
hadoop詳細瞭解5個程序的作用
阿新 • • 發佈:2019-02-13
轉載原文地址:http://www.aboutyun.com/thread-7088-1-1.html
問題導讀:
1.job的本質是什麼?
2.任務的本質是什麼?
3.檔案系統的Namespace由誰來管理,Namespace的作用是什麼?
4.Namespace 映象檔案(Namespace image)和操作日誌檔案(edit log)檔案的作用是什麼?
5.Namenode記錄著每個檔案中各個塊所在的資料節點的位置資訊,但是他並不持久化儲存這些資訊,為什麼?
6.客戶端讀寫某個資料時,是否通過NameNode?
7.namenode,datanode,Namespace image,Edit log之間的關係是什麼?
8.一旦某個task失敗了,JobTracker如何處理?
9.JobClient JobClient在獲取了JobTracker為Job分配的id之後,會在JobTracker的系統目錄(HDFS)下為該Job建立一個單獨的目錄,目錄的名字即是Job的id,該目錄下
會包含檔案job.xml、job.jar等檔案,這兩個檔案的作用是什麼?
10.JobTracker根據什麼就能得到這個Job目錄?
11.JobTracker提交作業之前,為什麼要檢查記憶體?
12.每個TaskTracker產生多個java 虛擬機器(JVM)的原因是什麼?
概述:
Hadoop是一個能夠對大量資料進行分散式處理的軟體框架,實現了Google的MapReduce程式設計模型和框架,能夠把應用程式分割成許多的 小的工作單元,並把這些單元放到任何叢集節點上執行。在MapReduce中,一個準備提交執行的應用程式稱為“作業(job)”,而從一個作業劃分出 得、運行於各個計算節點的工作單元稱為“任務(task)”。此外,Hadoop提供的分散式檔案系統(HDFS)主要負責各個節點的資料儲存,並實現了 高吞吐率的資料讀寫。
在分散式儲存和分散式計算方面,Hadoop都是用從/從(Master/Slave)架構。在一個配置完整的叢集上,想讓Hadoop這頭大 象奔跑起來,需要在叢集中執行一系列後臺(deamon)程式。不同的後臺程式扮演不用的角色,這些角色由NameNode、DataNode、 Secondary NameNode、JobTracker、TaskTracker組成。其中NameNode、Secondary NameNode、JobTracker執行在Master節點上,而在每個Slave節點上,部署一個DataNode和TaskTracker,以便 這個Slave伺服器執行的資料處理程式能儘可能直接處理本機的資料。對Master節點需要特別說明的是,在小叢集中,Secondary NameNode可以屬於某個從節點;在大型叢集中,NameNode和JobTracker被分別部署在兩臺伺服器上。
我們已經很熟悉這個5個程序,但是在使用的過程中,我們經常遇到問題,那麼該如何入手解決這些問題。那麼首先我們需瞭解的他們的原理和作用。
1.Namenode介紹
Namenode 管理者檔案系統的Namespace。它維護著檔案系統樹(filesystem tree)以及檔案樹中所有的檔案和資料夾的元資料(metadata)。管理這些資訊的檔案有兩個,分別是Namespace 映象檔案(Namespace image)和操作日誌檔案(edit log),這些資訊被Cache在RAM中,當然,這兩個檔案也會被持久化儲存在本地硬碟。Namenode記錄著每個檔案中各個塊所在的資料節點的位置資訊,但是他並不持久化儲存這些資訊,因為這些資訊會在系統啟動時從資料節點重建。
Namenode結構圖課抽象為如圖:
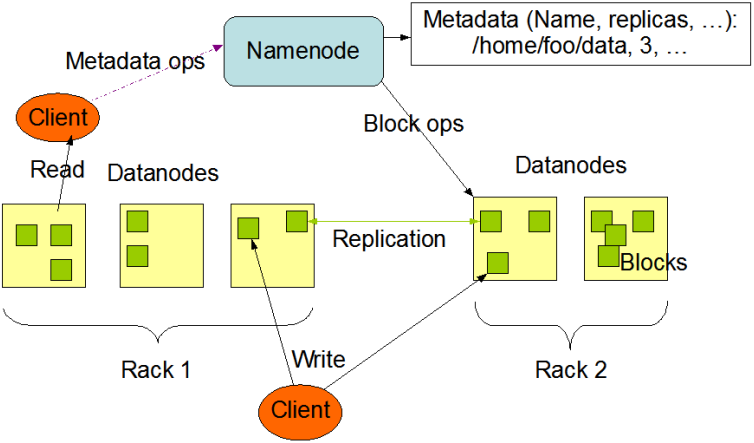
