含層數目與輸入層一樣,即也是1000000時,那麼輸入層到隱含層的引數資料為1000000×1000000=10^12,這樣就太多了,基本沒法訓練。所以影象處理要想練成神經網路大法,必先減少引數加快速度。就跟辟邪劍譜似的,普通人練得很挫,一旦自宮後內力變強劍法變快,就變的很牛了。
2.1 區域性感知
卷積神經網路有兩種神器可以降低引數數目,第一種神器叫做區域性感知野。一般認為人對外界的認知是從區域性到全域性的,而影象的空間聯絡也是區域性的畫素聯絡較為緊密,而距離較遠的畫素相關性則較弱。因而,每個神經元其實沒有必要對全域性影象進行感知,只需要對區域性進行感知,然後在更高層將區域性的資訊綜合起來就得到了全域性的資訊。網路部分連通的思想,也是受啟發於生物學裡面的視覺系統結構。視覺皮層的神經元就是區域性接受資訊的(即這些神經元只響應某些特定區域的刺激)。如下圖所示:左圖為全連線,右圖為區域性連線。

在上右圖中,假如每個神經元只和10×10個畫素值相連,那麼權值資料為1000000×100個引數,減少為原來的千分之一。而那10×10個畫素值對應的10×10個引數,其實就相當於卷積操作。
2.2 引數共享
但其實這樣的話引數仍然過多,那麼就啟動第二級神器,即權值共享。在上面的區域性連線中,每個神經元都對應100個引數,一共1000000個神經元,如果這1000000個神經元的100個引數都是相等的,那麼引數數目就變為100了。
怎麼理解權值共享呢?我們可以這100個引數(也就是卷積操作)看成是提取特徵的方式,該方式與位置無關。這其中隱含的原理則是:影象的一部分的統計特性與其他部分是一樣的。這也意味著我們在這一部分學習的特徵也能用在另一部分上,所以對於這個影象上的所有位置,我們都能使用同樣的學習特徵。
更直觀一些,當從一個大尺寸影象中隨機選取一小塊,比如說 8×8 作為樣本,並且從這個小塊樣本中學習到了一些特徵,這時我們可以把從這個 8×8 樣本中學習到的特徵作為探測器,應用到這個影象的任意地方中去。特別是,我們可以用從 8×8 樣本中所學習到的特徵跟原本的大尺寸影象作卷積,從而對這個大尺寸影象上的任一位置獲得一個不同特徵的啟用值。
如下圖所示,展示了一個33的卷積核在55的影象上做卷積的過程。每個卷積都是一種特徵提取方式,就像一個篩子,將影象中符合條件(啟用值越大越符合條件)的部分篩選出來。

2.3 多卷積核
上面所述只有100個引數時,表明只有1個100*100的卷積核,顯然,特徵提取是不充分的,我們可以新增多個卷積核,比如32個卷積核,可以學習32種特徵。在有多個卷積核時,如下圖所示:

上圖右,不同顏色表明不同的卷積核。每個卷積核都會將影象生成為另一幅影象。比如兩個卷積核就可以將生成兩幅影象,這兩幅影象可以看做是一張影象的不同的通道。如下圖所示,下圖有個小錯誤,即將w1改為w0,w2改為w1即可。下文中仍以w1和w2稱呼它們。
下圖展示了在四個通道上的卷積操作,有兩個卷積核,生成兩個通道。其中需要注意的是,四個通道上每個通道對應一個卷積核,先將w2忽略,只看w1,那麼在w1的某位置(i,j)處的值,是由四個通道上(i,j)處的卷積結果相加然後再取啟用函式值得到的。


所以,在上圖由4個通道卷積得到2個通道的過程中,引數的數目為4×2×2×2個,其中4表示4個通道,第一個2表示生成2個通道,最後的2×2表示卷積核大小。
2.4 Down-pooling
在通過卷積獲得了特徵 (features) 之後,下一步我們希望利用這些特徵去做分類。理論上講,人們可以用所有提取得到的特徵去訓練分類器,例如 softmax 分類器,但這樣做面臨計算量的挑戰。例如:對於一個 96X96 畫素的影象,假設我們已經學習得到了400個定義在8X8輸入上的特徵,每一個特徵和影象卷積都會得到一個 (96 − 8 + 1) × (96 − 8 + 1) = 7921 維的卷積特徵,由於有 400 個特徵,所以每個樣例 (example) 都會得到一個 892 × 400 = 3,168,400 維的卷積特徵向量。學習一個擁有超過 3 百萬特徵輸入的分類器十分不便,並且容易出現過擬合 (over-fitting)。
為了解決這個問題,首先回憶一下,我們之所以決定使用卷積後的特徵是因為影象具有一種“靜態性”的屬性,這也就意味著在一個影象區域有用的特徵極有可能在另一個區域同樣適用。因此,為了描述大的影象,一個很自然的想法就是對不同位置的特徵進行聚合統計,例如,人們可以計算影象一個區域上的某個特定特徵的平均值 (或最大值)。這些概要統計特徵不僅具有低得多的維度 (相比使用所有提取得到的特徵),同時還會改善結果(不容易過擬合)。這種聚合的操作就叫做池化 (pooling),有時也稱為平均池化或者最大池化 (取決於計算池化的方法)。

