
新AlphaGo首度揭祕:單機執行,4個TPU,演算法更強
到底是誰擊敗了柯潔?
答案似乎顯而易見。但量子位之所以問這個問題,是因為如今擊敗柯潔的AlphaGo,與去年擊敗李世乭的AlphaGo,有著本質的區別。
DeepMind把AlphaGo粗略分成幾個版本:
-
第一代,是擊敗樊麾的AlphaGo Fan。與Zen/Crazy Stone等之前的圍棋軟體相比,棋力要高出4子。
-
第二代,是擊敗李世乭的AlphaGo Lee。與上一代相比,棋力高出3子。
-
第三代,是柯潔如今的對手,也是年初60連勝的:AlphaGo Master。相比於擊敗李世乭的版本,棋力又再次提升3子。
需要強調的是,AlphaGo Lee和AlphaGo Master有著根本不同。不同在哪裡,今天DeepMind創始人兼CEO哈薩比斯(Demis Hassabis),AlphaGo團隊負責人席爾瓦(Dave Silver)聯手首度揭開新版AlphaGo的祕密。
量子位這一篇推送的內容,整理自哈薩比斯、席爾瓦今日上午的主題演講,還有今日午間量子位對這兩位DeepMind核心人物的專訪。
單TPU運算,更強的策略/價值網路
首先用資料說話。
AlphaGo Lee

-
運行於谷歌雲,耗用50個TPU進行計算
-
每次搜尋計算後續50步,計算速度為10000個位置/秒
-
2016年在首爾擊敗李世乭
作為對比,20年前擊敗卡斯帕羅夫的IBM深藍,可以搜尋計算一億個位置。席爾瓦表示,AlphaGo並不需要搜尋那麼多位置。
AlphaGo Master

-
運行於谷歌雲,但只用一個TPU機器
-
自學成才,AlphaGo自我對弈提高棋力
