
分析ajax介面抓取今日頭條
抓取ajax網站可以通過分析ajax介面的方式獲取到返回的json資料,從而抓取到我們想要的資料,以今日頭條為例,如何分析ajax介面,模擬ajax請求爬取資料。
以今日頭條的街拍為例,網頁上一頁只顯示部分資料,檢視後續資料需要滑鼠下滑,這裡我們分析一下它的ajax介面。
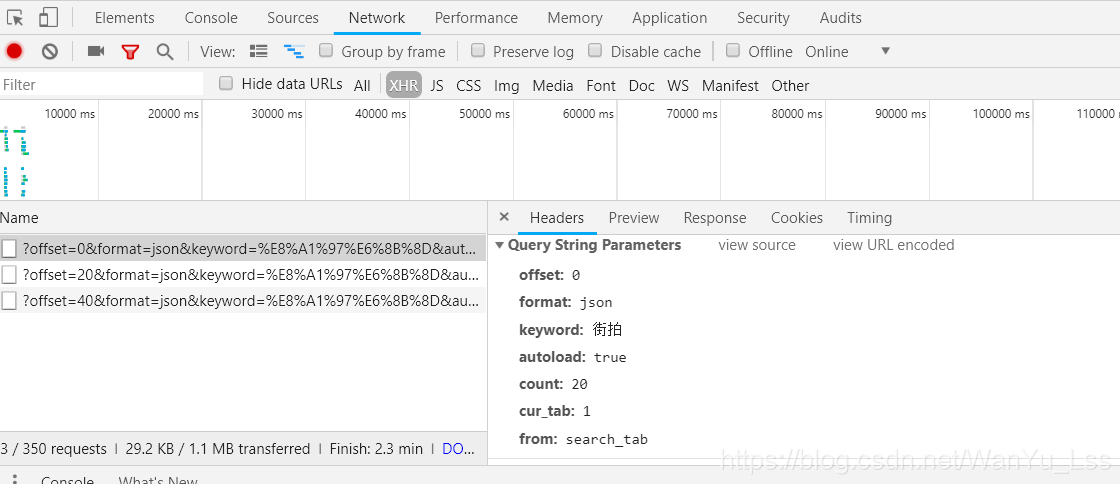
開啟開發者工具,選擇network,點選XHR過濾出來ajax請求,可以看到這裡有很多引數,其中一眼能看出來的引數就是keyword,是我們搜尋的關鍵字。接著看它的Preview資訊。
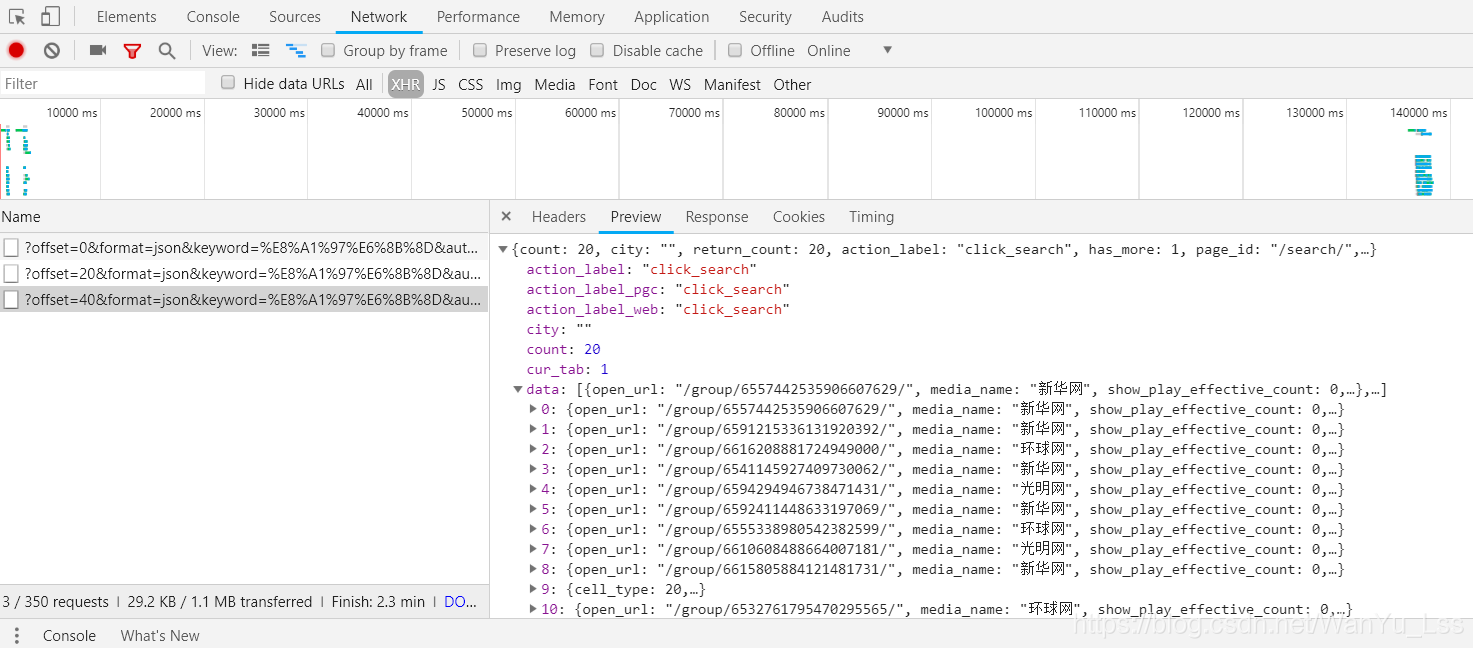
Preview資訊中可以看到包含有很多data資訊,點開可以看到其中包含許多有用的資訊,像街拍標題,圖片地址。
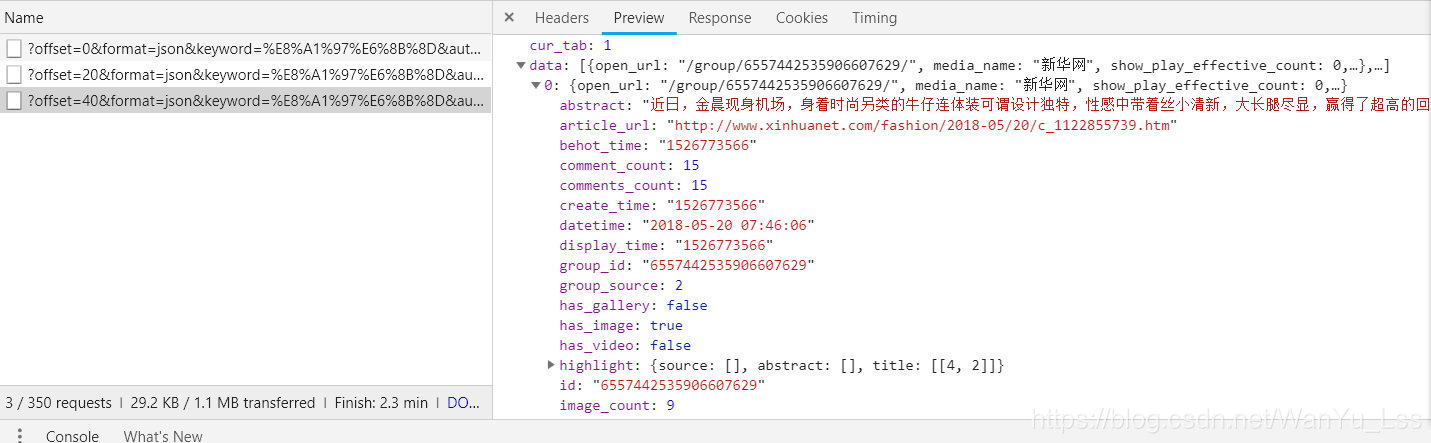
當滑鼠往下滑動,過濾出來的ajax請求會多出來一條,如下所示
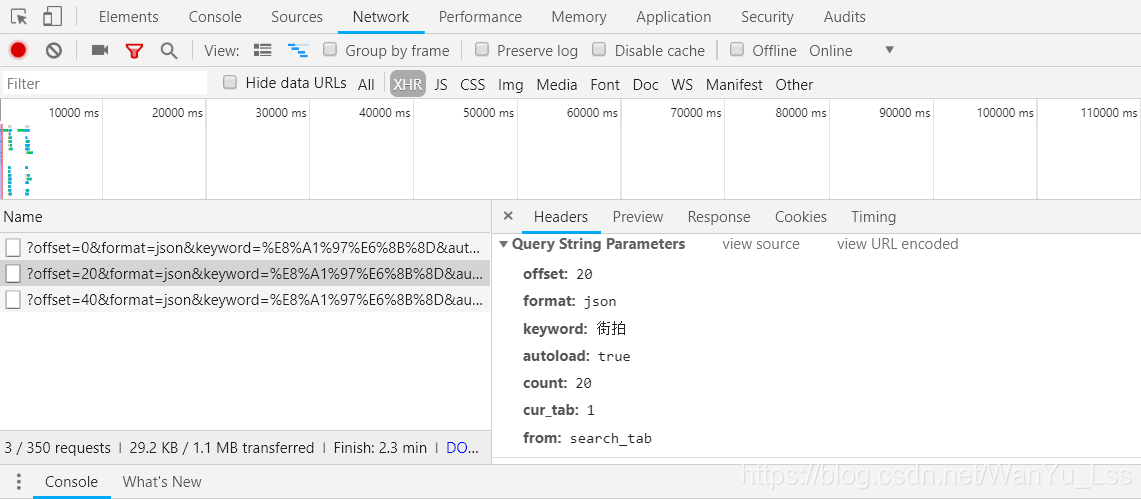
可以看到其中的offset引數由0變成了20,細心觀察網頁可以發現網頁顯示的資訊一頁恰好是20條。

這是當滑鼠滑動到第三頁的時候,可以看到offset引數變成了40,當第一頁的時候,offset引數為0,第二頁offset引數為20,第三頁引數為40。這就不難發現offset引數實際是偏移量,用來實現翻頁的引數。那我們就可以通過urlencode方法將這些引數拼接到url後面,發起ajax請求,通過控制傳入的offset引數來控制翻頁,然後通過response.json()來獲取網頁返回的json資料。
程式碼思路:1.分析網頁的ajax介面,需要傳入哪些資料2.通過urlencode鍵引數拼接到需要請求的url之後,通過控制offset引數來指定爬取哪一頁的內容。3.生成不同頁的請求,獲取json資料中圖片的url資訊4.請求圖片的url,下載圖片5.儲存到資料夾。
實際程式碼
