
基於locust的效能測試優化
阿新 • • 發佈:2019-02-13
問題產生的背景
以往在測試web服務的效能時,使用的工具有loadrnner、tsung、locust、jmeter等。這些工具的基本思路都相同,在一個檔案裡面定義一個使用者所要發起的請求,之後交給工具來模擬多個使用者重複執行我們定義的行為,最後返回平均請求的響應時長。 近期在測試幾個web服務的效能時,發現了一個問題,就是當一個頁面需要載入多個介面的資料時,瀏覽器所發出的請求是併發的。雖然我們測試時,在檔案中定義了單個使用者索要發出的所有請求,但是進行效能測試時,對於一個測試使用者來說,所有的請求都是順序發出的。由此引出瞭如下兩個問題: a. 效能測試過程中工具所虛擬出來的使用者數,產生的壓力要小於實際環境下同等數量的真實使用者。b. 介面的平均響應時長,並不能用來評估頁面的載入時間。 一個頁面有兩個介面a b,我們模擬以一個使用者訪問了兩次,這個時候,以介面響應時長為維度的資料報告大致是如下形式:

如果以平均響應最慢的那個介面來評估,那麼可以說頁面的平均載入時間是3.5s。
但是實際上,第一次訪問時,介面a b,最大的響應時長是5s,這個時候頁面的載入時間是5s。第二次訪問時間是4s。那麼平均的頁面響應時間應該是4.5s。4.5s和3.5s之間的差距,在效能測試中還是無法忽略的,在資料波動較大的情況下可能會出現更極端的結果。
解決辦法
b. 另外一種比較完美的解決方法就是我們自己實現一個html&js解析器,完全模擬瀏覽器的行為。不過這種方式實現難度較大,且效能測試時,高併發環境下要執行那麼多的解析器,資源消耗也是一個很大的問題。
c. 最後一種解決方案,就是利用現有的效能測試工具,修改內部任務排程方式,修改任務統計時間邏輯。把每個使用者下的任務改為併發執行,時間統計為所有任務全部執行完畢的時間,作為一次單個事件進行統計。
基於locust進行效能測試優化
簡單介紹一下locust內部各個程式碼檔案的功能:
Runners.py
主要實現虛擬使用者的排程,叢集方案下與slave通訊,根據壓力配置建立對應數量的虛擬使用者,並實現測試任務的啟動、停止等操 作。
Core.py
定義虛擬使用者,每個虛擬使用者在執行時所執行的任務以及任務排程都在這個檔案中完成。其中ClassTaskSet主要實現每個使用者下任務的排程功能。後續我們修改併發執行任務時,也是主要修改這裡的程式碼。
Stats.py
用於維護任務中每個請求的具體資訊,包括平均響應時長、最大最小響應時長、請求個數、頻率燈、等資訊。執行時RequestStats類會為每個請求都建立一個StatsEntry例項,後續所有該請求所產生的資料都由這個例項來維護。
Clients.py
主要用來重寫requests中一些類和函式,方便測試web介面時呼叫。
Main.py
入口檔案,解析使用者自定義的檔案,解析命令列引數等。
Web.py
Locust執行時的web介面,實現前後臺互動。後續增加統計資料型別時,需要修改此檔案。
- core.py, 修改run函式中的迴圈內容,增加execute_tasks函式,修改execute_task函式以及其它一些函式。主要是將原來的順序執行任務,改為一次性併發執行多個任務。
def run(self, *args, **kwargs):
.....
