robots.txt 禁止收錄協議的寫法
robots.txt 是網站和搜尋引擎的協議的純文字檔案。當一個搜尋引擎蜘蛛來訪問站點時,它首先爬行來檢查該站點根目錄下是否存在robots.txt,
如果存在,根據檔案內容來確定訪問範圍,如果沒有,蜘蛛就沿著連結抓取。robots.txt 放在專案的根目錄下。
2. robots.txt語法
1) 允許所有搜尋引擎訪問網站的所有部分
robots.txt寫法如下:
User-agent: *
Disallow:
或者
User-agent: *
Allow: /
注意: 1.
第一個英文要大寫,冒號是英文狀態下,冒號後面有一個空格,這幾點一定不能寫錯。
2) 禁止所有搜尋引擎訪問網站的所有部分
robots.txt寫法如下:
User-agent: *
Disallow: /
3) 只需要禁止蜘蛛訪問某個目錄,比如禁止admin、css、images等目錄被索引
robots.txt寫法如下:
User-agent: *
Disallow: /css/
Disallow: /admin/
Disallow: /images/
注意:路徑後面有斜槓和沒有斜槓的區別:比如Disallow: /images/ 有斜槓是禁止抓取images整個資料夾,Disallow: /images 沒有斜槓意思是凡是路徑裡面有/images關鍵詞的都會被遮蔽
4)遮蔽一個資料夾/templets,但是又能抓取其中一個檔案的寫法:/templets/mainrobots.txt寫法如下:
User-agent: *
Disallow: /templets
Allow: /main
5) 禁止訪問/html/目錄下的所有以”.php”為字尾的URL(包含子目錄)
robots.txt寫法如下:
User-agent: *
Disallow: /html/*.php
6) 僅允許訪問某目錄下某個字尾的檔案,則使用“$”
robots.txt寫法如下:
User-agent: *
Allow: .html$
Disallow: /
比如這裡限制的是有“?”的域名,例如index.php?id=1
robots.txt寫法如下:
User-agent: *
Disallow: /*?*
8) 禁止搜尋引擎抓取我們網站上的所有圖片(如果你的網站使用其他字尾的圖片名稱,在這裡也可以直接新增)
有些時候,我們為了節省伺服器資源,需要禁止各類搜尋引擎來索引我們網站上的圖片,這裡的辦法除了使用“Disallow: /images/”這樣的直接遮蔽資料夾的方式之外,還 可以採取直接遮蔽圖片字尾名的方式。
robots.txt寫法如下:
User-agent: *
Disallow: .jpg$
Disallow: .jpeg$
Disallow: .gif$
Disallow: .png$
Disallow: .bmp$
寫robots.txt要注意的地方
1. 第一個英文要大寫,冒號是英文狀態下,冒號後面有一個空格,這幾點一定不能寫錯。
2. 斜槓:/ 代表整個網站
3.如果“/”後面多了一個空格,則遮蔽整個網站
4.不要禁止正常的內容
5.生效時間是幾天到兩個月
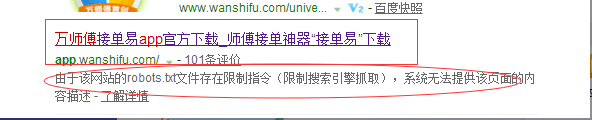
下面這種情況有灰色的一行字說明robots.txt是起了作用的。只是收錄了網站的位址列: