
這就是搜尋引擎(一)—引擎架構、網路爬蟲、索引建立
這個系列的文章是一隻試圖通過產品角度出發去理解複雜龐大搜索引擎的汪寫出來的,不足之處很多,歡迎廣大技術、非技術同學閱讀後指正錯誤,我們一起探討共同進步。
本篇主要介紹搜尋引擎的架構、網路爬蟲、及索引建立。
一、搜尋引擎基本資訊
1.1 什麼是搜尋引擎
通俗來講就是從網際網路海量資訊中撈出使用者感興趣的內容提供給使用者。
1.2 發展歷程
分類目錄的:純人工收集整理,代表是導航,如yahoo和hao123
—> 文字檢索:採用資訊檢索模型查詢關鍵詞與網頁文字的相關程度
—> 連結分析:利用網頁間的連結關係分析網頁重要性,代表技術google的pageRank
—>使用者中心:理解使用者需求為核心,典型千人千面。
1.3搜尋引擎基本架構
 該架構主要有三方面的作用:
1、通過爬蟲獲得網際網路上的海量網頁資訊,儲存在本地並建立索引方便查詢;
2、使用者輸入查詢query,解析查詢意圖,並將query分發進行查詢;
3、使用query通過各種演算法對索引中的文件(網頁)排序,返回最符合意圖的若干條結果。
本篇主要從第一方面作用來介紹搜尋引擎。
該架構主要有三方面的作用:
1、通過爬蟲獲得網際網路上的海量網頁資訊,儲存在本地並建立索引方便查詢;
2、使用者輸入查詢query,解析查詢意圖,並將query分發進行查詢;
3、使用query通過各種演算法對索引中的文件(網頁)排序,返回最符合意圖的若干條結果。
本篇主要從第一方面作用來介紹搜尋引擎。
二、網路爬蟲
2.1通用爬蟲框架

爬取流程:
選取部分網頁作為種子url,放入待抓取url佇列
—>讀取待抓取url通過DNS解析,下載網頁
—>將下載的url儲存到本地頁面庫並建立索引,url放入已抓取url佇列
—>解析已下載url,抽取所有連結,與已抽取url佇列去重後放入待抓取url
—>繼續下載待抓取url佇列
—>形成迴圈,直至待抓取url佇列為空。
2.2 爬蟲類型
批量型爬蟲(batch crawler):有明確抓取範圍和目標,達到目標即停止。
增量型爬蟲(incremental crawler):持續不斷抓取,對抓到的網頁定期更新。
垂直型爬蟲(focused crawler):抓取階段識別網頁是否與主題相關,判斷是否抓取。
2.3 爬蟲抓取策略
目的:優先選擇重要網頁進行抓取。
寬度優先遍歷策略(breathfirst):將新下載網頁包含的連結直接追加到待抓取URl佇列末尾。該策略隱含了一些網頁優先順序假設。
非完全pagerank策略(partial pagerank):已下載和待抓取url一起形成網頁集合,在集合內進行pagerank計算,將待抓取url按照pagerank排序。為提升效率,當新下載網頁數超過K 個重新計算一遍pagerank,對於新抽取出的且沒有pagerank值的網頁,將該網頁所有入鏈傳到pagerank值彙總,作為臨時pagerank值進行比較。
OCIP策略(online pageimportance computation):每個頁面給予相同現金(cash),下載某個頁面P後,頁面p的cash均分到包含的每個連結上,最終根據連結cash大小排序下載。
大站優先策略(larger sites first):優先下載等待下載頁面最多的網站。
2.4 網頁更新策略
目的:決定何時更新已下載的網頁,使得本地資料與網際網路原始頁面內容一致。
歷史參考策略:過去頻繁更新的網頁未來也會頻繁更新。
使用者體驗策略:儲存網頁的多個版本,根據每次內容變化對搜尋質量影響得到平均值,作為判斷抓取更新的依據。
聚類抽樣策略:網頁聚類。具有相同屬性的網頁更新時間相同
2.5 暗網抓取方法
對於儲存於資料庫的無法獲得的網頁資訊,採用富含資訊查詢模板方式來抓取。
判斷是否是富含資訊查詢模板的方法是ISIT演算法。基本思想是從一維模板開始逐個考察,若是富含資訊查詢模板,則擴充套件到二維模板,如此類推逐步增加維數,直至無法再找到富含資訊查詢模板。
爬蟲的目的就是儘量獲得最新、最全的網頁資訊儲存到本地。
三、建立索引
爬蟲將文件(即網頁)資訊下載到本地後,需要對文件建立倒排索引。倒排索引就是抽取文件中的單詞,建立單詞與文件的對應關係,這樣就能通過關鍵詞的匹配查詢到相應的文件。
3.1名詞解釋
TF:單詞頻率
DF:文件頻率
單詞詞典:維護文件集合中出現的所有單詞相關資訊,同時記錄單詞對應的倒排列表在倒排檔案中的位置資訊。