-
擁有更強大的策略/價值網路
由於應用了更高效的演算法,這次和柯潔對戰的AlphaGo Master,運算量只有上一代AlphaGo Lee的十分之一。所以單個TPU機器足以支撐。
AlphaGo團隊的黃士傑博士也在朋友圈表示,最新的AlphaGo可以被稱為單機版。而上一代AlphaGo使用了分散式計算。
在會後接受量子位採訪時,席爾瓦證實此次AlphaGo仍然使用了第一代TPU,而不是前不久公佈的第二代。
另外席爾瓦澄清說:“今年升級版的AlphaGo是在單機上執行的,它的物理伺服器上部署了4個TPU”。
顯然PPT有個小小的誤導。
如果你想更進一步瞭解TPU,這裡有幾篇量子位的報道推薦:
回到AlphaGo,可能你也注意到了,這個新版本的圍棋AI有了更強大的策略/價值網路。下面圍繞這一點繼續解密。

△席爾瓦 AlphaGo的演算法
為了講清楚新的策略/價值網路強在哪裡,還是應該首先介紹一下AlphaGo的演算法如何構成。席爾瓦介紹,量子位搬運如下。
當初DeepMind團隊,之所以選擇圍棋方向進行研究,一個重要的原因在於圍棋是構建和理解運算的最佳試驗檯,而且圍棋的複雜性遠超國際象棋,這讓電腦無法通過深藍一樣的暴力窮舉方式破解圍棋的奧祕。
擊敗李世乭的AlphaGo,核心是一個卷積神經網路。DeepMind團隊希望AlphaGo最終能夠理解圍棋,形成全域性觀。席爾瓦表示,AlphaGo Lee由12層神經網路構成,而AlphaGo Master有40層神經網路。
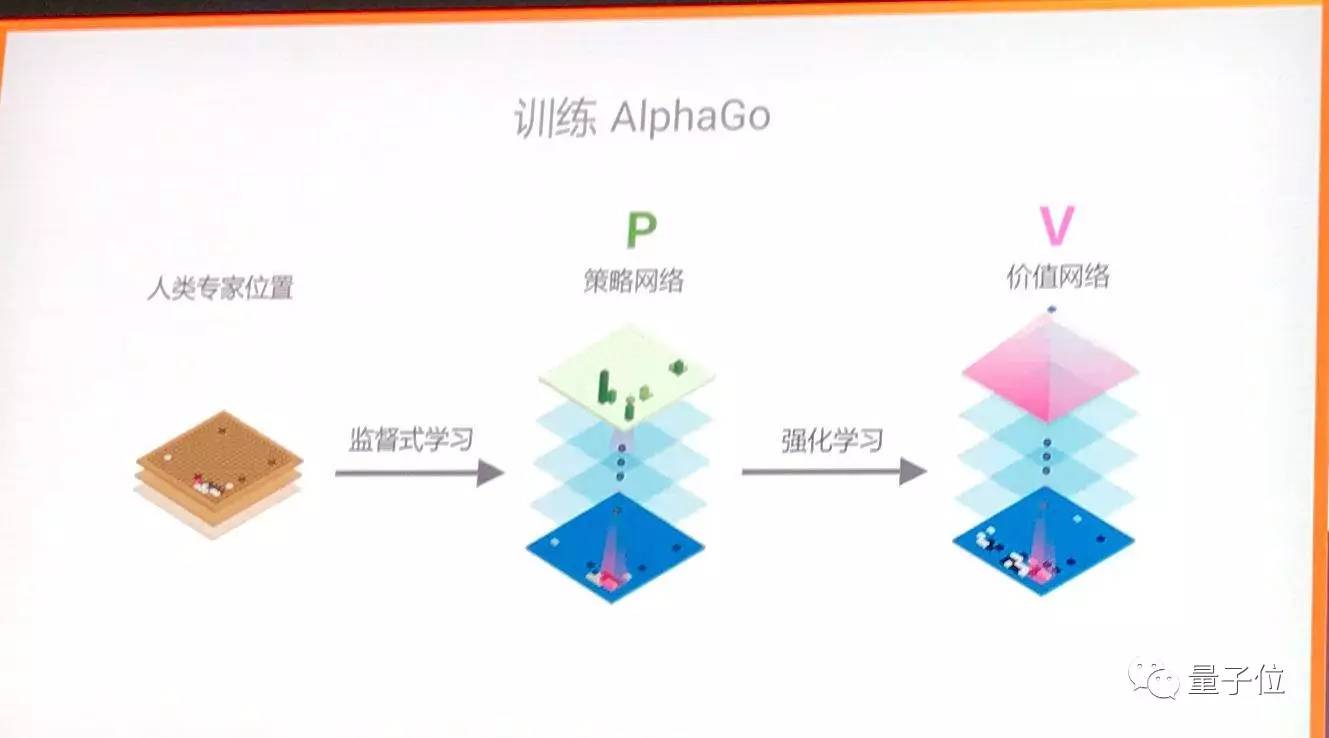
這些神經網路進一步細分為兩個功能網路:
-
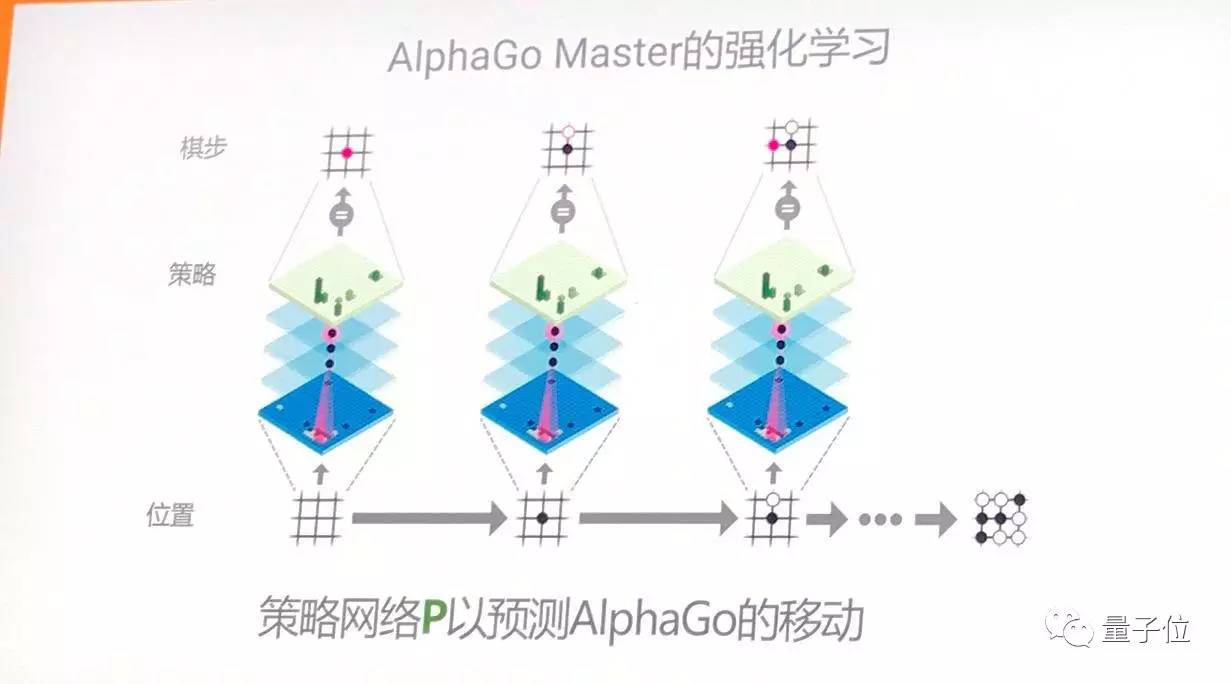
策略網路(policy network)
-
價值網路(value network)
在這兩個網路的訓練中,使用了監督學習和強化學習兩種方式。
首先基於人類的專家庫資料,對策略網路的上百萬引數進行調整。調整的目標,是讓策略網路在相同的情況下,能夠達到人類圍棋高手的水平:下出同樣的一步棋。
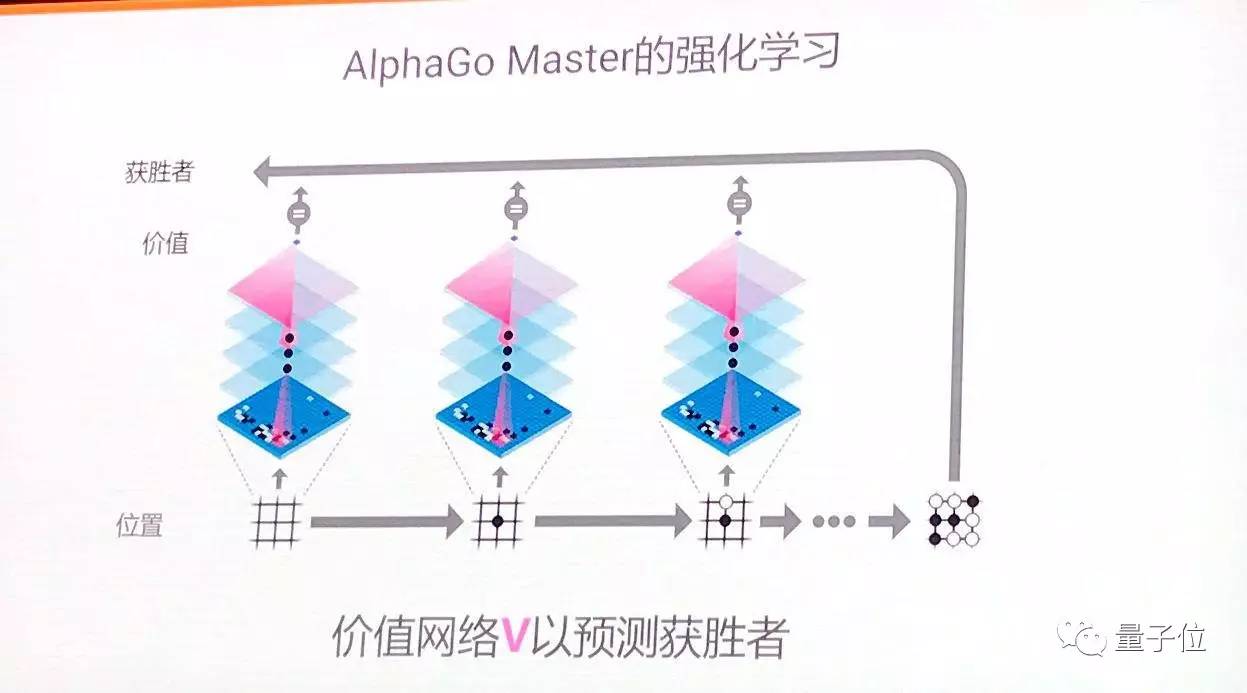
然後是強化學習,讓人工智慧進行自我博弈,這一訓練結束後,就形成了價值網路,這被用於對未來的棋局輸贏進行預測,在不同的下法中作出優劣判斷。
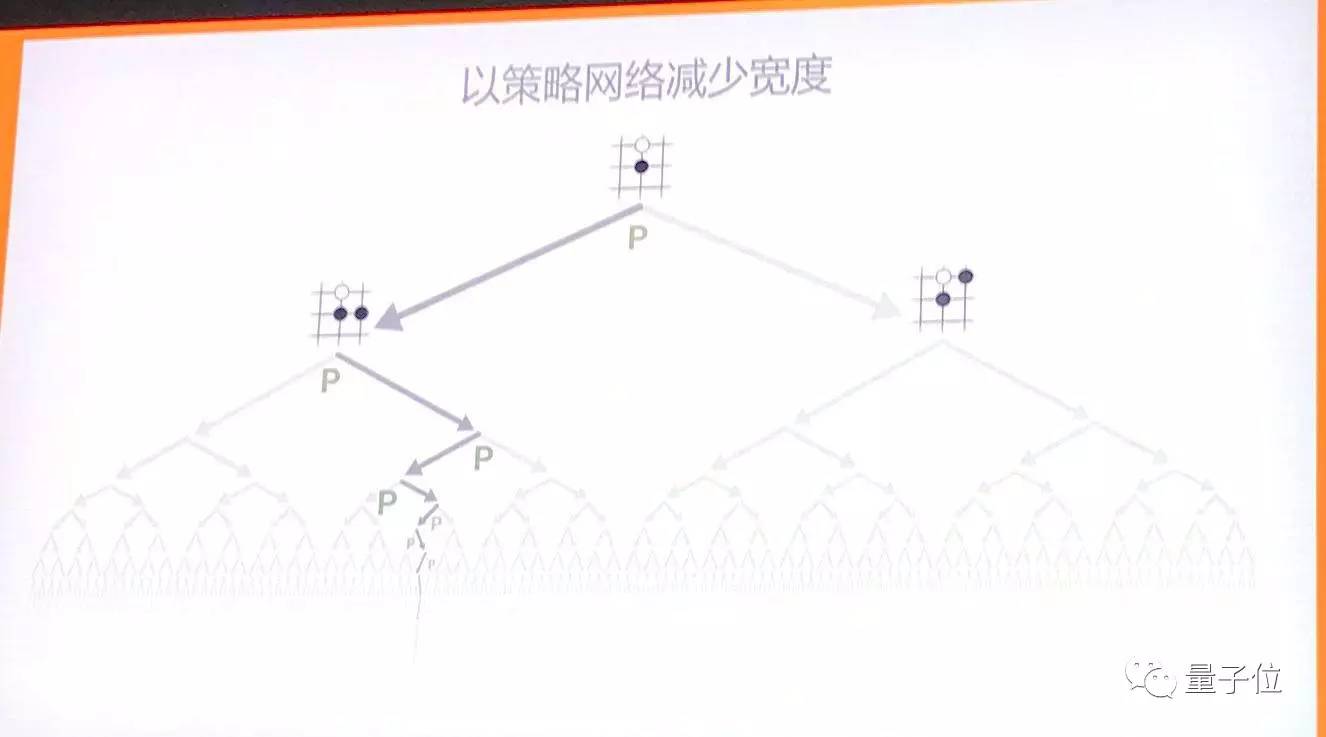