.....
while (True):
try:
.....
self.schedule_task()
try:
self.execute_tasks()
except RescheduleTaskImmediately:
pass
self.wait()
except InterruptTaskSet as e:
.....
def execute_tasks(self):
start_time = round(time()*1000,0)
self._task_pool = Group()
for task in self._task_queue:
self.execute_task(task["callable"], *task["args"], **task["kwargs"])
self._task_pool.join()
end_time = round(time()*1000,0)
jobtime = end_time - start_time
events.job_finish.fire(name=self.locust.name, jobtime=jobtime)
def execute_task(self, task, *args, **kwargs):
if hasattr(task, "__self__") and task.__self__ == self:
self._task_pool.spawn(task, *args, **kwargs)
elif hasattr(task, "tasks") and issubclass(task, TaskSet):
task(self).run(*args, **kwargs)
else:
self._task_pool.spawn(task, self, *args, **kwargs)
def schedule_task(self):
self._task_queue = []
for task in self.tasks:
task = {"callable":task,"args":[],"kwargs":{} }
self._task_queue.append(task)
random.shuffle(self._task_queue)- stats.py 增加MyEntry類,用來維護併發任務執行下的各種資料,後續統計測試結果的時候會用到。
class MyEntry(object):
name = None
num_jobs = None
job_times = None
total_job_time = None
min_job_time = None
max_job_time = None
def __init__(self,name):
.....
....
def log(self,jobtime):
self.num_jobs += 1
self.total_job_time += jobtime
if self.min_job_time == 0:
self.min_job_time = jobtime
else:
self.min_job_time = min( self.min_job_time, jobtime)
self.max_job_time = max( self.max_job_time, jobtime)
