
機器學習演算法原理與實踐(六)、感知機演算法
感知機
感知機是二分類的線性分類模型,輸入為例項的特徵向量,輸出為例項的類別(取+1和-1)。感知機對應於輸入空間中將例項劃分為兩類的分離超平面。感知機旨在求出該超平面,為求得超平面匯入了基於誤分類的損失函式,利用梯度下降法對損失函式進行最優化(最優化)。感知機的學習演算法具有簡單而易於實現的優點,分為原始形式 和 對偶形式。感知機預測是用學習得到的感知機模型對新的例項進行預測的,因此屬於判別模型。感知機是一種線性分類模型,只適應於線性可分的資料,對於線性不可分的資料模型訓練是不會收斂的。
感知機模型
假設輸入空間(特徵向量)是
該函式稱為感知機,其中
這裡
如果我們將sign稱之為啟用函式的話,感知機與logistic regression的差別就是感知機啟用函式是sign,logistic regression的啟用函式是sigmoid。sign(x)將大於0的分為1,小於0的分為-1;sigmoid將大於0.5的分為1,小於0.5的分為0。因此sign又被稱為單位階躍函式,logistic regression也被看作是一種概率估計。
在神經網路以及DeepLearning中會使用其他如tanh,relu等其他啟用函式。
感知機的學習策略
如下圖: 線性可分資料集
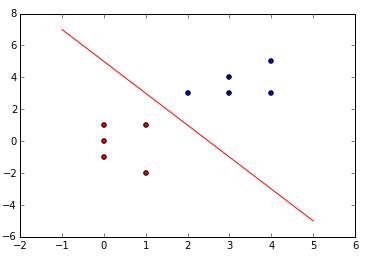
對於一個給定的線性可分的資料集,如上面的資料點,紅色代表正類,藍色代表負類,感知機的主要工作就是尋找一個線性可分的超平面
如果資料集可以被一個超平面完全劃分,則稱該資料集是線性可分的資料集,否則稱為線性不可分的資料集,如下圖:
非線性可分資料集
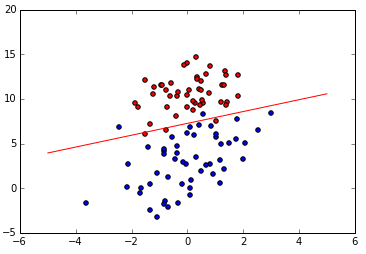
感知機分類效果:
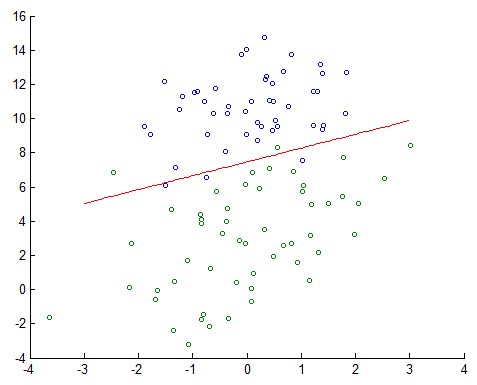
logistic regression分類效果:
為了尋找上面那條能夠將資料集完全劃分的超平面
為了使用梯度下降法求解
對誤分類點
感知機的原始形式
虛擬碼
輸入:訓練資料集
T=(x1,y1),(x2,y2),⋯,(xN,yN), 其中xi∈X=Rn,yi∈Y=−1,+1.i=1,2,⋯,N; 學習率η(0<η≤1)
輸出:w,b ;感知機模型f(x)=sign(w⋅x+b)
1、選取初值w0,b0
2、在訓練集中選取資料(xi,yi)
3、yi(w⋅xi+b)≤0
w=w+ηyixib=b+ηyi
4、轉至2直到沒有誤分類點
直觀解釋:當一個例項點被誤分的時候,即調整
感知機
感知機是二分類的線性分類模型,輸入為例項的特徵向量,輸出為例項的類別(取+1和-1)。感知機對應於輸入空間中將例項劃分為兩類的分離超平面。感知機旨在求出該超平面,為求得超平面匯入了基於誤分類的損失函式,利用梯度下降法對損失函式進行最優化(最優
卡爾曼濾波器是一種利用線性系統狀態方程,通過系統輸入輸出觀測資料,對系統狀態進行最優估計的演算法。而且由於觀測包含系統的噪聲和干擾的影響,所以最優估計也可看做是濾波過程。
卡爾曼濾波器的核心 寫在前面的話
在閱讀 webpack4.x 原始碼的過程中,參考了《深入淺出webpack》一書和眾多大神的文章,結合自己的一點體會,總結如下。
總述
webpack 就像一條生產線,要經過一系列處理流程後才能將原始檔轉換成輸出結果。 這條生產線上的每個處理流程的職責都是單一的,多個流程之間有存在依賴關 系統 rest 引擎 服務器 分類 file creat 產品 maintain 歡迎訪問網易雲社區,了解更多網易技術產品運營經驗。虛擬化是一種資源管理技術,將計算機的各種資源予以抽象、轉換後呈現出來, 打破實體結構間的不可切割的障礙,使用戶可以比原本更好的方式來應用這些資
舉例:電影推薦系統
電影評分表
張三
李四
王五
小明
小時代
1
5
?
5
精武英雄
?
3
5
4
摔跤吧,爸爸
1
5
?
5
死侍
?
匿名函式
lambda
# 1.parameter_list 引數列表
# 2.expression 函式體,只能是有一些簡單的,注意不是程式碼塊,比如不能寫賦值語句
# 3.不需要return
lambda parameter_list: expression
複製程式碼
def add(x,y):
Merge k Sorted Lists
題目
Merge k sorted linked lists and return it as one sorted list. Analyze and describe its complexity.
Example: 一、JDBC的工作原理 Struts在本質上是java程式,要在Struts應用程式中訪問資料庫,首先,必須搞清楚Java Database Connectivity API(JDBC)的工作原理。正如其名字揭示的,JDBC庫提供了一個底層API,用來支援獨立於任何特定SQL實
一、演算法原理與模型
knn演算法即最近鄰演算法,其原理非常簡單即根據給定的資料集,計算資料集中點的特徵到待分類資料的歐氏距離,然後選擇距離最近的k個作為判斷依據,這k個數據中出現類別最多的作為新輸入資料的label。模型用公式表示如下:
二、python程式碼實現
本篇我們來討論一下struts的國際化程式設計問題,即所謂的i18n程式設計問題,這一篇我們討論其基礎部分。與這個問題緊密相關的是在各java論壇中被頻繁提及的中文亂碼問題,因為,英、美程式設計人員較少涉及到中文亂碼問題,因此,這方面的英文資料也是非常奇缺的,同時也很少找到這方面比較完整的中文資料,本文也嘗試
本篇我們來討論一下struts的國際化程式設計問題,即所謂的i18n程式設計問題,這一篇我們討論其基礎部分。與這個問題緊密相關的是在各java論壇中被頻繁提及的中文亂碼問題,因為,英、美程式設計人員較少涉及到中文亂碼問題,因此,這方面的英文資料也是非常奇缺的,同時也很少找到這
(第2部分)
下面,我們就一步步按照上面所說的步驟來完成我們的應用程式:
第一步,我們的應用程式的Views部分包含兩個.jsp頁面:一個是登入頁面logon.jsp,另一個是使用者登入成功後的使用者功能頁main.jsp,暫時這個頁面只是個簡單的歡迎頁面。
其中,
本文我們來討論一下Struts中的輸入校驗問題。我們知道,資訊系統有垃圾進垃圾出的特點,為了避免垃圾資料的輸入,對輸入進行校驗是任何資訊系統都要面對的問題。在傳統的程式設計實踐中,我們往往在需要進行校驗的地方分別對它們進行校驗,而實際上需要校驗的東西大多都很類似,如必需的欄位
在上一篇文章中介紹JavaScript實現級聯下拉選單的例子,本篇繼續介紹一個利用現存的JavaScript程式碼配合struts構成一個樹型選單的例子。 大家知道,樹型選單在應用中有著十分廣泛的用途。實現樹型選單的途徑較多,本文介紹的一種覺得理解起來比較直觀,與上篇 前言
Spring Boot眾所周知是為了簡化Spring的配置,省去XML的複雜化配置(雖然Spring官方推薦也使用Java配置)採用Java+Annotation方式配置。如下幾個問題是我剛開始接觸Spring Boot的時候經常遇到的一些疑問,現在總結出來希望能幫助到更多的人理解Spring B 概論
深度優先搜尋屬於圖演算法的一種,是一個針對圖和樹的遍歷演算法,英文縮寫為 DFS 即 Depth First Search。深度優先搜尋是圖論中的經典演算法,利用深度優先搜尋演算法可以產生目標圖的相應拓撲排序表,利用拓撲排序表可以方便的解決很多相關的圖論問題,如最大路徑問題等等。一般用堆資料結構來輔
一、sklearn轉換器
想一下之前做的特徵工程的步驟?
1 例項化 (例項化的是一個轉換器類(Transformer))
2 呼叫fit_transform(對於文件建立分類詞頻矩陣,不能同時呼叫)
我們 blog 核心 灰度變換 圖像復原 京東 .html href target 數字圖像處理
本文系《數字圖像處理原理與實踐(MATLAB版)》一書的勘誤表。【內容簡單介紹】本書全面系統地介紹了數字圖像處理技術的理論與方法,內容涉及幾何變換、灰度變換、圖像增強、圖像切割、 組類型 運算 奇怪 head 不能 gui 簡單的 版本 布局 編碼原則:
一般原則
預處理原則
命名和布局原則
類原則
函數和表達式原則
硬實時原則
關鍵系統原則
(硬實時原則、關鍵系統原則僅用於硬實時和關鍵系統程序設計)
(嚴格原則都用一個大寫字母R及其編號標識,而 效果 進階 str 二進制位 bsp () 都是 有符號 重新 有符號數與無符號數的程序設計原則:
當需要表示數值時,使用有符號數(如 int)。
當需要表示位集合時,使用無符號數(如unsigned int)。
有符號數和無符號數混合運算有可能會帶來災難性的後果。例如 相關推薦
機器學習演算法原理與實踐(六)、感知機演算法
機器學習演算法原理與實踐(三)、卡爾曼濾波器演算法淺析及matlab實戰
Webpack原理與實踐(一):打包流程
Docker容器的原理與實踐(上)
推薦系統演算法理論與實踐(1)
python3入門與實踐(六):函數語言程式設計
演算法設計與分析(六)(上週第五週的寫錯標題,這才是真正的第六週)
Struts原理與實踐(三)
knn演算法原理與實現(1)
struts原理與實踐(四)
Struts原理與實踐(4)
struts原理與實踐(二)
Struts原理與實踐(6)
Struts原理與實踐(8)
Spring Boot自動配置原理與實踐(一)
深度優先搜尋原理與實踐(java)
機器學習實踐(六)—sklearn之轉換器和估計器
數字圖像處理原理與實踐(MATLAB版)勘誤表
編碼原則實例------c++程序設計原理與實踐(進階篇)
有符號數和無符號數------c++程序設計原理與實踐(進階篇)