
XML兩種解析思想:DOM和SAX
一、什麼是XML
英文全稱為Extensible Markup Language,翻譯過來為可擴充套件標記語言。現實生活中存在著大量的資料,在這些資料之間往往存在一定的關係,我們希望能在計算機中儲存和處理這些資料的同時能夠儲存和處理他們之間的關係。XML就是為了解決這樣的需求而產生的資料儲存格式。
在XML語言中,它允許使用者自定義標籤。每一個標籤用於描述一段資料。一個標籤可以分為開始標籤和結束標籤,在開始標籤和結束標籤之間又可以巢狀其它標籤,利用標籤間的巢狀關係來儲存資料之間的上下級關係;由於XML實質上是一段字串,計算機可以十分方便的對他進行操作,開發人員也可以方便的閱讀,因此可以說這是一種對人、對計算機都友好的資料儲存格式,所以XML迅速普及,成為了一種非常常見的資料儲存格式,在許多應用場景中得到應用。
二、xml的應用場景
1、傳輸資料
XML本質上是一段字串,具有跨平臺性的特性,因此XML常被用來在不同系統之間進行資料交換。一個典型的android應用是由伺服器傳送資訊給android客戶端後,由android客戶端負責展示。此時,android客戶端是java+android開發環境的。而伺服器端很可能是C#+windows開發環境。如何在不同的語言、不同作業系統之間傳輸資料呢?XML就是一個很好的選擇。
2、配置檔案
XML可以在儲存資料的同時儲存資料之間的關係。利用這一特點,它還經常用作應用程式配置檔案來使用。
三、XML檢驗
瀏覽器除了內建HTML解析器外還內建了XML解析器,因此我們可以使用瀏覽器對XML進行校驗。
四、HTML和XML的區別
(一)語法要求不同
- 在HTML中不區分大小寫,在XML中嚴格區分。
- 在HTML中,有時不嚴格,如果上下文清楚地顯示出段落或者列表鍵在何處結尾,那麼你可以省略或者 之類的結束標記。在XML中,是嚴格的樹狀結構,絕對不能省略掉結束標記。
- 在XML中,擁有單個標記而沒有匹配的結束標記的元素必須用一個/ 字元作為結尾。這樣分析器就知道不用查詢結束標記了。
- 在XML中,屬性值必須分裝在引號中。在HTML中,引號是可用可不用的。
- 在HTML中,可以擁有不帶值的屬性名。在XML中,所有的屬性都必須帶有相應的值。
- 在XML文件中,空白部分不會被解析器自動刪除;但是HTML是過濾掉空格的。
(二)標記不同
1、HTML使用固有的標記;而XML沒有固有的標記。
2、HTML標籤是預定義的;XML標籤是免費的、自定義的、可擴充套件的。
(三)作用不同
- HTML是用來顯示資料的;XML是用來描述資料、存放資料的,所以可以作為持久化的介質!HTML將資料和顯示結合在一起,在頁面中把這資料顯示出來;XML則將資料和顯示分開。 XML被設計用來描述資料,其焦點是資料的內容。HTML被設計用來顯示資料,其焦點是資料的外觀。
- XML 不是HTML的替代品,XML 和HTML是兩種不同用途的語言。 XML 不是要替換 HTML;實際上XML 可以視作對 HTML 的補充。XML 和HTML 的目標不同HTML 的設計目標是顯示資料並集中於資料外觀,而XML的設計目標是描述資料並集中於資料的內容。
- 沒有任何行為的XML。與HTML 相似,XML 不進行任何操作。(共同點)
- 對於XML最好的形容可能是: XML是一種跨平臺的,與軟、硬體無關的,處理與傳輸資訊的工具。
- XML未來將會無所不在。XML將成為最普遍的資料處理和資料傳輸的工具。
五、XML的語法
xml的語法:文件宣告、元素、屬性、註釋、CDATA區(轉義字元)、處理指令
(一)文件宣告
用來宣告XML 的基本屬性,用來指揮解析引擎如何去解析當前XML 。通常一個XML 都要包含並且只能包含一個文件宣告。XML 的文件宣告必須在整個XML 的最前面,在文件宣告之前不能有任何內容。
<?xml version="1.0" ?>
version是必須存在的屬性,表明當前xml所遵循規範的版本,目前位置都寫1.0就可以了。
<?xml version="1.0" encoding="utf-8" ?>