客戶端(client)代表使用者與namenode和datanode互動來訪問整個檔案系統。客戶端提供了一些列的檔案系統介面,因此我們在程式設計時,幾乎無須知道datanode和namenode,即可完成我們所需要的功能。
1.1Namenode容錯機制
沒有Namenode,HDFS就不能工作。事實上,如果執行namenode的機器壞掉的話,系統中的檔案將會完全丟失,因為沒有其他方法能夠將位於不同datanode上的檔案塊(blocks)重建檔案。因此,namenode的容錯機制非常重要,Hadoop提供了兩種機制。
第一種方式是將持久化儲存在本地硬碟的檔案系統元資料備份。Hadoop可以通過配置來讓Namenode將他的持久化狀態檔案寫到不同的檔案系統中。這種寫操作是同步並且是原子化的。比較常見的配置是在將持久化狀態寫到本地硬碟的同時,也寫入到一個遠端掛載的網路檔案系統。
第二種方式是執行一個輔助的Namenode(Secondary Namenode)。 事實上Secondary Namenode並不能被用作Namenode它的主要作用是定期的將Namespace映象與操作日誌檔案(edit log)合併,以防止操作日誌檔案(edit log)變得過大。通常,Secondary Namenode 執行在一個單獨的物理機上,因為合併操作需要佔用大量的CPU時間以及和Namenode相當的記憶體。輔助Namenode儲存著合併後的Namespace映象的一個備份,萬一哪天Namenode宕機了,這個備份就可以用上了。
但是輔助Namenode總是落後於主Namenode,所以在Namenode宕機時,資料丟失是不可避免的。在這種情況下,一般的,要結合第一種方式中提到的遠端掛載的網路檔案系統(NFS)中的Namenode的元資料檔案來使用,把NFS中的Namenode元資料檔案,拷貝到輔助Namenode,並把輔助Namenode作為主Namenode來執行。
----------------------------------------------------------------------------------------------------------------------------------------------------
2、Datanode介紹
Datanode是檔案系統的工作節點,他們根據客戶端或者是namenode的排程儲存和檢索資料,並且定期向namenode傳送他們所儲存的塊(block)的列表。 叢集中的每個伺服器都執行一個DataNode後臺程式,這個後臺程式負責把HDFS資料塊讀寫到本地的檔案系統。當需要通過客戶端讀/寫某個 資料時,先由NameNode告訴客戶端去哪個DataNode進行具體的讀/寫操作,然後,客戶端直接與這個DataNode伺服器上的後臺程式進行通 信,並且對相關的資料塊進行讀/寫操作。
---------------------------------------------------------------------------------------------------------------------------------------------------
3、Secondary NameNode介紹
Secondary NameNode是一個用來監控HDFS狀態的輔助後臺程式。就想NameNode一樣,每個叢集都有一個Secondary NameNode,並且部署在一個單獨的伺服器上。Secondary NameNode不同於NameNode,它不接受或者記錄任何實時的資料變化,但是,它會與NameNode進行通訊,以便定期地儲存HDFS元資料的 快照。由於NameNode是單點的,通過Secondary NameNode的快照功能,可以將NameNode的宕機時間和資料損失降低到最小。同時,如果NameNode發生問題,Secondary NameNode可以及時地作為備用NameNode使用。