至此,卷積神經網路的基本結構和原理已經闡述完畢,下面對常見的卷積神經網路結構進行剖析。
CNN的經典結構始於1998年的LeNet,成於2012年曆史性的AlexNet,從此大盛於影象相關領域,主要包括:
1、LeNet,1998年
2、AlexNet,2012年
3、ZF-net,2013年
4、GoogleNet,2014年
5、VGG,2014年
6、ResNet,2015年
LeNet前面博文已介紹,下面再補充介紹下其它幾種網路結構。
AlexNet

需要注意的是,該模型採用了2-GPU並行結構,即第1、2、4、5卷積層都是將模型引數分為2部分進行訓練的。在這裡,更進一步,並行結構分為資料並行與模型並行。資料並行是指在不同的GPU上,模型結構相同,但將訓練資料進行切分,分別訓練得到不同的模型,然後再將模型進行融合。而模型並行則是,將若干層的模型引數進行切分,不同的GPU上使用相同的資料進行訓練,得到的結果直接連線作為下一層的輸入。
上圖模型的基本引數為:
輸入:224×224大小的圖片,3通道
第一層卷積:5×5大小的卷積核96個,每個GPU上48個。
第一層max-pooling:2×2的核。
第二層卷積:3×3卷積核256個,每個GPU上128個。
第二層max-pooling:2×2的核。
第三層卷積:與上一層是全連線,3*3的卷積核384個。分到兩個GPU上個192個。
第四層卷積:3×3的卷積核384個,兩個GPU各192個。該層與上一層連線沒有經過pooling層。
第五層卷積:3×3的卷積核256個,兩個GPU上個128個。
第五層max-pooling:2×2的核。
第一層全連線:4096維,將第五層max-pooling的輸出連線成為一個一維向量,作為該層的輸入。
第二層全連線:4096維
Softmax層:輸出為1000,輸出的每一維都是圖片屬於該類別的概率。
ZF-Net

【說明】:我想很多人在看faster-rcnn的時候,都會被RPN的網路結構和連線方式糾結,作者在文中說的不是很清晰,這裡給出解析;
【首先】:大家應該要了解卷積神經網路的連線方式,卷積核的維度,反向傳播時是如何靈活的插入一層;這裡我推薦一份資料,真是寫的非常清晰,就是MatConvet的使用者手冊,這個框架底層借用的是caffe的演算法,所以他們的資料結構,網路層的連線方式都是一樣的;建議讀者看看,很快的;
【前面5層】:作者RPN網路前面的5層借用的是ZF網路,這個網路的結構圖我截個圖放在下面,並分析下為什麼是這樣子的,雙向箭頭上的粗體數字是左上側矩形框影象的Channel size,比如3是輸入影象的通道;
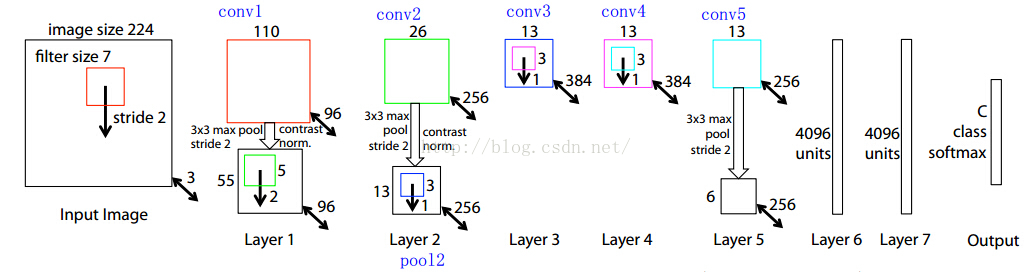
首先記住一個公式:卷積後的conv大小=(卷積前conv層寬度-map寬度+填充)/步長+1
1、輸入圖片大小是 224*224*3(這個3是三個通道,也就是RGB三種);
2、然後第一層的卷積核維度是 7*7*3*96 (所以大家要認識到卷積核都是4維的,在caffe的矩陣計算中都是這麼實現的);
3、所以conv1得到的結果是110*110*96 (這個110來自於 (224-7+pad)/2 +1 ,這個pad是我們常說的填充,也就是在圖片的周圍補充畫素,這樣做的目的是為了能夠整除,除以2是因為2是圖中的stride, 這個計算方法在上面建議的文件中有說明與推導的);
4、然後就是做一次池化,得到pool1, 池化的核的大小是3*3,所以池化後圖片的維度是55*55*96 ( (110-3+pad)/2 +1 =55 );
5、然後接著就是再一次卷積,這次的卷積核的維度是5*5*96*256 ,得到conv2:26*26*256;
6、後面就是類似的過程了,我就不詳細一步步算了,要注意有些地方除法除不盡,作者是做了填充了,在caffe的prototxt檔案中,可以看到每一層的pad的大小;
7、最後作者取的是conv5的輸出,也就是13*13*256送給RPN網路的;
【RPN部分】:然後,我們看看RPN部分的結構:

1、前面我們指出,這個conv feature map的維度是13*13*256的;
2、作者在文章中指出,sliding window的大小是3*3的,那麼如何得到這個256-d的向量呢? 這個很簡單了,我們只需要一個3*3*256*256這樣的一個4維的卷積核,就可以將每一個3*3的sliding window 卷積成一個256維的向量;
這裡讀者要注意啊,作者這裡畫的示意圖 僅僅是 針對一個sliding window的;在實際實現中,我們有很多個sliding window,所以得到的並不是一維的256-d向量,實際上還是一個3維的矩陣資料結構;可能寫成for迴圈做sliding window大家會比較清楚,當用矩陣運算的時候,會稍微繞些;
3、然後就是k=9,所以cls layer就是18個輸出節點了,那麼在256-d和cls layer之間使用一個1*1*256*18的卷積核,就可以得到cls layer,當然這個1*1*256*18的卷積核就是大家平常理解的全連線;所以全連線只是卷積操作的一種特殊情況(當卷積核的大小與圖片大小相同的時候,其實所謂的卷積就是全連線了);
4、reg layer也是一樣了,reg layer的輸出是36個,所以對應的卷積核是1*1*256*36,這樣就可以得到reg layer的輸出了;
5、然後cls layer 和reg layer後面都會接到自己的損失函式上,給出損失函式的值,同時會根據求導的結果,給出反向傳播的資料,這個過程讀者還是參考上面給的文件,寫的挺清楚的;
【作者關於RPN網路的具體定義】:這個作者是放在./models/pascal_voc/ZF/faster_rcnn_alt_opt/stage1_rpn_train.pt 檔案中的;
我把這個檔案拿出來給註釋下:
- name: "ZF"
- layer {
- name: 'input-data' #這一層就是最開始資料輸入
- type: 'Python'
- top: 'data' # top表示該層的輸出,所以可以看到這一層輸出三組資料,data,真值框gt_boxes,和相關資訊im_info
- top: 'im_info' # 這些都是儲存在矩陣中的
- top: 'gt_boxes'
- python_param {
- module: 'roi_data_layer.layer'
- layer: 'RoIDataLayer'
- param_str: "'num_classes': 21"
- }
- }
- #========= conv1-conv5 ============
- layer {
- name: "conv1"
- type: "Convolution"
- bottom: "data" # 輸入data
- top: "conv1" # 輸出conv1,這裡conv1就代表了這一層輸出資料的名稱,儲存在對應的矩陣中
- param { lr_mult: 1.0 }
- param { lr_mult: 2.0 }
- convolution_param {
- num_output: 96
- kernel_size: 7
- pad: 3 # 這裡可以看到卷積1層 填充了3個畫素
- stride: 2
- }
- }
- layer {
- name: "relu1"
- type: "ReLU"
- bottom: "conv1"
- top: "conv1"
- }
- layer {
- name: "norm1"
- type: "LRN"
- bottom: "conv1"
- top: "norm1" # 做歸一化操作,通俗點說就是做個除法
- lrn_param {
- local_size: 3
- alpha: 0.00005
- beta: 0.75
- norm_region: WITHIN_CHANNEL
- engine: CAFFE
- }
- }
- layer {
- name: "pool1"
- type: "Pooling"
- bottom: "norm1"
- top: "pool1"
- pooling_param {
- kernel_size: 3
- stride: 2
- pad: 1 # 池化的時候,又做了填充
- pool: MAX
- }
- }
- layer {
- name: "conv2"
- type: "Convolution"
- bottom: "pool1"
- top: "conv2"
- param { lr_mult: 1.0 }
- param { lr_mult: 2.0 }
- convolution_param {
- num_output: 256
- kernel_size: 5
- pad: 2
- stride: 2
- }
- }
- layer {
- name: "relu2"
- type: "ReLU"
- bottom: "conv2"
- top: "conv2"
- }
- layer {
- name: "norm2"
- type: "LRN"
- bottom: "conv2"
- top: "norm2"
- lrn_param {
- local_size: 3
- alpha: 0.00005
- beta: 0.75
- norm_region: WITHIN_CHANNEL
- engine: CAFFE
- }
- }
- layer {
