
【C++系列小結】面向過程的程式設計風格
前言
程式語言有面向過程和麵向物件之分,因此程式設計風格也有所謂的面向過程的程式設計和麵向物件的程式設計,而且語言的性質不會限制程式設計的風格.
這裡主要說一下面向過程的程式設計.
“面向過程”(Procedure Oriented)是一種以過程為中心的程式設計思想。
C語言是面向過程的程式語言,但是依然可以寫出面向物件的程式,同樣C++也當然可以寫出面向過程的程式咯。
如果我們把所有的程式程式碼都寫在一個main函式裡面,那麼這個程式顯然會顯得很不和諧吧。理想一點的做法是我們把一些看起來和main函式邏輯上關聯可以獨立分開的、在高層次的抽象上有通用的操作的程式碼分離出來,形成呼叫函式。而這即是面向過程的程式設計。
面向過程的程式設計,即將函式獨立出來的好處有三:
1、以一連串函式呼叫操作取代重複編寫相同的程式程式碼,可以使程式更易讀。
2、可以在不同的程式中使用這些高層次抽象封裝的程式,比如之前的SICP中的抽象程式設計中的例子比比皆是。
3、可以根據功能和過程將專案分塊,更容易將工作協作給小組team完成。
一、如何編寫函式(How to write a function?)
以一個例子驅動講解:
這樣一個關於fibonacci數列的程式,使用者詢問概數列的第幾個元素是什麼,程式回答出該問題。
顯然計算fibonacci數列指定元素大小的這部分可以抽象出函式。如何編寫這個函式呢?
首先需要了解函式定義包括的內容:
四部分:
1、返回型別:即函式執行完如有需要返回給呼叫者的資料,其資料的資料型別
2、函式名:即是函式的名字,建議名字跟函式功能相關
3、引數列表:即是函式和呼叫者之間如果需要資料連線,接受呼叫者傳遞的資料,則是=需要有引數列表
4、函式體:即是函式的主體執行部分
具體各部分的含義就不再多說了吧。。。不懂的請自行google,畢竟不可能把所有的東西都說了。
是使用函式的時候需要注意的是函式必須先被宣告,然後才能被呼叫。這個道理很明白,就是你必須要想別人說你的名字,然後別人需要你的幫助的時候才能找到你(根據你的名字)。
函式的宣告讓編譯器得以檢查後續出現的函式的呼叫方式是否正確(引數的個數、型別是否匹配
具體的如何fibonacci數列程式的語句就不再寫了,這個看了fibonacci數列原理就很容易寫出來。
在編寫函式體的時候注意在函式的最後寫上return語句,返回給呼叫者期待的資料。
同時我們需要說的還有一個關於程式健壯性的問題,即是我們編寫的函式雖然是邏輯上對的,但是面對使用者千奇百怪的操作,他很有可能會掛掉。
這就需要我們去處理這些看起來不合理的操作,畢竟我們的程式是要為使用者服務的,我們必須站在大多數的使用者的角度考慮我們的程式將要遇到什麼問題,然後解決它。
首先可能遇到的問題是使用者不合理的請求,比如上面例子中,使用者詢問第-10或者2.5位置的元素,那麼顯然程式不可能給出答案,所以,我們就需要提示使用者請求不正確,並要求其輸入正整數位置的元素。
其次使用者如果詢問第10000位置的元素的大小的時候,我們的程式也會掛掉,因為這個數字太大,我們所採用的基本的資料型別都無法表示出來,那麼就需要為我們的程式“設限”,就是要先向使用者宣告,我們的程式可以做什麼,可以做到什麼程度,這樣算是一個負責任的宣告吧。在使用者超出程式的功能範圍的時候提示使用者即可。
上面說過要在程式的最後寫return語句,其實這樣的說法不太準確。更加嚴謹恰當的說法是:在每個函式的每個可能的退出點寫return語句。函式的退出點就是執行完某一條語句後,該函式將執行完畢的位置。
(如果返回資料型別是void,可以省略不寫return語句,但是個人建議寫空return,這樣使函式更加完整,可以很清楚知道函式的退出點,有始有終吧)
二、呼叫函式(Invoking a Function)
本節需要了解傳值(by value)和傳址(byreference)的引數傳遞方式。
關於這個很多人應該都瞭解,如果不瞭解,我們通過一個程式來看一下:
#include <iostream>
void swap (int a, int b);
int main()
{
int a = 1;
int b = 2;
swap(a ,b);
printf("After swap:%d,%d\n", a ,b);
return 0;
}
void swap(int a, int b)
{
int temp = a;
a = b ;
b = temp;
printf("In function of swapa & b: %d,%d\n", a ,b);
return;
}
程式的執行結果如下:
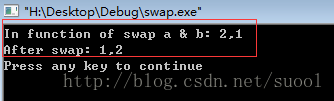
顯然,在main函式中的a,b在執行完swap函式之後並沒交換,但是在swap內部確實交換的。
我們理所當然的認為,我們把a,b傳遞給swap函式,他執行結束交換語句後,a和b的值也會改變,但是程式的執行結果卻並非如此,因此我們需要問自己這樣的問題:我們傳遞的真的a和b麼?
這就涉及到程式的執行時結構。
當我們在呼叫一個函式時候,會在記憶體中建一個特殊的區域,成為“程式堆疊”。這塊空間提供了每個引數的儲存空間。堆疊是兩種不同的記憶體結構,堆和棧。他們有著不同的使命和特點。
詳情參:http://www.cppblog.com/oosky/archive/2006/01/21/2958.html,堆疊的區別。
堆疊區域也提供了函式定義的每個物件的記憶體空間——我們將這些物件稱之為“區域性物件”,一旦函式完成,這些記憶體區域便會被釋放掉,即是這些區域中的資料也不會存在。
因此,我們所謂的將a,b傳入swap,並非真的將我們在main函式中定義的a,b傳入,而只是傳入其值的大小,在swap函式內部建立了對應的資料拷貝而已,簡單地說就是我們把a,b的大小告訴了swap函式,然後swap函式在其內部申請了兩個相同型別的空間A,B,來存著這樣兩個大小的資料,然後在swap執行的資料操作都是操作的A,B對應的空間的資料,所以,這swap中,資料被交換了,但是在main中並沒有被交換。
這就是傳值的實質。
那麼如何避免傳值,真正的改變我們的a和b呢?
要改變a和b,我們要知道如何去定位和a和b,就是如何在swap中找到我們在mian函式中定義的a和b,只有找到才能交換他們。
如何找到呢?顯然如果你要找一個人,我們知道他的地址的話,就一定可以找到他(非鑽牛角也沒辦法;))。程式也一樣,要找到a,b我們只需要知道a,b的地址就可以了,因此我們可以將他們的地址傳遞給swap函式,這就可真正的交換啦。如下:
#include <iostream>
void swap_value (int a, int b);
void swap_refer(int *a, int *b);
int main()
{
int a = 1;
int b = 2;
int *pa = &a;
int *pb = &b;
swap_value(a ,b);
printf("After by valueswap: %d,%d\n", a ,b);
swap_refer(pa, pb);
printf("After by referenceswap: %d,%d\n", a ,b);
return 0;
}
void swap_value(int a, int b)
{
int temp = a;
a = b ;
b = temp;
printf("In function ofswap_value a & b: %d,%d\n", a ,b);
return;
}
void swap_refer(int *a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
printf("In function ofswap_refer a & b: %d,%d\n", *a ,*b);
}
執行結果如下:
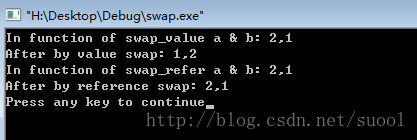
顯然此時的a,b被真正的交換了。
上面的例子我們引數是指標型別資料,傳遞的是指標,即是資料的地址。
在C++中我們也可以傳遞引數為引用的型別。在此不再示例。
我們要說的是Reference的語義:
他扮演外界與物件之間一個間接的手柄的角色。在型別名稱和reference之間插入一個&符號,便是聲明瞭一個reference。(具體的引用定義,用法神馬的不再詳細贅述)
而引用和指標資料實在是非常相似的東西,引用可以說是資料的另一個名字,引用裡面沒有儲存資料,只是一個對源物件的指向,使用物件的引用和使用該物件有一樣的效果。
而指標引數和reference引數更重要的差異是,pointer可能是指向某個實際的物件,當我們在提領pointer的時候,必須要確定該pointer的值非0,即是確實指向了某個物件,否則可能會引起指標異常。但是reference則不必。
因此在函式內操作資料的時候,如果僅僅需要在函式內部改變引數的值,那麼使用傳值就夠咯。
在此還需要注意的一個問題就是作用域的問題。其實更準確的說法是物件的生存期和作用和範圍。
這個一般的原則應該都知道,就是全域性物件和區域性物件的生存期和作用範圍(如其名)。
內建型別的物件,如果定義在file scope內,必定會初始化為0,如果定義在local scope之內,則除非顯示指定初值,否則不會被初始化。
除了file scope和local scope,還有第三種生存期的形式dynamicextent,即動態範圍。其記憶體是上面所說的堆,heap memory(堆記憶體)。這種記憶體必須有程式設計師來操作。
之所以被稱之為dynamic,只因為在程式中可以動態的增加,new出新的記憶體,直至我們顯示的delete才會釋放。
如果我們一直new,而沒有delete,就會導致記憶體洩露和溢位。。這是程式崩潰的主要原因之一。
三、提供預設的引數值(Providing Default Parameter Values)
在使用“引數傳遞”作為程式間的溝通方式的同時,我們很容易就會面臨引數預設值的問題,因為存在著不需要輸入全部引數值的情況。
預設引數值的宣告方法是:
void swap_refer(int &f, int *a, int *b = 3)
此時的第三個引數預設是3。如果要把預設值置為0,則必須要是pointer型別,因為reference不同於pointer不能被設定為0。因此reference必須代表某個物件。
關於預設值的提供,有兩個很不直觀的規則。第一個規則,預設值的解析操作有最右邊開始,如果我們提供了預設值,那麼這一引數右側的所有引數都必須預設值。第二個規則是預設值只能指定一次,可以在函式的宣告處,可以在函式定義處,但是不能再兩個地方同時指定。(推薦宣告的時候)。
四、使用區域性靜態物件和宣告inline函式
在一些需要重複計算的函式中,由於在函式的內部定義的變數集合都是區域性變數,每次呼叫結束都會被釋放,因此每次呼叫也都會重複計算。但是如果為了節省函式間通訊的問題而降物件定義與file scope內,則是一種冒險。因為通常file scop的物件會打亂函式間的獨立性,使程式變得難以理解。
一個比較合理的解決方法便是使用區域性靜態物件。
和區域性非靜態物件不同的是,區域性靜態物件所處的記憶體空間,即使在不同的呼叫過程中,依然持續存在,即是計算過的過程,不會在呼叫結束被釋放結束。
關於inline函式,只需要在函式前面加inline關鍵字即可。
將函式宣告為inline僅僅是對編譯器提出一種要求。編譯器是否執行這項請求,需視編譯器而定。
一般而言,適合宣告為inline函式的函式是:體積小,常被呼叫,所從事的計算並不複雜。
inline函式的定義常在標頭檔案中,由於編譯器必須在他被呼叫的時候加以展開,所以這個時候其定義必須是有效的。
五、過載函式(Override Function)
過載函式在其他的高階語言中經常見到,這個概念對大多數人來說都不默陌生,所謂的過載的函式就,其實就是一個名字的函式,但是有多個實現的方式。
既然函式名字一樣,編譯器如何知道呼叫的是那一個函式呢?不要忘記了之前所說的函式宣告,宣告包括返回型別,函式名,引數列表,藉此得以讓編譯器檢查函式呼叫的正確與否。因此,顯然編譯器通過識別引數的型別,個數類判斷。
需要注意的是,編譯器無法根據返回型別來判斷和區分兩個有相同名稱和引數的函式。為什麼呢?因為我們呼叫的時候沒有使用返回型別呀,我們只是使用這個名字和引數來呼叫的哦。
六、定義和使用模板函式(Define and Using Template Functions)
所謂的模板函式,其實只是一個更高階的抽象罷了,這個機制在Lisp這種先祖語言中早就有了。
為什麼要模板函式呢?
正如上面所說的,為了更高階的抽象,比如我們有一系列的過載函式,僅僅是引數的資料型別不一樣,但是函式內部操作都有一定的模式,即是在更高階的抽象層次上,忽略資料型別的話,他們可以視作一個函式,因此,為了簡化抽象,減少重複編碼,便產生了所謂的“template function”。
Template function以關鍵字template開始,其後緊跟尖括號<>包圍起來的一個或多個標示符,這些標示符可以表示我們希望推遲確定的資料型別。每次使用者使用這一個模板的時候,必須提供對應的型別資訊。這些標示符就是起著佔位符的作用。當然,模板函式也可以被再次過載。
具體的模板函式不在此詳解,畢竟這是一個很重要也很複雜的內容。
七、函式指標
所謂的函式指標,其形式相當複雜,他所指明的是函式的返回型別及函式類表。
即是有一系列的相同型別的函式,只是名字不一樣,這看起來就像是一系列的整型變數一樣,我們可以把整型變數放在一個數組中,當然也可以把這一系列的函式放在一個數組中,每個元素就是該函式的地址,函式名字就是函式的首地址,因此便產生了函式指標。
八、設定標頭檔案
函式有一個一次定義多次宣告的規則,即是在整個程式專案中,同一個函式的定義只能出現一次,可以多次宣告,但是有時為了避免多次宣告,可以將這樣的函式宣告放在標頭檔案中。然後在每個使用該函式的程式程式碼中包含該標頭檔案即可。
同時有一個例外,就是inline函式,為了能夠擴充套件inline函式的內容,在每個呼叫點上,編譯器都必須取得其定義,因此將其定義在標頭檔案中是最恰當的。
同時我們需要注意函式的宣告和定義的區別。
//下面的會被認為是定義而非宣告
Const int seq = 4;
Const vector<int > *(*seq_arry[seq]) (int)
只要在上述定義前面加速extern即可變成宣告。
但是為什麼步子啊上面的int seq前面加上extern呢?
這是因為const object和inline函式一樣,也是一例外,constobject 的定義只要一出文件之外就不可見。
關於引用標頭檔案的雙引號和尖括號之間的區別:
如果標頭檔案和包含此檔案的程式碼在同一個磁碟目錄,使用引號,否則使用尖括號。
更專業的回答是:
如果此檔案被認為是標準或者專屬的標頭檔案,便以尖括號,編譯器在搜尋改檔案的時候會在預設的目錄尋找,如果是引號,則認為是使用者自定義的,編譯器便會在包含此檔案的目錄開始找。