3.1NameNode的目錄結構如下:
${dfs.name.dir}/current/VERSION /edits /fsimage /fstime
3.2Secondary NameNode的目錄結構如下:
${fs.checkpoint.dir}/current/VERSION /edits /fsimage /fstime /previous.checkpoint/VERSION /edits /fsimage /fstime

如上圖,Secondary NameNode主要是做Namespace image和Edit log合併的。
那麼這兩種檔案是做什麼的?當客戶端執行寫操作,則NameNode會在edit log記錄下來,(我感覺這個檔案有些像Oracle的online redo logo file)並在記憶體中儲存一份檔案系統的元資料。
Namespace image(fsimage)檔案是檔案系統元資料的持久化檢查點,不會在寫操作後馬上更新,因為fsimage寫非常慢(這個有比較像datafile)。
由於Edit log不斷增長,在NameNode重啟時,會造成長時間NameNode處於安全模式,不可用狀態,是非常不符合Hadoop的設計初衷。所以要週期性合併Edit log,但是這個工作由NameNode來完成,會佔用大量資源,這樣就出現了Secondary NameNode,它可以進行image檢查點的處理工作。步驟如下: (1) Secondary NameNode請求NameNode進行edit log的滾動(即建立一個新的edit log),將新的編輯操作記錄到新生成的edit log檔案; (2) 通過http get方式,讀取NameNode上的fsimage和edits檔案,到Secondary NameNode上; (3) 讀取fsimage到記憶體中,即載入fsimage到記憶體,然後執行edits中所有操作(類似OracleDG,應用redo log),並生成一個新的fsimage檔案,即這個檢查點被建立; (4) 通過http post方式,將新的fsimage檔案傳送到NameNode; (5) NameNode使用新的fsimage替換原來的fsimage檔案,讓(1)建立的edits替代原來的edits檔案;並且更新fsimage檔案的檢查點時間。 整個處理過程完成。 Secondary NameNode的處理,是將fsimage和edites檔案週期的合併,不會造成nameNode重啟時造成長時間不可訪問的情況。
--------------------------------------------------------------------------------------------------------------------------------------------------
4、JobTracker介紹
JobTracker後臺程式用來連線應用程式與Hadoop。使用者程式碼提交到叢集以後,由JobTracker決定哪個檔案將被處理,並且為 不同的task分配節點。同時,它還監控所有的task,一旦某個task失敗了,JobTracker就會自動重新開啟這個task,在大多數情況下這 個task會被放在不用的節點上。每個Hadoop叢集只有一個JobTracker,一般執行在叢集的Master節點上。
下面我們詳細介紹:
4.1JobClient
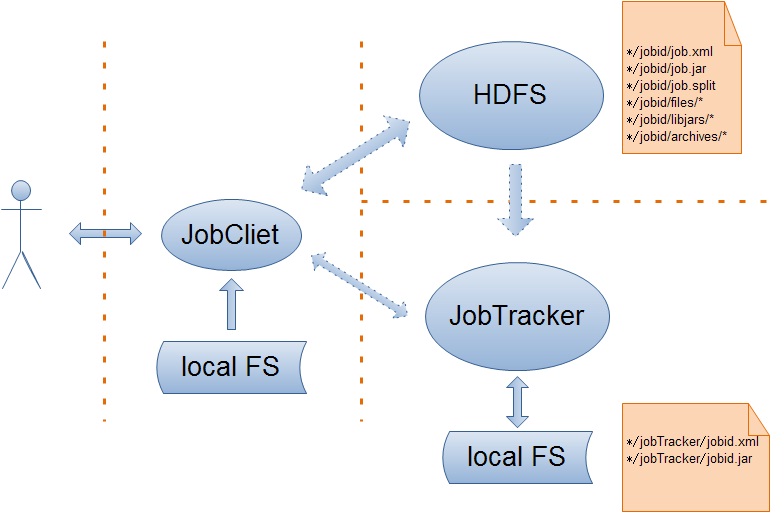
我們配置好作業之後,就可以向JobTracker提交該作業了,然後JobTracker才能安排適當的TaskTracker來完成該作業。那麼MapReduce在這個過程中到底做了那些事情呢?這就是本文以及接下來的一片博文將要討論的問題,當然本文主要是圍繞客戶端在作業的提交過程中的工作來展開。先從全域性來把握這個過程吧!