文件編號(document id):文件集合內每個文件賦予一個唯一的內部編號,在儲存時為壓縮資料使用文件編號差值(D-gap)來儲存。倒排列表(postinglist):記載出現過某個單詞的所有文件的文件列表及單詞在文件中出現的位置。每條記錄稱為一個倒排項(posting)。

倒排檔案(inverted file):所有單詞的倒排列表順序地存在磁碟的某個檔案裡。
倒排索引(inverted index):實現單詞-文件矩陣的一種具體儲存形式。通過倒排索引,可以獲得包含這個單詞的文件列表。由兩部分組成:單詞詞典、倒排檔案。
3.2 索引建立
3.2.1 單詞詞典的建立
常用的資料結構是雜湊表和樹形詞典結果
雜湊加連結串列:主體為雜湊表,每個表項儲存指標,指向相同雜湊值單詞形成的衝突連結串列。
樹形詞典結構:詞典項需要按照大小排序,屬於層級查詢結構。(說實話沒弄明白)
3.2.2 索引建立
兩遍文件遍歷法(2-pass in-memory inversion 全記憶體索引建立):第一遍掃描統計資訊(包括文件個數、單詞個數、單詞出現資訊DF等)並分配記憶體等資源,做準備工作。第二遍掃描,填充第一遍掃描所分配的記憶體空間。
本方法需要記憶體足夠大,且兩遍掃描速度較慢。
排序法(sort-based inversion):分配固定大小空間用來存放詞典資訊和索引中間結果,空間被耗光時,中間結果寫入磁碟清空記憶體,用作下一輪存放索引中間結果的儲存區。
歸併法(merge-based inversion):整體流程與排序法類似,但排序法在記憶體中放的是詞典資訊和三元組資料,二者間並沒有直接聯絡,歸併法是在記憶體中建立起目前處理文件子集的整套倒排索引;中間結果寫入磁碟時,排序法將三元組資料排序後寫入磁碟臨時檔案,詞典一直保留在記憶體中,歸併法將單詞和對應倒排列表寫入磁碟,隨後徹底清空所佔記憶體。
3.2.3 索引的更新
網頁在不斷變化,為保證索引能實時動態更新,還需要新增上臨時索引、已刪除文件列表。
臨時索引:記憶體中實時建立的倒排索引。
已刪除文件列表:儲存已刪除文件的id,形成文件ID列表。
文件被更改時,原先文件放入刪除佇列,解析更改後的文件內容放入臨時索引中,通過該方式滿足實時性。使用者輸入query查詢時從倒排索引和臨時索引中獲得結果,然後利用刪除文件列表過濾形成最終搜尋結果。
臨時索引的更新策略:
1、完全重建:新增文件超過一定數量,對新老文件合併後重新建立索引。
2、再合併策略:新增文件超過一定數量,臨時索引合併到老索引中。
3、原地更新策略:增量索引的倒排列表追加到老索引相應位置的末尾。
4、混合策略:將單詞根據不同性質分類,不同類別單詞采取不同的索引更新策略。
3.2.4 索引的查詢
常用的兩種查詢策略
一次一文件:以倒排列表中包含的文件為單位,將文件與查詢的最終相似性得分計算完畢再計算另外一個文件的得分。
一次一單詞:以單詞為單位,計算文件對於搜尋單詞的得分,最後將所有單詞得分相加。
3.3索引壓縮
使用者查詢時需要將倒排列表資訊從磁碟讀取到記憶體中,搜尋引擎的索引量都非常巨大,所以需要對索引進行壓縮。索引主要包含兩個部分:單詞詞典和對應的倒排列表,壓縮也主要針對這兩部分進行。壓縮演算法指標(按重要性由高到低排列):解壓速度、壓縮率、壓縮速度。
3.3.1 詞典壓縮
 上圖詞典中DF和倒排列表指標都能用4個位元組表示,但單詞資訊由於詞長不同可能會造成儲存空間浪費。
上圖詞典中DF和倒排列表指標都能用4個位元組表示,但單詞資訊由於詞長不同可能會造成儲存空間浪費。
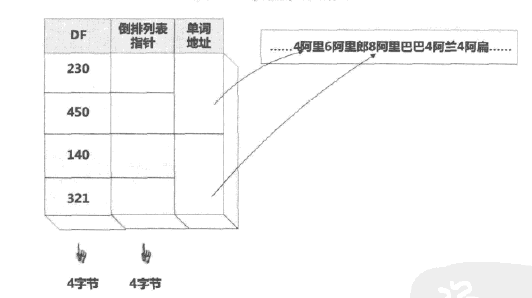
如上圖的優化結構中,將連續詞典分塊,每個單詞增加長度資訊,多個單詞共用指標資訊。這樣文件頻率、倒排指標和單詞地址都能固定大小。
3.3.2 文件編號重排
對文件ID重編號使得倒排列表中相鄰兩個文件的編號也儘可能相鄰,使相鄰文件的D-Gap值儘可能小,壓縮演算法效率會更高。具體演算法不展開。
3.3.3 靜態索引裁剪(static index pruning)
這是一種有失真壓縮,清除索引項中不重要的部分,同時儘可能保證搜尋質量。常用的兩種方法:以單詞為中心的索引裁剪和以文件為中心的索引裁剪。
以單詞為中心的索引裁剪需要計算單詞與其對應的文件的相似性,據此判斷是否保留索引項。索引建立好之後裁剪。
以文件為中心的裁剪計算單詞的重要性,拋棄不重要的單詞。建立索引之前裁剪。
至此,搜尋引擎完成了網頁資料的獲取與儲存,其餘部分將在接下來的文章中介紹。
本文所有截圖來自於《這就是搜尋引擎:核心技術詳解》,如有版權問題,我再重畫 \ (-- 。 --) /