一定要保證xml格式的資料在儲存時使用的編碼和解析時使用的編碼必須一致,才不會有亂碼問題
<?xml version="1.0" encoding="utf-8" standalone="yes" ?>
standalone屬性用來指明當前xml是否是一個獨立的xml,預設值是yes表明當前文件不需要依賴於其他文件,
如果當前文件依賴其他文件而存在則需要將此值設定為no
(二)元素
元素的語法
- 一個XML 標籤就是一個元素
- 一個標籤分為開始標籤和結束標籤
- 在開始標籤和結束標籤之間可以包含文字內容,這樣的文字內容叫做標籤體
- 如果標籤的開始標籤和結束標籤之間不包含標籤和子標籤則可以將開始標籤和結束標籤進行合併,這樣的標籤就叫做自閉標籤
- 一個標籤中也可以包含任意多個子標籤,但是一定要注意標籤一定要合理巢狀
- 一個格式良好的XML 要包含並且只能包含一個根標籤,其他的標籤都應該是這個標籤的子孫標籤
元素的命名
- 區分大小寫,例如,
<C>和<c>是兩個不同的標記。 - 不能以數字或標點符號或”_”開頭。
- 不能以xml(或XML、或Xml 等)開頭。
- 不能包含空格
- 名稱中間不能包含冒號(:)。
(三)屬性
- 一個標籤可以有多個屬性,每個屬性都有它自己的名稱和取值,例如:
<china capital="beijing"/> - 屬性的名在定義時要遵循和XML 元素相同的命名規則
- 屬性的值需要用單引號或雙引號括起來
(四)註釋
- 註釋可以出現在XML 文件的任意位置除了整個文件的最前面,不能出現在文件宣告之前。
- 註釋不能巢狀註釋。
(五)CDATA區/轉義字元
當XML中一段內容不希望被解析器解析時可以使用CDATA區將其包住。當解析器遇到CDATA區時會將其內容當作文字對待,不會進行解析
語法:<![CDATA[ 內容 ]]>
轉義字元:
& --> &
< --> <
> --> >
" --> "
' --> '
( 六)處理指令
處理指令,簡稱PI (processing instruction)。處理指令用來指揮解析引擎如何解析XML文件內容。
<?xml-stylesheet type="text/css" href="1.css"?>
六、XML的兩種解析思想
XML程式設計: 利用java程式去增刪改查(CRUD) XML 中的資料。
解析思想: DOM解析和SAX解析
1、DOM解析
DOM(Document Object Model) 它是 W3C 組織推薦的處理 XML 的一種方式。它會將整個XML使用類似樹的結構儲存在記憶體中,再對其進行操作,所以它需要等到XML完全載入進記憶體才可以進行操作。它的缺點是耗費記憶體,當解析超大的XML時慎用。優點是可以方便的對XML 進行增刪改查的操作。
在java SE的api提供了org.w3c.dom包裡面有Node介面,此介面中提供了很多增刪改查節點的方法,而所有文件樹的物件都實現這個介面。
2、SAX解析
這種解析方式會逐行地去掃描XML文件,當遇到標籤時會觸發解析處理器,採用事件處理的方式解析XML (Simple API for XML) ,不是官方標準,但它是 XML 社群事實上的標準,幾乎所有的 XML 解析器都支援它。優點是:在讀取文件的同時即可對XML進行處理,不必等到文件載入結束,相對快捷。不需要載入進記憶體,因此不存在佔用記憶體的問題,可以解析超大XML。缺點是:只能用來讀取XML中資料,無法進行增刪改。
它需要解析器和事件處理器,其中事件處理器裡面的操作需要開發人員實現,註冊到解析器中,解析器逐行掃描XML檔案會呼叫事件處理器中的方法。
基於這兩種解析思想市面上就有了很多的解析api
- sun jaxp既有dom方式也有sax方式,並且這套解析api已經加入到j2se的規範中,意味這不需要匯入任何第三方開發包就可以直接使用這種解析方式。但是這種解析方式效率低下,沒什麼人用。
- dom4j 可以使用dom方式高效的解析xml。匯入開發包,通常只需要匯入核心包就可以了,如果在使用的過程中提示少什麼包到lib目錄下在匯入缺少的包即可。
