
spark rpc遠端呼叫基礎
讓程式碼分散式執行是所有分散式計算框架需要解決的最基本的問題。
Spark是大資料領域中相當火熱的計算框架,在大資料分析領域有一統江湖的趨勢,網上對於Spark原始碼分析的文章有很多,但是介紹Spark如何處理程式碼分散式執行問題的資料少之又少,這也是我撰寫文字的目的。
Spark執行在JVM之上,任務的執行依賴序列化及類載入機制,因此本文會重點圍繞這兩個主題介紹Spark對程式碼分散式執行的處理。本文假設讀者對Spark、Java、Scala有一定的瞭解,程式碼示例基於Scala,Spark原始碼基於2.1.0版本。閱讀本文你可以瞭解到:
- Java物件序列化機制
- 類載入器的作用
- Spark對closure序列化的處理
- Spark Application的class是如何載入的
- Spark REPL(spark-shell)中的程式碼是如何分散式執行的
根據以上內容,讀者可以基於JVM相關的語言構建一個自己的分散式計算服務框架。
Java物件序列化
序列化(Serialization)是將物件的狀態資訊轉換為可以儲存或傳輸的形式的過程。所謂的狀態資訊指的是物件在記憶體中的資料,Java中一般指物件的欄位資料。我們開發Java應用的時候或多或少都處理過物件序列化,物件常見的序列化形式有JSON、XML等。
JDK中內建一個ObjectOutputStream類可以將物件序列化為二進位制資料,使用ObjectOutputStream序列化物件時,要求物件所屬的類必須實現java.io.Serializable介面,否則會報java.io.NotSerializableException的異常。
基本的概念先介紹到這。接下來我們一起探討一個問題:Java的方法能否被序列化?
假設我們有如下的SimpleTask類(Java類):
import java.io.Serializable;
public abstract class Task implements Serializable {
public void run() {
System.out.println("run task!");
}
}
public class SimpleTask extends Task {
@Override
public void 還有一個用於將物件序列化到檔案的工具類FileSerializer:
import java.io.{FileInputStream, FileOutputStream, ObjectInputStream, ObjectOutputStream}
object FileSerializer {
def writeObjectToFile(obj: Object, file: String) = {
val fileStream = new FileOutputStream(file)
val oos = new ObjectOutputStream(fileStream)
oos.writeObject(obj)
oos.close()
}
def readObjectFromFile(file: String): Object = {
val fileStream = new FileInputStream(file)
val ois = new ObjectInputStream(fileStream)
val obj = ois.readObject()
ois.close()
obj
}
}
簡單起見,我們採用將物件序列化到檔案,然後通過反序列化執行的方式來模擬程式碼的分散式執行。SimpleTask就是我們需要模擬分散式執行的程式碼。我們先將SimpleTask序列化到檔案中:
val task = new SimpleTask()
FileSerializer.writeObjectToFile(task, "task.ser")
然後將SimpleTask類從我們的程式碼中刪除,此時只有task.ser檔案中含有task物件的序列化資料。接下來我們執行下面的程式碼:
val task = FileSerializer.readObjectFromFile("task.ser").asInstanceOf[Task]
task.run()
請各位讀者思考,上面的程式碼執行後會出現什麼樣的結果?
- 輸出:run simple task! ?
- 輸出:run task! ?
- 還是會報錯?
實際執行會出現形如下面的異常:
Exception in thread "main" java.lang.ClassNotFoundException: site.stanzhai.serialization.SimpleTask
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at java.io.ObjectInputStream.resolveClass(ObjectInputStream.java:628)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1620)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1521)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1781)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1353)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:373)
at site.stanzhai.serialization.FileSerializer$.readObjectFromFile(FileSerializer.scala:20)
從異常資訊來看,反序列過程中找不到SimpleTask類。由此可以推斷序列化後的資料是不包含類的定義資訊的。那麼,ObjectOutputStream到底序列化了哪些資訊呢?