通過策略網路,可以降低搜尋的寬度,減少候選項,收縮複雜性。而且不會讓AlphaGo下出瘋狂不靠譜的步驟。
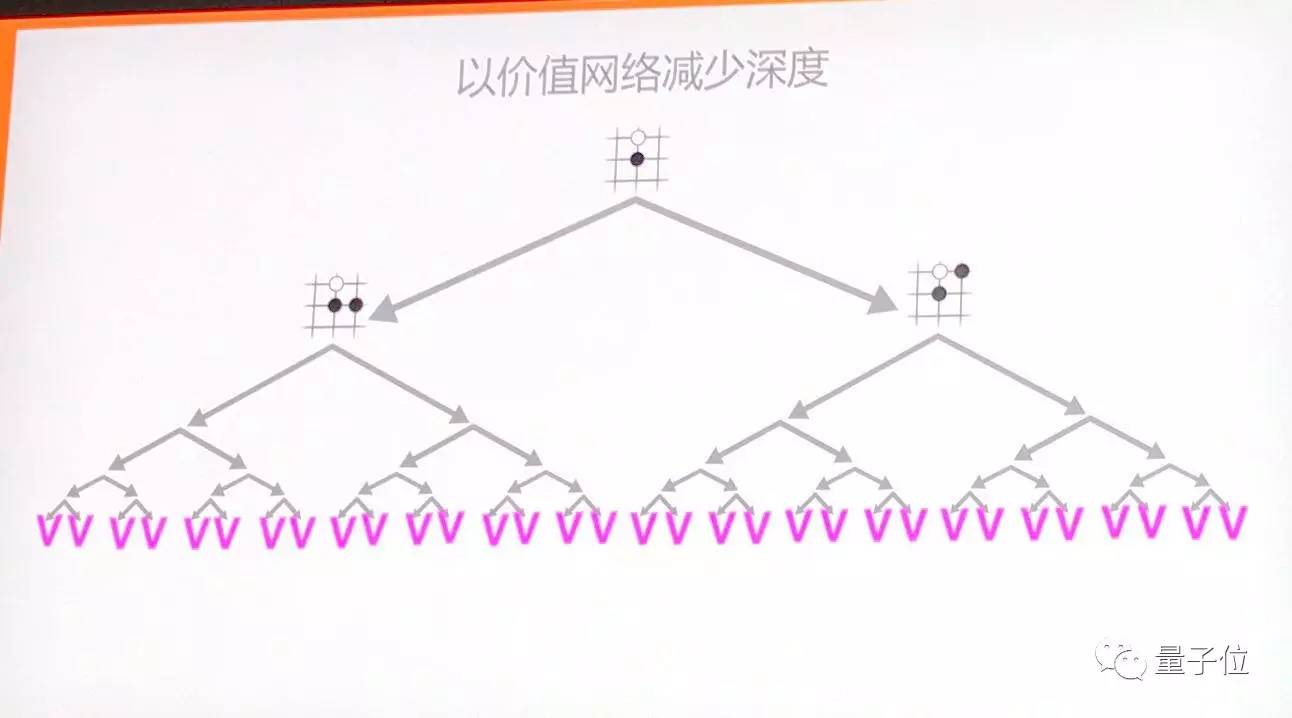
另一方面,通過價值網路減少深度,當AlphaGo計算到一定的深度,就會停止。AlphaGo不需要一直窮盡到最後。
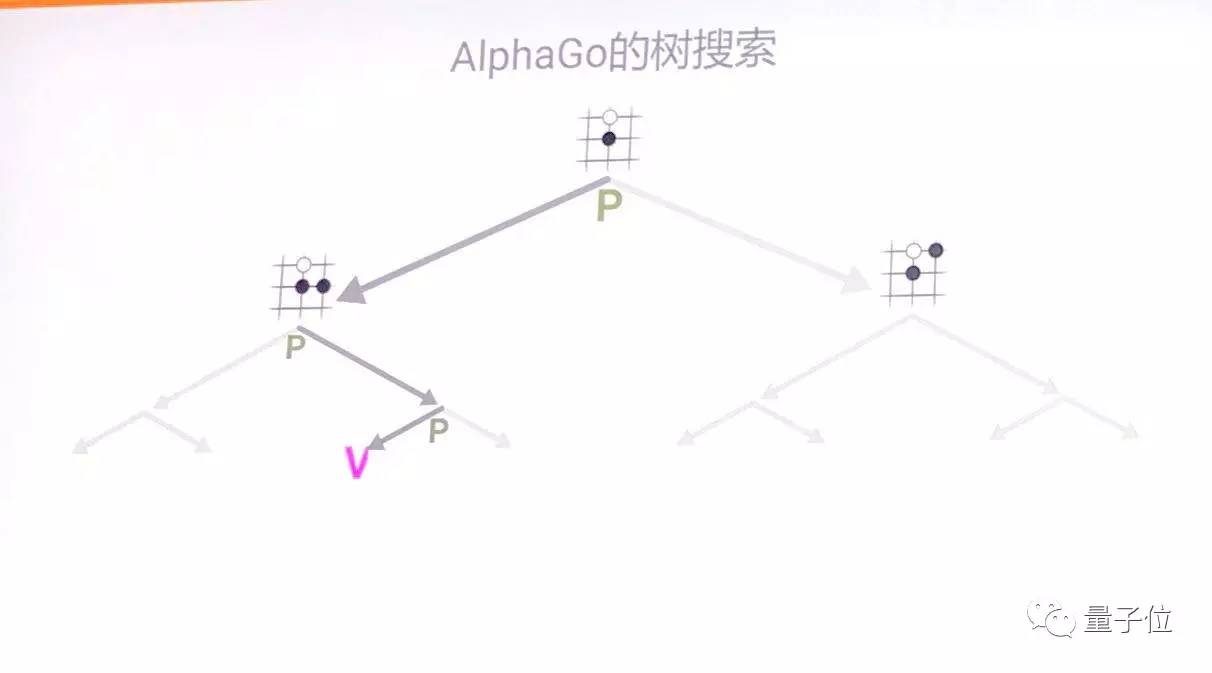
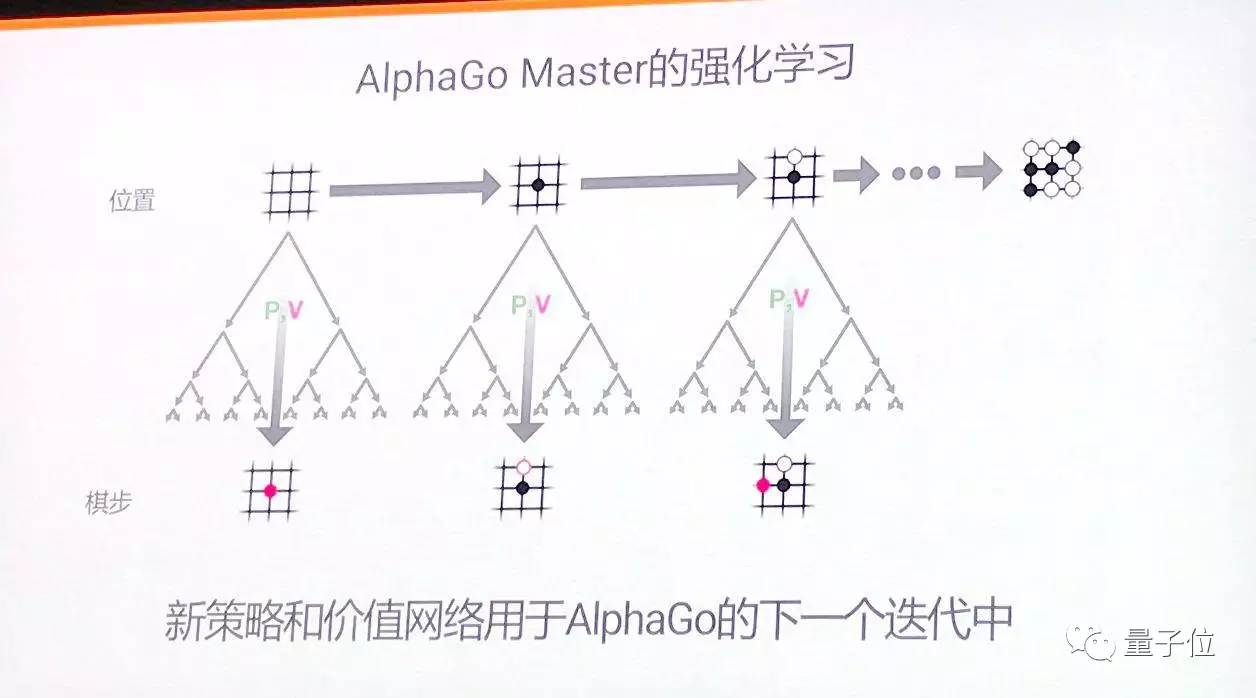
把這個兩個結合起來,就是AlphaGo的樹搜尋。通過策略網路選出幾個可能的路徑,然後對這些路徑進行評估,最後把結果提交給樹頂。這個過程重複幾百上千次,最後AlphaGo得出贏棋概率最高的一步。
新策略/價值網路如何煉成
那麼新的新策略/價值網路,到底強在哪裡?