if jobtime < 100:
rounded_jobtime = jobtime
elif jobtime < 1000:
rounded_jobtime = round(jobtime,-1)
elif jobtime < 10000:
rounded_jobtime = round(jobtime,-2)
else:
rounded_jobtime = round(jobtime,-3)
self.job_times.setdefault(rounded_jobtime,0)
self.job_times[rounded_jobtime] += 1
@property
def avg_job_time(self):
if self.num_jobs == 0:
return 0
else:
return float(self.total_job_time)/self.num_jobs- web.py 修改requests_stats函式,增加針對併發任務的資料統計與計算。
for k,v in runners.locust_runner.job_stats.items():
stats.append({
"name": v.name,
"num_requests": v.num_jobs,
"avg_response_time": v.avg_job_time,
"min_response_time": v.min_job_time,
"max_response_time": v.max_job_time,
"num_failures": 0,
"current_rps": 0,
"median_response_time": 0,
"avg_content_length": 0
})除了以上三個地方之外還有其它一些地方的程式碼也需要修改,主要是用來支援任務併發執行後,一些資料統計與記錄等內容。整體來說本次優化所做的修改,修改的程式碼量在幾百行左右。
驗證測試
自己搭建了一個測試的php頁面,用於進行修改後的效果驗證。根據url的引數值,sleep對應的時間之後再進行響應,頁面的程式碼如下:<?php
sleep($_GET['a']);
?>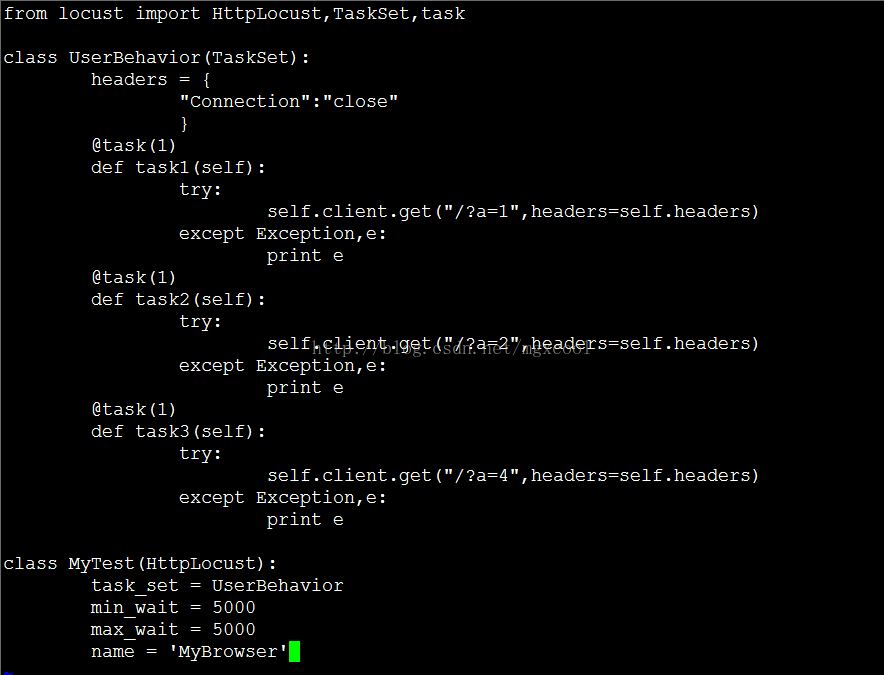
在MyTest中給name變數賦值為MyBrowser,之後在測試結果頁面,針對MyBrower的時長統計,都是該使用者每次併發請求所消耗的時長。結果如下:
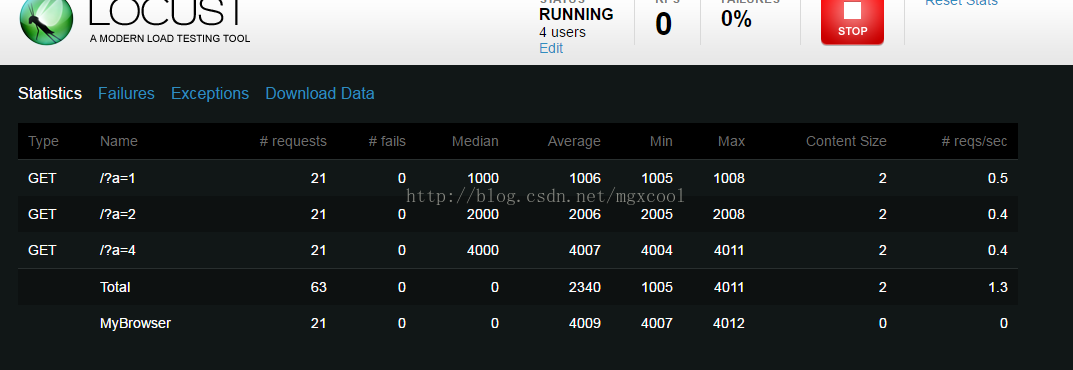
因為併發請求時,每次統計的是所有請求全部響應完成的時長,所以MyBrowser的結果中,平均時長是4s。 接下來我們驗證一下,在第一章節中反饋的問題b。 修改被測試頁面的程式碼,當請求介面a時,隨機sleep 1s或4s。請求介面b時,隨機sleep 2s或5s。 在locust測試指令碼中,對介面a b發起請求。
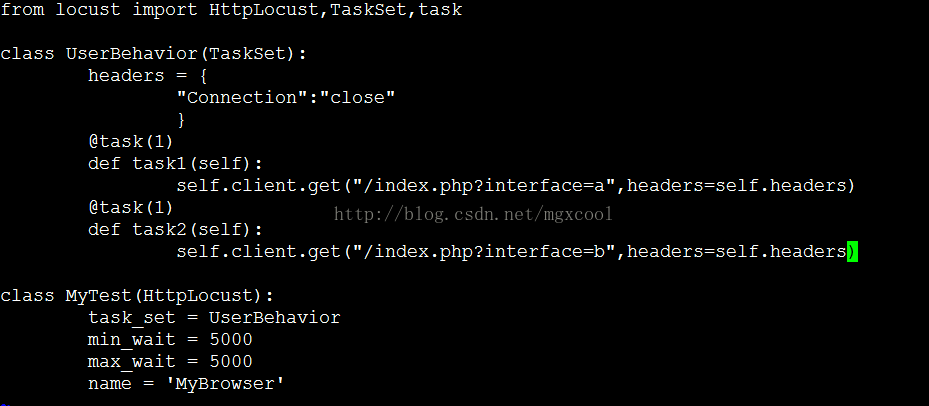
我們來看一下測試結果:

這裡可以看到,介面a的平均響應是2.5s。介面b的平均響應時長是3.5s。如果我們取最慢的那個介面,那麼按照老的思維方式,最終的效能結果是3.5s。 但是,如果以併發任務執行的時長為統計維度,我們看到MyBrower中統計的平均時長是4s。