
基於spark執行scala程式(sbt和命令列方法)
在前面搭建好scala和spark的開發環境之後,迫不及待地想基於spark執行一下scala程式,於是找到了spark官方網站的連結(http://spark.apache.org/docs/latest/quick-start.html),介紹如何執行scala程式。現將具體的操作步驟詳細介紹如下。
連結中給出了一個SimpleApp.scala的例程,我們通過比較各種編輯器發現sublime text這個編輯器對scala語言有高亮功能,易於程式碼閱讀,如下圖所示。

此段程式主要功能通過兩個job並行分析spark自帶的README.md檔案中包含a和b字母分別有多少行。
另外我們還需要建立一個simple.sbt檔案,來加入spark庫依賴,scala程式執行的時候便可以呼叫spark庫。
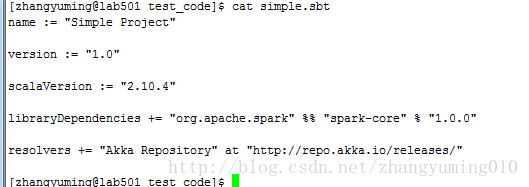
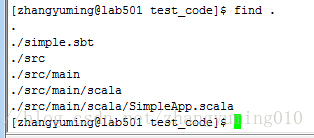
建立好simple.sbt檔案後,由於需要對整個工程進行打包成jar檔案才能執行,官網建議使用sbt(simple buildtool)這個工具對整個工程進行打包,而sbt對工程的目錄有一定的要求,如下圖所示建立好工程目錄。
由於sbt工具並不是linux自帶的軟體,因此還需要安裝,我這裡由於安裝sbt的時候是在linux電腦上直接安裝的,不方便截圖,因此不做過多說明,安裝好了sbt工具後,執行sbt package命令(電腦需要聯網),電腦會分析工程自行下載一些其他需要的檔案,然後將檔案打包,在我的電腦上在下圖所示的目錄中會生成simple-project_2.10-1.0.jar的包。

這個時候執行spark-submit命令並附帶一些引數便可得到結果。


我們看到包含a的行數為73行,包含b的行數為35行。
後面我發現對於MLlib的例程程式碼(http://spark.apache.org/docs/latest/mllib-linear-methods.html#logistic-regression),通過上面的方式貌似不可行,也即會編譯報錯,結合對linux命令列的認識,通過命令列執行了MLlib的例程,如下圖所示。

通過cat 和管道命令,將程式輸入到 spark-shell中,便可以順利執行了,如下圖。