AlphaGo Master這次成了自己的老師,用席爾瓦的話說,這位圍棋AI是自學成才。它從自我對弈的棋局裡進行學習,積累了最好的訓練資料。“上一代AlphaGo成為下一代的老師”席爾瓦形容道。
通過AlphaGo的自我博弈,不斷吸取經驗、提高棋力,這一次AlphaGo用自我對弈訓練出的策略網路,可以做到不需要更多運算,直接給出下一步的決策。
這種改變明顯減少了對計算力的需求。
另一個價值網路,也是基於AlphaGo的自我對弈進行訓練,通過對弈後的覆盤,價值網路能夠學到哪一步是關鍵所在。通過高質量的自我對弈,訓練價值網路預測哪一步更重要。
席爾瓦表示:“在任何一步,AlphaGo都會準確預測如何能贏”。
這個過程不斷反覆迭代,最終打造了一個更強大的AlphaGo。自我博弈,帶來資料質量的提高,從而推動了AlphaGo的快速提升。
如此前一樣,DeepMind證實也會公佈這一代AlphaGo的相關論文。更多的細節,我們可以期待Deepm稍後的釋出。
攻克智慧,解決問題
AlphaGo來自DeepMind。2010年DeepMind在倫敦成立,目前有500名員工,其中一半是科學家。哈薩比斯說,DeepMind要把人工智慧科學家、資料和計算力結合在一起,推動人工智慧的發展。

△哈薩比斯
這家公司的願景:第一是攻克智慧。第二是用智慧解決所有問題。
換句話說,DeepMind的目標是構建通用人工智慧。所謂通用人工智慧,首先AI具備學習的能力,其次能舉一反三,執行各種不同的任務。如何抵達這個目標?哈薩比斯說有兩個工具:深度學習、強化學習。
AlphaGo就是深度學習和強化學習的結合。AlphaGo也是DeepMind邁向通用人工智慧目標的一步,儘管現在它更多的專注於圍棋領域。
哈薩比斯表示,希望通過AlphaGo的研究,讓機器獲得直覺和創造力。
這裡所謂的直覺,是通過體驗直接獲得的初步感知。無法表達出來,可通過行為確認其存在和正誤。
而創造力,是通過組合已有知識產生新穎或獨特想法的能力。AlphaGo顯然已展示出了這些能力,儘管領域有限。
“未來能夠看到人機結合的巨大力量,人類智慧將被人工智慧放大。”哈薩比斯說。目前AlphaGo的技術已經被用於資料中心,能節約15%的電能;另外也能被用於材料、醫療、智慧手機和教育等領域。
儘管已經連戰連捷,AlphaGo仍然有繼續探索的空間。哈薩比斯和DeepMind仍然想在圍棋領域繼續追問:我們離最優解還有多遠?怎樣才是完美棋局?
當今社會已有越來越多的資料產生,然而人類往往無法通過這些資料瞭解全域性的變化,在這種情況下人工智慧有可能推動科研繼續進步。
一切正如國際象棋棋王卡斯帕羅夫所說:
“深藍已經結束,AlphaGo才剛開始。”
專訪全文

△哈薩比斯、席爾瓦接受量子位等專訪
提問:在Master已經對包括柯潔在內的人類棋手60連勝之後,舉辦這場比賽的意義在哪裡?
哈薩比斯:Master在網上下的都是快棋,人類棋手在下棋時時間控制得可能不會太精準,人類棋手在網上的注意力也不一定完全集中,因此我們仍然需要跟柯潔進行對弈來對AlphaGo進行測試。
同時,通過這些網上的對弈,第一,是希望測試一下AlphaGo的系統;第二,也是希望為圍棋界提供一些新的想法和思路,給柯潔一定備戰的時間,也為他提供一些分析AlphaGo打法的素材。
提問:關於AlphaGo的行業應用,有哪些您比較看好?今後Deepmind會不會在中國開展一些行業應用?