對ObjectOutputStream實現機制感興趣的同學可以去看下JDK中這個類的實現,ObjectOutputStream序列化物件時,從父類的資料開始序列化到子類,如果override了writeObject方法,會反射呼叫writeObject來序列化資料。序列化的資料會按照以下的順序以二進位制的形式輸出到OutputStream中:
- 類的descriptor(僅僅是類的描述資訊,不包含類的定義)
- 物件的primitive型別資料(int,boolean等,String和Array是特殊處理的)
- 物件的其他obj資料
回到我們的問題上:Java的方法能否被序列化?通過我們程式碼示例及分析,想必大家對這個問題應該清楚了。通過ObjectOutputStream序列化物件,僅包含類的描述(而非定義),物件的狀態資料,由於缺少類的定義,也就是缺少SimpleTask的位元組碼,反序列化過程中就會出現ClassNotFound的異常。
如何讓我們反序列化的物件能正常使用呢?我們還需要了解類載入器。
類載入器:ClassLoader
ClassLoader在Java中是一個抽象類,ClassLoader的作用是載入類,給定一個類名,ClassLoader會嘗試查詢或生成類的定義,一種典型的載入策略是將類名對應到檔名上,然後從檔案系統中載入class file。
在我們的示例中,反序列化SimpleTask失敗,是因為JVM找不到類的定義,因此要確保正常反序列化,我們必須將SimpleTask的class檔案儲存下來,反序列化的時候能夠讓ClassLoader載入到SimpleTask的class。
接下來,我們對程式碼做一些改造,新增一個ClassManipulator類,用於將物件的class檔案匯出到當前目錄的檔案中,預設的檔名就是物件的類名(不含包名):
object ClassManipulator {
def saveClassFile(obj: AnyRef): Unit = {
val classLoader = obj.getClass.getClassLoader
val className = obj.getClass.getName
val classFile = className.replace('.', '/') + ".class"
val stream = classLoader.getResourceAsStream(classFile)
// just use the class simple name as the file name
val outputFile = className.split('.').last + ".class"
val fileStream = new FileOutputStream(outputFile)
var data = stream.read()
while (data != -1) {
fileStream.write(data)
data = stream.read()
}
fileStream.flush()
fileStream.close()
}
}
按照JVM的規範,假設對package.Simple這樣的一個類編譯,編譯後的class檔案為package/Simple.class,因此我們可以根據路徑規則,從當前JVM程序的Resource中得到指定類的class資料。
在刪除SimpleTask前,我們除了將task序列化到檔案外,還需要將task的class檔案儲存起來,執行完下面的程式碼,SimpleTask類就可以從程式碼中剔除了:
val task = new SimpleTask()
FileSerializer.writeObjectToFile(task, "task.ser")
ClassManipulator.saveClassFile(task)
由於我們儲存class檔案的方式比較特殊,既不在jar包中,也不是按package/ClassName.class這種標準的儲存方式,因此還需要實現一個自定義的FileClassLoader按照我們儲存class檔案的方式來載入所需的類:
class FileClassLoader() extends ClassLoader {
override def findClass(fullClassName: String): Class[_] = {
val file = fullClassName.split('.').last + ".class"
val in = new FileInputStream(file)
val bos = new ByteArrayOutputStream
val bytes = new Array[Byte](4096)
var done = false
while (!done) {
val num = in.read(bytes)
if (num >= 0) {
bos.write(bytes, 0, num)
} else {
done = true
}
}
val data = bos.toByteArray
defineClass(fullClassName, data, 0, data.length)
}
}
ObjectInputStream類用於物件的反序列化,在反序列化過程中,它根據序列化資料中類的descriptor資訊,呼叫resolveClass方法載入對應的類,但是通過Class.forName載入class使用的並不是我們自定義的FileClassLoader,所以如果直接使用ObjectInputStream進行反序列,依然會因為找不到類而報錯,下面是resolveClass的原始碼:
protected Class<?> resolveClass(ObjectStreamClass desc)
throws IOException, ClassNotFoundException
{
String name = desc.getName();
try {
return Class.forName(name, false, latestUserDefinedLoader());
} catch (ClassNotFoundException ex) {
Class<?> cl = primClasses.get(name);
if (cl != null) {
return cl;
} else {
throw ex;
}
}
}
為了能讓ObjectInputStream在序列化的過程中使用我們自定義的ClassLoader,我們還需要對FileSerializer中的readObjectFromFile方法做些改造,修改的程式碼如下:
def readObjectFromFile(file: String, classLoader: ClassLoader): Object = {
val fileStream = new FileInputStream(file)
val ois = new ObjectInputStream(fileStream) {