在Hadoop中,作業是使用Job物件來抽象的,對於Job,我首先不得不介紹它的一個大傢伙JobClient——客戶端的實際工作者。JobClient除了自己完成一部分必要的工作外,還負責與JobTracker進行互動。所以客戶端對Job的提交,絕大部分都是JobClient完成的,從上圖中,我們可以得知JobClient提交Job的詳細流程主要如下:

JobClient在獲取了JobTracker為Job分配的id之後,會在JobTracker的系統目錄(HDFS)下為該Job建立一個單獨的目錄,目錄的名字即是Job的id,該目錄下會包含檔案job.xml、job.jar、job.split等,其中,job.xml檔案記錄了Job的詳細配置資訊,job.jar儲存了使用者定義的關於job的map、reduce操縱,job.split儲存了job任務的切分資訊。在上面的流程圖中,我想詳細闡述的是JobClient是任何配置Job的執行環境,以及如何對Job的輸入資料進行切分。
4.2JobTracker
上面談到了客戶端的JobClient對一個作業的提交所做的工作,那麼這裡,就要好好的談一談JobTracker為作業的提交到底幹了那些個事情——一.為作業生成一個Job;二.接受該作業。
我們都知道,客戶端的JobClient把作業的所有相關資訊都儲存到了JobTracker的系統目錄下(當然是HDFS了),這樣做的一個最大的好處就是客戶端幹了它所能幹的事情同時也減少了伺服器端JobTracker的負載。下面就來看看JobTracker是如何來完成客戶端作業的提交的吧!哦。對了,在這裡我不得不提的是客戶端的JobClient向JobTracker正式提交作業時直傳給了它一個改作業的JobId,這是因為與Job相關的所有資訊已經存在於JobTracker的系統目錄下,JobTracker只要根據JobId就能得到這個Job目錄。
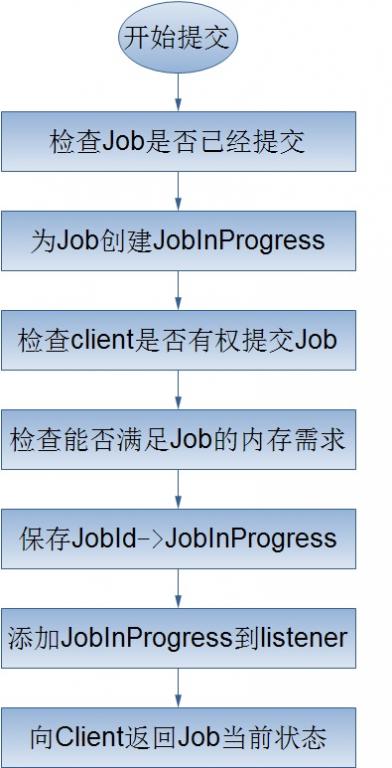
對於上面的Job的提交處理流程,我將簡單的介紹以下幾個過程:
1.建立Job的JobInProgress
JobInProgress物件詳細的記錄了Job的配置資訊,以及它的執行情況,確切的來說應該是Job被分解的map、reduce任務。在JobInProgress物件的建立過程中,它主要乾了兩件事,一是把Job的job.xml、job.jar檔案從Job目錄copy到JobTracker的本地檔案系統(job.xml->*/jobTracker/jobid.xml,job.jar->*/jobTracker/jobid.jar);二是建立JobStatus和Job的mapTask、reduceTask存佇列來跟蹤Job的狀態資訊。
2.檢查客戶端是否有許可權提交Job
JobTracker驗證客戶端是否有許可權提交Job實際上是交給QueueManager來處理的。
3.檢查當前mapreduce叢集能夠滿足Job的記憶體需求
客戶端提交作業之前,會根據實際的應用情況配置作業任務的記憶體需求,同時JobTracker為了提高作業的吞吐量會限制作業任務的記憶體需求,所以在Job的提交時,JobTracker需要檢查Job的記憶體需求是否滿足JobTracker的設定。
上面流程已經完畢,可以總結為下圖:
--------------------------------------------------------------------------------------------------------------------------
5、TaskTracker介紹