- name: "pool2"
- type: "Pooling"
- bottom: "norm2"
- top: "pool2"
- pooling_param {
- kernel_size: 3
- stride: 2
- pad: 1
- pool: MAX
- }
- }
- layer {
- name: "conv3"
- type: "Convolution"
- bottom: "pool2"
- top: "conv3"
- param { lr_mult: 1.0 }
- param { lr_mult: 2.0 }
- convolution_param {
- num_output: 384
- kernel_size: 3
- pad: 1
- stride: 1
- }
- }
- layer {
- name: "relu3"
- type: "ReLU"
- bottom: "conv3"
- top: "conv3"
- }
- layer {
- name: "conv4"
- type: "Convolution"
- bottom: "conv3"
- top: "conv4"
- param { lr_mult: 1.0 }
- param { lr_mult: 2.0 }
- convolution_param {
- num_output: 384
- kernel_size: 3
- pad: 1
- stride: 1
- }
- }
- layer {
- name: "relu4"
- type: "ReLU"
- bottom: "conv4"
- top: "conv4"
- }
- layer {
- name: "conv5"
- type: "Convolution"
- bottom: "conv4"
- top: "conv5"
- param { lr_mult: 1.0 }
- param { lr_mult: 2.0 }
- convolution_param {
- num_output: 256
- kernel_size: 3
- pad: 1
- stride: 1
- }
- }
- layer {
- name: "relu5"
- type: "ReLU"
- bottom: "conv5"
- top: "conv5"
- }
- #========= RPN ============
- # 到我們的RPN網路部分了,前面的都是共享的5層卷積層的部分
- layer {
- name: "rpn_conv1"
- type: "Convolution"
- bottom: "conv5"
- top: "rpn_conv1"
- param { lr_mult: 1.0 }
- param { lr_mult: 2.0 }
- convolution_param {
- num_output: 256
- kernel_size: 3 pad: 1 stride: 1 #這裡作者把每個滑窗3*3,通過3*3*256*256的卷積核輸出256維,完整的輸出其實是12*12*256,
- weight_filler { type: "gaussian" std: 0.01 }
- bias_filler { type: "constant" value: 0 }
- }
- }
- layer {
- name: "rpn_relu1"
- type: "ReLU"
- bottom: "rpn_conv1"
- top: "rpn_conv1"
- }
- layer {
- name: "rpn_cls_score"
- type: "Convolution"
- bottom: "rpn_conv1"
- top: "rpn_cls_score"
- param { lr_mult: 1.0 }
- param { lr_mult: 2.0 }
- convolution_param {
- num_output: 18 # 2(bg/fg) * 9(anchors)
- kernel_size: 1 pad: 0 stride: 1 #這裡看的很清楚,作者通過1*1*256*18的卷積核,將前面的256維資料轉換成了18個輸出
- weight_filler { type: "gaussian" std: 0.01 }
- bias_filler { type: "constant" value: 0 }
- }
- }
- layer {
- name: "rpn_bbox_pred"
- type: "Convolution"
- bottom: "rpn_conv1"
- top: "rpn_bbox_pred"
- param { lr_mult: 1.0 }
- param { lr_mult: 2.0 }
- convolution_param {
- num_output: 36 # 4 * 9(anchors)
- kernel_size: 1 pad: 0 stride: 1 <span style="font-family: Arial, Helvetica, sans-serif;">#這裡看的很清楚,作者通過1*1*256*36的卷積核,將前面的256維資料轉換成了36個輸出</span>
- weight_filler { type: "gaussian" std: 0.01 }
- bias_filler {