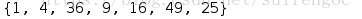python---字典生成式和集合生成式
阿新 • • 發佈:2019-02-12
字典生成式
1: 假設有20個學生,學生分數在60-100之間,篩選出成績在90分以上的學生
方法一
import random
stuInfo={}
for i in range(20):
name = "westos"+ str(i)
score = random.randint(60,100)
stuInfo[name] = score
stuInfo["westos"+ str(i)] = random.randint(60,100)
print(stuInfo)
# 篩選出score>90
highScore = {}
for name, score in stuInfo.items 
方法二 字典生成式
import random
stuInfo = {"westos"+ str(i):random.randint(60,100)for i in range(20)}
print(stuInfo)
# 篩選出score>90
print({ name:score for name, score in stuInfo.items() if score > 90 })
- 假設已有若干使用者名稱字及其喜歡的電影清單,現有某使用者, 已看過並喜歡一些電影, 現在想找新電影看看, 又不知道看什麼好.
思路:
根據已有資料, 查詢與該使用者愛好最相似的使用者,
即看過並喜歡的電影與該使用者最接近,
然後從那個使用者喜歡的電影中選取一個當前使用者還沒看過的電影進行推薦.
userInfo = {
'user1':{'file1', 'file2', 'file3'},
'user2':{'file2', 'file2', 'file4'},
}
# # 1. 隨機生成電影清單
import random
data = {} # 儲存使用者及喜歡電影清單的資訊;
for userItem in range(10):
files = set([])
for fileItem in range(random.randint(4,15)):
files.add( "film" + str(fileItem))
data["user" 
3.將字典的key值和value值調換;
d = {'a':'apple', 'b':'bob', 'c':'come'}
print({v:k for k,v in d.items()})
print({k:k.upper() for k,v in d.items()})
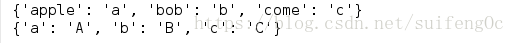
4.大小寫計數合併 : key值最終全部為小寫.
d1 = {'A':10, 'b':3, 'a':5, 'B':8, 'd':1}
print({k.lower(): d1.get(k.upper(),0)+d1.get(k.lower(),0) for k,v in d1.items()})
# print({k.lower(): d1[k.upper()]+d1[k.lower()] for k,v in d1.items()}) # 報錯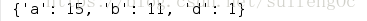
集合生成式
s = {1,2,3,4,5,6,7}
# 集合生成式
print({i**2 for i in s })