TaskTracker與負責儲存資料的DataNode相結合,其處理結構上也遵循主/從架構。JobTracker位於主節點,統領 MapReduce工作;而TaskTrackers位於從節點,獨立管理各自的task。每個TaskTracker負責獨立執行具體的task,而 JobTracker負責分配task。雖然每個從節點僅有一個唯一的一個TaskTracker,但是每個TaskTracker可以產生多個java 虛擬機器(JVM),用於並行處理多個map以及reduce任務。TaskTracker的一個重要職責就是與JobTracker互動。如果 JobTracker無法準時地獲取TaskTracker提交的資訊,JobTracker就判定TaskTracker已經崩潰,並將任務分配給其他 節點處理。
5.1TaskTracker內部設計與實現
Hadoop採用master-slave的架構設計來實現Map-Reduce框架,它的JobTracker節點作為主控節點來管理和排程使用者提交的作業,TaskTracker節點作為工作節點來負責執行JobTracker節點分配的Map/Reduce任務。整個叢集由一個JobTracker節點和若干個TaskTracker節點組成,當然,JobTracker節點也負責對TaskTracker節點進行管理。在前面一系列的博文中,我已經比較系統地講述了JobTracker節點內部的設計與實現,而在本文,我將對TaskTracker節點的內部設計與實現進行一次全面的概述。
TaskTracker節點作為工作節點不僅要和JobTracker節點進行頻繁的互動來獲取作業的任務並負責在本地執行他們,而且也要和其它的TaskTracker節點互動來協同完成同一個作業。因此,在目前的Hadoop-0.20.2.0實現版本中,對工作節點TaskTracker的設計主要包含三類元件:服務元件、管理元件、工作元件。服務元件不僅負責與其它的TaskTracker節點而且還負責與JobTracker節點之間的通訊服務,管理元件負責對該節點上的任務、作業、JVM例項以及記憶體進行管理,工作元件則負責排程Map/Reduce任務的執行。這三大元件的詳細構成如下:

下面來詳細的介紹這三類元件:
服務元件
TaskTracker節點內部的服務元件不僅用來為TaskTracker節點、客戶端提供服務,而且還負責向TaskTracker節點請求服務,這一類元件主要包括HttpServer、TaskReportServer、JobClient三大元件。
1.HttpServer
TaskTracker節點在其內部使用Jetty Web容器來開啟http服務,這個http服務一是用來為客戶端提供Task日誌查詢服務,二是用來提供資料傳輸服務,即在執行Reduce任務時是通過TaskTracker節點提供的該http服務來獲取屬於自己的map輸出資料。這裡需要詳細介紹的是與該服務相關的配置引數,叢集管理者可以通過TaskTracker節點的配置檔案來配置該服務地址和埠號,對應的配置項為:mapred.task.tracker.http.address。同時,為了能夠靈活的控制該該服務的吞吐量,管理者還可以設定該http服務的內部工作執行緒數量,對應的配置為:tasktracker.http.threads。
2.Task Reporter
TaskTracker節點在接收到JobTracker節點發送過來的Map/Reduce任務之後,會把它們交給JVM例項來執行,而自己則需要收集這些任務的執行進度資訊,這就使得Task在JVM例項中執行的時候需要不斷地向TaskTracker節點報告當前的執行情況。雖然TaskTracker節點和JVM例項在同一臺機器上,但是它們之間的程序通訊卻是通過網路I/O來完成的(此處並不討論這種通訊方式的效能),也就是TaskTracker節點在其內部開啟一個埠來專門為任務例項提供進度報告服務。該服務地址可以通過配置項mapred.task.tracker.report.address來設定,而服務內部的工作執行緒的數量取2倍於該TaskTracker節點上的Map/Reduce Slot數量中的大者。