
Tesseract 3.02中文字型檔訓練----整理
下載chi_sim.traindata字型檔
下載tesseract-ocr-setup-3.02.02.exe
安裝到e:\Tesseract-ocr目錄下
1.Tesseract-OCR的命令列使用
開啟DOS介面,輸入tesseract:

如果出現如上輸出,表示安裝正常。
下載jTessBoxEditor用於修改box檔案
下載地址:http://download.csdn.net/detail/a443475601/5896893 裡面自帶java執行庫,安裝後 然後啟動命令列 java -jar jTessBoxEditor.jar即可開啟
為了方便 tif文面命名格式[lang].[fontname].exp[num].tif
lang是語言 fontname是字型
比如我們要訓練自定義字型檔 chi 字型名:黑體
那麼我們把tif檔案重新命名 chi.黑體.exp0.tif
把多個.tif檔案合併成一個.tif檔案
下面開始訓練字型檔:
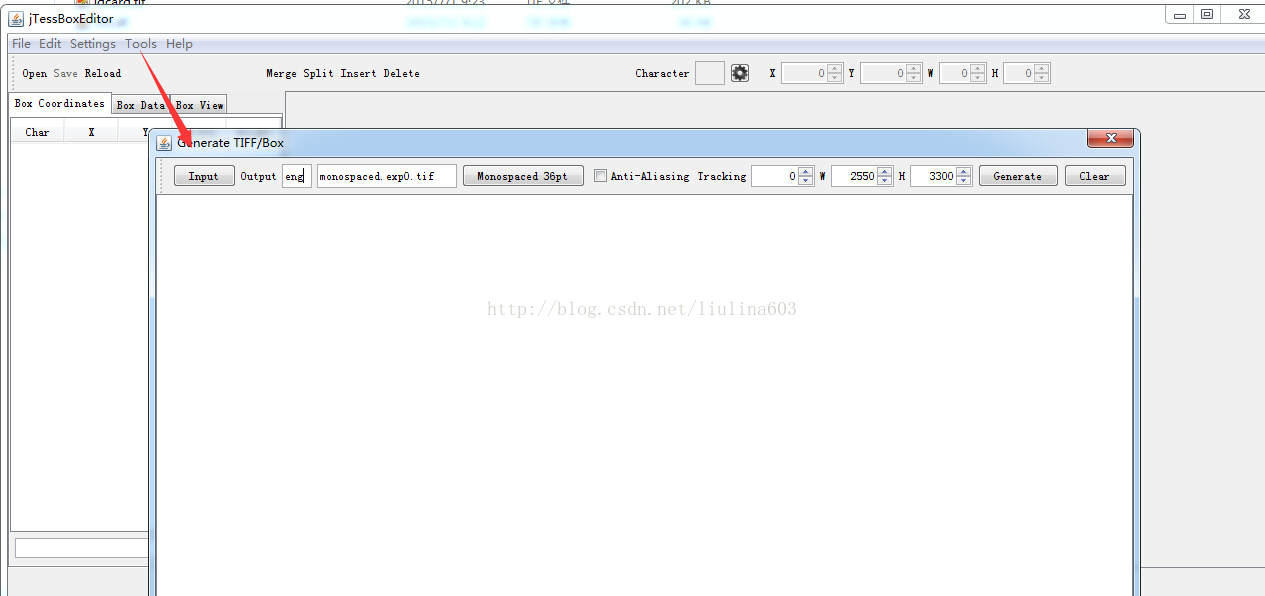
下面第一條命令與上圖功能一樣,產生.box檔案
1、E:\Tesseract-ocr\tesseract.exe chi.黑體.exp0.tif chi.黑體.exp0 batch.nochop makebox
執行以上命令也會產生一個box檔案。產生box檔案的過程是必須的,也是最重要的,沒有box檔案以下的內容都無法進行。
需要記住的是生成的.box要和這個.tif檔案同在一個目錄下。
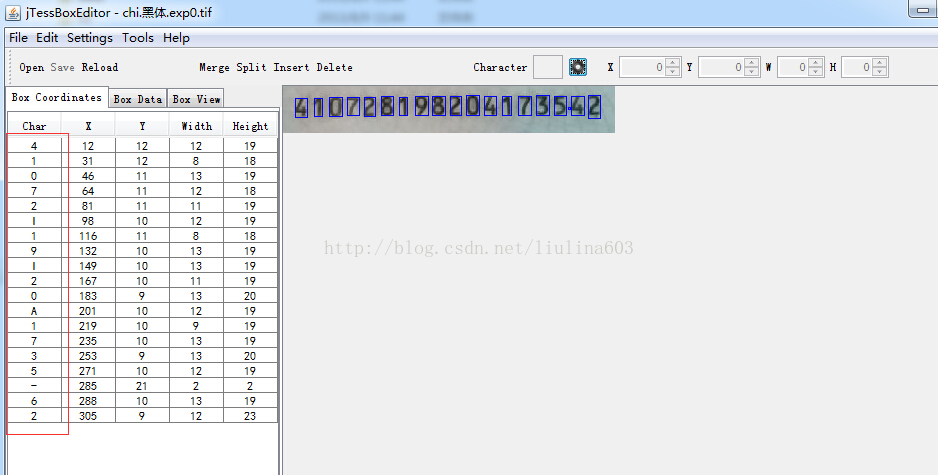
2、文字校正。執行jTessBoxEditor工具,開啟chi.黑體.exp0.tif檔案(必須將上一步生成的.box和.tif樣本檔案放在同一目錄),如上圖所示。可以看出有些字元識別的不正確,可以通過該工具手動對每張圖片中識別錯誤的字元進行校正。校正完成後儲存即可。
2、產生字元特徵檔案
tesseract chi.黑體.exp0.tif chi.黑體.exp0 nobatch box.train
這一步將會產生 chi.黑體.exp0.tr檔案和一個 chi.黑體.exp0.txt檔案,txt檔案貌似沒什麼用,看看而以。
3、計算字符集
unicharset_extractor chi.黑體.exp0.box
這一步會產生一個unicharset字符集檔案.