哈薩比斯:首先,AlphaGo背後的支撐技術相當多,目前在其他領域的應用還在早期探索階段。我上午談到的一些應用,只是AlphaGo圍棋可能應用中的一小部分。在未來,我們肯定會將AlphaGo的技術在Google領域的應用,也許在中國也會有相應的業務。
提問:AlphaGo是否已經實現了無監督學習?它是否在向著強人工智慧邁進?
席爾瓦:首先,AlphaGo使用的是增強學習的方法。我們只能說,AlphaGo在某一特定領域實現了自己的直覺和意識——這和我們所說的人類通過直接訓練產生的意識可能有很大不同。因為它並非這種人類意識,因此有機會被應用到其他領域,不僅限於圍棋。
提問:Hassabis先生上午提到,人工智慧必須要被正確應用。那麼這種“正確”包括哪些原則?
哈薩比斯:兩個層面。第一,AI必須造福人類,應該用於類似科學、製藥這類幫助人類的領域,而不能用於一些不好的事情,比如研發武器;第二,AI不能只為少數公司或個人所使用、,它應該是全人類共享的。
提問:上午的演講中兩位提到,這一代AlphaGo只需要一個TPU進行運算,而上一代和李世石對戰時的AlphaGo則部署了50個TPU;但這代系統所需的計算量只是上一代的十分之一。為什麼會出現這種比例上的差距?
席爾瓦:我來澄清一下。今年升級版的AlphaGo是在單機上執行的,它的物理伺服器上部署了4個TPU。
提問:為什麼AlphaGo下棋是勻速的?
席爾瓦:我們在對AlphaGo訓練時就已經發現,它在對弈時進行的計算是持續的、穩定的,在總共的比賽過程中,它的計算量是恆定的。我們為AlphaGo制定了一種求穩的時間控制策略,也就是最大限度地利用自己的比賽時間,如果要將比賽時間的利用率最大化,勻速當然是最好的。

△穆斯塔法等接受量子位等專訪
提問:圍棋相對簡單,AI在現實中應用,有哪些阻礙?
穆斯塔法:我們對此有過深入思考,DeepMind創立的使命中指出,我們要打造通用型的人工智慧技術,並接受相應的監督監管。此前我們和眾多的機構共同成立AI聯盟,以遵循倫理和安全的方式,進行演算法的開發。
提問:技術落地過程中,如何避免侵犯隱私?
穆斯塔法:新技術的部署應用過程中,確實出現了跟監督監管機制不匹配的情況,現在科技的力量已經非常強大,在這種情況下,技術快速發展。所謂的數字化技術或裝置進行平衡,是我們不斷推進的事情。
我們希望加強醫生患者對技術的信任,第一是展示臨床使用的效果,第二我們一開始就公開表示,系統處理的資料,完全在監管範圍之內,不會應用到其他業務之中。
提問:DeepMind目前是什麼結構?
穆斯塔法:DeepMind分為兩個結構,哈薩比斯負責研發,我負責商業應用。應用又分成三個組:1、Google組 2、醫療組,和英國NHS合作 3、馬上要成立的能源組。我們希望與專家合作,獲取必要的資料。
我們和Google不同部門合作,有不同的形式。
提問:為什麼先把AI應用在醫療領域?而不是金融等
穆斯塔法:商業利潤不是我們最重要的驅動力。我們選擇行業從兩點出發:首先,是否有助於技術研究;其次,是否有助於完成社會使命。
醫療行業季度的低效,技術停滯不前已經很久。
提問:一手研發,一手商業化,有沒有隱藏的技術細節?
穆斯塔法:我們儘量多在開源的時候,提供有助於別人的資料。當然,我們不是100%都公佈技術細節。當然我們會盡量多的做開源。
提問:驅動AI應用的資料是否足夠,以及是所需要的資料?
穆斯塔法:我們做過一個統計。世界上,最優秀的放射科專家,一生也就看三萬張X光照片,我們的演算法可以看幾百萬張,能夠開發出疑難雜症的意識和本能。我們能夠對演算法增強準確率,表現非常穩定。
人類專家看X光片,可能只有三分之二的共識達成。所以我們的想法是,用演算法做X光片,然後配上不同的疾病專家,這樣效果更好。