override def resolveClass(desc: ObjectStreamClass): Class[_] =
Class.forName(desc.getName, false, classLoader)
}
val obj = ois.readObject()
ois.close()
obj
}
最後,我們將反序列化的程式碼調整為:
val fileClassLoader = new FileClassLoader()
val task = FileSerializer.readObjectFromFile("task.ser", fileClassLoader).asInstanceOf[Task]
task.run()
Spark對closure序列化的處理
我們依然通過一個示例,快速瞭解下Scala對閉包的處理,下面是從Scala的REPL中執行的程式碼:
scala> val n = 2
n: Int = 2
scala> val f = (x: Int) => x * n
f: Int => Int = <function1>
scala> Seq.range(0, 5).map(f)
res0: Seq[Int] = List(0, 2, 4, 6, 8)
f是採用Scala的=>語法糖定義的一個閉包,為了弄清楚Scala是如何處理閉包的,我們繼續執行下面的程式碼:
scala> f.getClass
res0: Class[_ <: Int => Int] = class $anonfun$1
scala> f.isInstanceOf[Function1[Int, Int]]
res1: Boolean = true
scala> f.isInstanceOf[Serializable]
res2: Boolean = true
可以看出f對應的類為$anonfun$1是Function1[Int, Int]的子類,而且實現了Serializable介面,這說明f是可以被序列化的。
Spark對於資料的處理基本都是基於閉包,下面是一個簡單的Spark分散式處理資料的程式碼片段:
val spark = SparkSession.builder().appName("demo").master("local").getOrCreate()
val sc = spark.sparkContext
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
val sum = distData.map(x => x * 2).sum()
println(sum) // 30.0
對於distData.map(x => x * 2),map中傳的一個匿名函式,也是一個非常簡單的閉包,對distData中的每個元素*2,我們知道對於這種形式的閉包,Scala編譯後是可以序列化的,所以我們的程式碼能正常執行也合情合理。將入我們將處理函式的閉包定義到一個類中,然後將程式碼改造為如下形式:
class Operation {
val n = 2
def multiply = (x: Int) => x * n
}
...
val sum = distData.map(new Operation().multiply).sum()
...
我們在去執行,會出現什麼樣的結果呢?實際執行會出現這樣的異常:
Exception in thread "main" org.apache.spark.SparkException: Task not serializable
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:298)
...
Caused by: java.io.NotSerializableException: Operation
Scala在構造閉包的時候會確定他所依賴的外部變數,並將它們的引用存到閉包物件中,這樣能保證在不同的作用域中呼叫閉包不出現問題。
出現Task not serializable的異常,是由於我們的multiply函式依賴Operation類的變數n,雖然multiply是支援序列化的,但是Operation不支援序列化,這導致multiply函式在序列化的過程中出現了NotSerializable的異常,最終導致我們的Task序列化失敗。為了確保multiply能被正常序列化,我們需要想辦法去除對Operation的依賴,我們將程式碼做如下修改,在去執行就可以了:
class Operation {
def multiply = (x: Int) => x * 2
}
...
val sum = distData.map(new Operation().multiply).sum()
...
Spark對閉包序列化前,會通過工具類org.apache.spark.util.ClosureCleaner嘗試clean掉閉包中無關的外部物件引用,ClosureCleaner對閉包的處理是在執行期間,相比Scala編譯器,能更精準的去除閉包中無關的引用。這樣做,一方面可以儘可能保證閉包可被序列化,另一方面可以減少閉包序列化後的大小,便於網路傳輸。
我們在開發Spark應用的時候,如果遇到Task not serializable的異常,就需要考慮下,閉包中是否或引用了無法序列化的物件,有的話,嘗試去除依賴就可以了。
Spark中實現的序列化工具有多個:
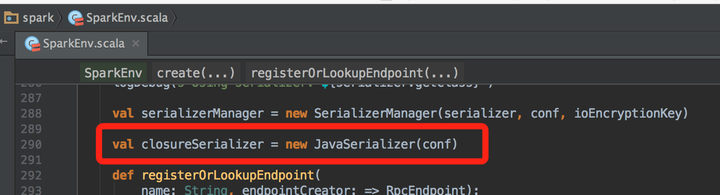
從SparkEnv類的實現來看,用於閉包序列化的是JavaSerializer:
JavaSerializer內部使用的是ObjectOutputStream將閉包序列化:
private[spark] class JavaSerializationStream(
out: OutputStream, counterReset: Int, extraDebugInfo: Boolean)
extends SerializationStream {
private val objOut = new ObjectOutputStream(out)
...
}
將閉包反序列化的核心程式碼為:
private[spark] class JavaDeserializationStream(in: InputStream, loader: ClassLoader)
extends DeserializationStream {
private val objIn = new ObjectInputStream(in) {
override def resolveClass(desc: ObjectStreamClass): Class[_] =
try {
Class.forName(desc.getName, false, loader)
} catch {
case e: ClassNotFoundException =>
JavaDeserializationStream.