win 10 + maven + idea 15 + Hadoop 2.7.3開發環境配置
阿新 • • 發佈:2019-02-12
前言
今天想在win 10上搭一個Hadoop的開發環境,希望能夠直聯Hadoop叢集並提交MapReduce任務,這裡給出相關的關鍵配置。
步驟
關於maven以及idea的安裝這裡不再贅述,非常簡單。
- 在win 10上配置Hadoop
將Hadoop 2.7.3直接解壓到系統某個位置,以我的檔名稱為例,解壓到E:\大資料平臺\hadoop\hadoop-2.7.3中
配置HADOOP_HOME以及PATH
建立名為HADOOP_HOME的環境變數
將bin路徑新增到PATH中
新增Hadoop在win上需要的相關庫檔案,將其新增到hadoop的bin目錄中
建立maven專案,在pom檔案中新增相關的依賴

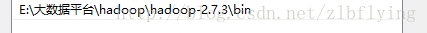

<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
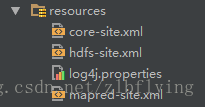
<groupId - 將Hadoop的相關配置檔案新增到resources資料夾下
- 編寫WordCount程式
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
/**
* Created by lianbin zhang on 2016/12/16.
*/
public class WordCount extends Configured implements Tool {
public int run(String[] strings) throws Exception {
try {
Configuration conf = getConf();
conf.set("mapreduce.job.jar", "src/main/wc.jar");
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.hostname", "10.20.10.100");
conf.set("mapreduce.app-submission.cross-platform", "true");
Job job = Job.getInstance(conf);
job.setJarByClass(WordCount.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, "hdfs://ns1/myid");
FileOutputFormat.setOutputPath(job, new Path("hdfs://ns1/out"));
job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
return 0;
}
public static class WcMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String mVal = value.toString();
context.write(new Text(mVal), new LongWritable(1));
}
}
public static class WcReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for(LongWritable lVal : values){
sum += lVal.get();
}
context.write(key, new LongWritable(sum));
}
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new WordCount(), args);
}
}
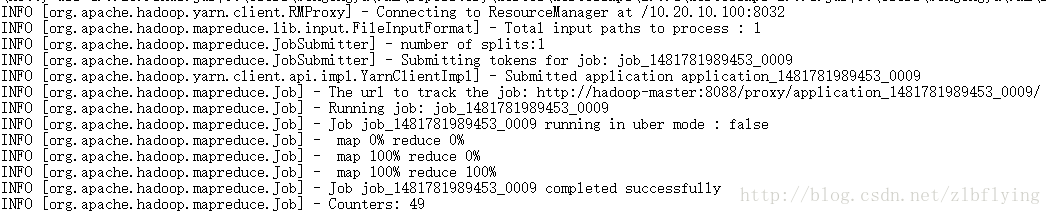
注意:在run方法中有四項配置:
- mapreduce.job.jar:應用程式打包後的jar位置;
- mapreduce.framework.name:使用的mapreduce框架
- yarn.resourcemanager.hostname:rm的主機名,可以在hosts檔案中配置對應的主機名
- mapreduce.app-submission.cross-platform:是否跨平臺提交mr程式
- 提交程式
提交程式進行執行時,由於跨平臺提交,預設會將當前win的登陸使用者作為user去操作hdfs叢集,這裡會存在許可權問題,大多數解決方案中都是對hdfs檔案的許可權進行修改。本文采用的方案是在提交時新增虛擬機器執行引數
-DHADOOP_USER_NAME=hadoop // hadoop需要換成你自己的使用者名稱- 執行結果