4、定義字型特徵檔案,---Tesseract-OCR3.01以上的版本在訓練之前需要建立一個名稱為font_properties.txt的字型特徵檔案
手工建立一個檔案font_properties.txt
內容如:黑體 0 0 0 0 0
注意:這裡 必須與訓練名中的名稱保持一致,填入下面內容 ,這裡全取值為0,表示字型不是粗體、斜體等等。
5、聚集字元特徵
1) shapeclustering -F font_properties.txt -U unicharset chi.黑體.exp0.tr 注意:如果font_properties不加副檔名.txt,可能會報錯
2) mftraining -F font_properties.txt -U unicharset -O chi.unicharset chi.黑體.exp0.tr
使用上一步產生的字符集檔案unicharset,來生成當前新語言的字符集檔案chi.unicharset。同時還會產生圖形原型檔案inttemp和每個字元所對應的字元
特徵數檔案pffmtable。最重要的就是這個inttemp檔案了,他包含了所有需要產生的字的圖形原型。
3)cntraining chi.黑體.exp0.tr
這一步產生字元形狀正常化特徵檔案normproto。
6、把目錄下的unicharset、inttemp、pffmtable、shapetable、normproto這五個檔案前面都加上chi.
7、執行combine_tessdata chi.
然後把chi.traineddata放到tessdata目錄
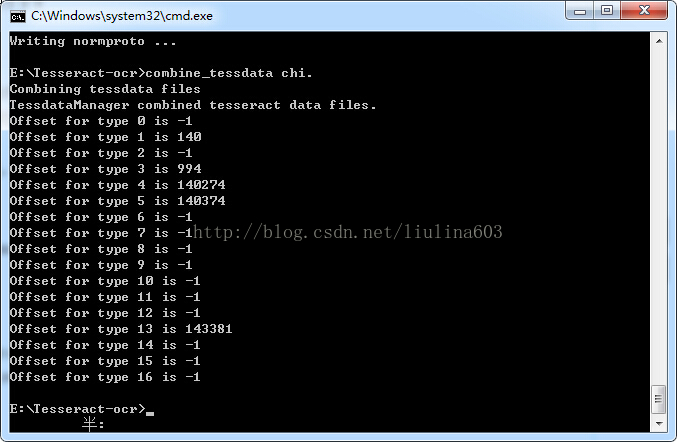
必須確定的是第2、4、5、6行的資料不是-1,那麼一個新的字典就算生成了.
8、用新的字型檔對圖片進行分析
tesseract test.tif output -l chi
內容會寫到output.txt檔案中,這個檔案與測試圖片在同一個目錄下
識別問題:
1、一個字分成2部分識別,如:好,會認為女 子,如何解決???
4.Tesseract-OCR的QA合集
A.ImageMagick是什麼?
ImageMagick是一個用於檢視、編輯點陣圖檔案以及進行影象格式轉換的開放原始碼軟體套裝
我在這裡之所以提到ImageMagick是因為某些圖片格式需要用這個工具來轉換。
B.Leptonica 是什麼?
Leptonica 是一影象處理與影象分析工具,tesseract依賴於它。而且不是所有的格式(如jpg)都能處理,所以我們需要藉助imagemagick做格式轉換。
Here's a summary of compression support and limitations:
- All formats except JPEG support 1 bpp binary.
- All formats support 8 bpp grayscale (GIF must have a colormap).
- All formats except GIF support 24 bpp rgb color.
- All formats except PNM support 8 bpp colormap.
- PNG and PNM support 2 and 4 bpp images.
- PNG supports 2 and 4 bpp colormap, and 16 bpp without colormap.
- PNG, JPEG, TIFF and GIF support image compression; PNM and BMP do not.
- WEBP supports 24 bpp rgb color.
C.提高圖片質量?
識別成功率跟圖片質量關係密切,一般拿到後的驗證碼都得經過灰度化,二值化,去噪,利用imgick就可以很方便的做到.
convert -monochrome foo.png bar.png #將圖片二值化
D.我只想識別字符和數字?
結尾僅需要加digits
命令例項:tesseract imagename outputbase digits
E.訓練你的tesseract
不得不說,tesseract英文識別率已經很不錯了(現有的tesseract-data-eng),但是驗證碼識別還是太雞肋了。但是請別忘記,tesseract的智慧識別是需要訓練的.
F.命令執行出現empty page!!錯誤
嚴格來說,這不是一個bug(tesseract 3.0),出現這個錯誤是因為tesseract搞不清影象的字元佈局
訓練時出現的問題
錯誤1:
編譯下面兩句的時候
shapeclustering -F font_properties -U unicharset eng.timesitalic.exp0.tr
mftraining -F font_properties -U unicharset -O eng.unicharset eng.timesitalic.exp0.tr
出現錯誤: No shape table file present: shapetable Reading num.tr …Font id = -1/0, class id = 1/13 on sample
0font_id >= 0 && font_id < font_id_map_.SparseSiz
..\..\classify\trainingsampleset.cpp, line 622
原因:主要出在font_properties.txt這個檔案的配置上。
內容為:黑體 0 0 0 0 0 正確