import requests from urllib.parse import urlencode,urljoin import os from hashlib import md5 headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36", "X-Requested-With":"XMLHttpRequest" } def get_page(offset): """ :param offset: 偏移量,控制翻頁 :return: """ params = { "offset":offset, "format":"json", "keyword":"街拍", "autoload":"true", "count":"20", "cur_tab":"1", "from":"search_tab" } url = "https://www.toutiao.com/search_content/?" + urlencode(params) try: response = requests.get(url,headers=headers,timeout=5) if response.status_code == 200: return response.json() except requests.ConnectionError as e: return None def get_image(json): """ :param json: 獲取到返回的json資料 :return: """ if json: for item in json.get("data"): title = item.get("title") images = item.get("image_list") if images: for image in images: yield { "title":title, "image":urljoin("http:",image.get("url")) if type(image) == type({"t":1}) else urljoin("http:",image) } def save_images(item): """ 將圖片儲存到資料夾,以標題命名資料夾 :param item: json資料 :return: """ if item.get("title") != None: if not os.path.exists(item.get("title")): os.mkdir(item.get("title")) else: pass try: response = requests.get(item.get("image")) if response.status_code == 200: file_path = "{0}/{1}.{2}".format(item.get("title") if item.get("title") != None else "Notitle",md5(response.content).hexdigest(),"jpg") if not os.path.exists(file_path): with open(file_path,"wb") as f: f.write(response.content) else: print("Already Downloaded",file_path) except requests.ConnectionError: print("Failed Download Image") def main(offset): """ 控制爬取的主要邏輯 :param offset: 偏移量 :return: """ json = get_page(offset) for item in get_image(json): print(item) save_images(item) groups = [i*20 for i in range(1,10)] if __name__ == '__main__': for group in groups: main(group)
爬取的成果
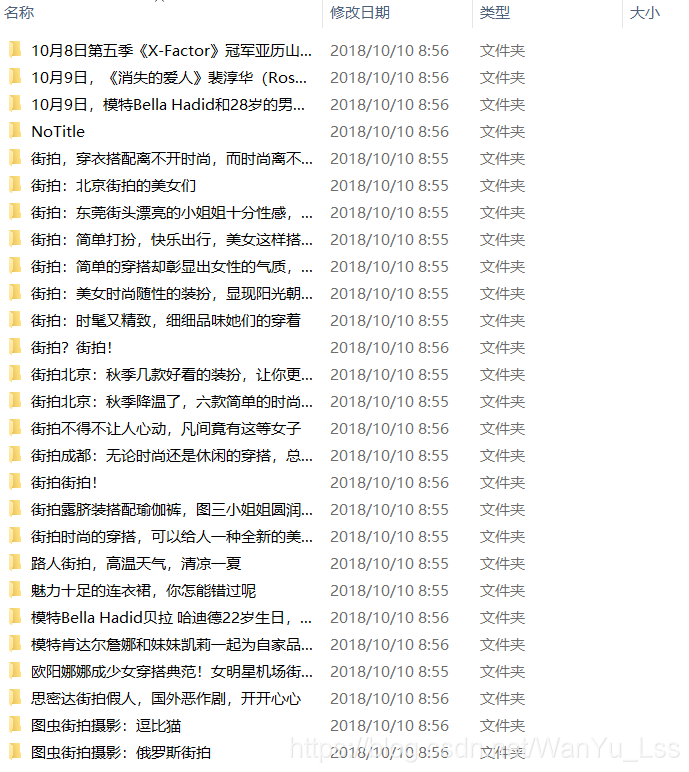
通過分析ajax介面,模擬ajax請求進行抓取相對於selenium模擬來說較簡單,但是程式碼複用性差,因為每個網頁的介面都是不同的,所以抓取ajax載入的資料時,使用selenium模擬還是直接抓取介面資料需要小夥伴自己通過實際需要來選擇。