3、SAX解析使用
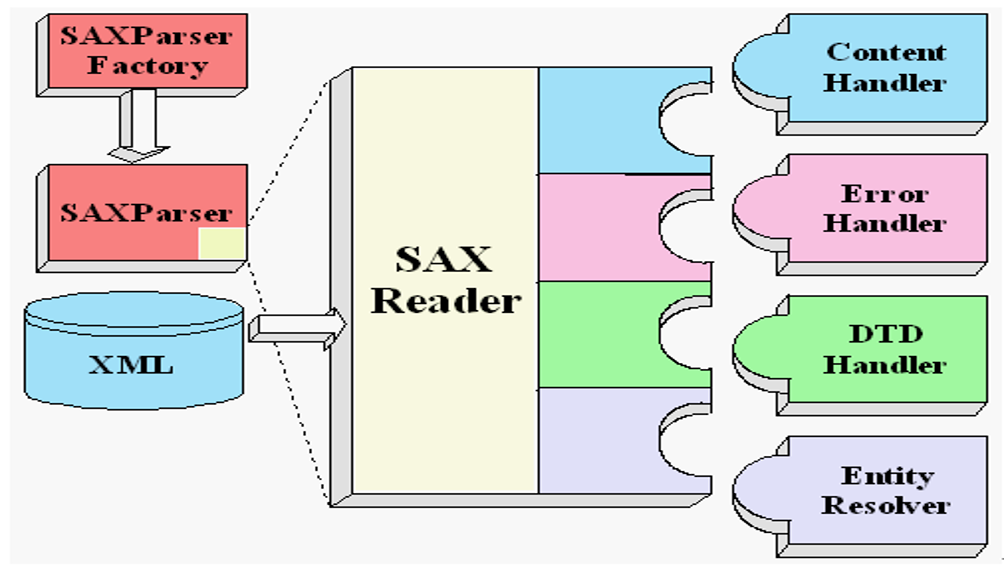
SAX解析的步驟:
//1、使用SAXParserFactory建立SAX解析工廠
SAXParserFactory spf = SAXParserFactory.newInstance();
//2、通過SAX解析工廠得到解析器物件
SAXParser sp = spf.newSAXParser();
//3、通過解析器物件得到一個XML的讀取器
XMLReader xmlReader = sp.getXMLReader();
//4、設定讀取器的事件處理器
xmlReader.setContentHandler(new MyContentHandler());
//5、解析xml檔案
xmlReader.parse("book.xml");已知xml檔案book.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<書架>
<書>
<書名>Java程式設計</書名>
<作者>張三</作者>
<售價>20.00元</售價>
</書>
<書>
<書名>Java設計模式</書名>
<作者>李四</作者>
<售價>30.00元</售價>
</書>
</書架>
SAX實現輸出第二本書的書名的功能原始碼:
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.ContentHandler;
import org.xml.sax.Locator;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
public class SaxDemo{
public static void main(String[] args) throws Exception {
//1.獲取解析器工廠
SAXParserFactory factory = SAXParserFactory.newInstance();
//2.通過工廠獲取sax解析器
SAXParser parser = factory.newSAXParser();
//3.獲取讀取器
XMLReader reader = parser.getXMLReader();
//4.註冊事件處理器
reader.setContentHandler(new MyContentHandler2() );
//5.解析xml
reader.parse("book.xml");
}
}
//介面卡設計模式
class MyContentHandler2 extends DefaultHandler{
private String eleName = null;
private int count = 0;
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
this.eleName = name;
}
public void characters(char[] ch, int start, int length)
throws SAXException {
if("書名".equals(eleName) && ++count==2){
System.out.println(new String(ch,start,length));
}
}
public void endElement(String uri, String localName, String name)
throws SAXException {
eleName = null;
}
}4、DOM4J解析XML文件
Dom4j是一個簡單、靈活的開放原始碼的庫。Dom4j是由早期開發JDOM的人分離出來而後獨立開發的。與JDOM不同的是,dom4j使用介面和抽象基類,雖然Dom4j的API相對要複雜一些,但它提供了比JDOM更好的靈活性。
Dom4j是一個非常優秀的Java XML API,具有效能優異、功能強大和極易使 用的特點。現在很多軟體採用的Dom4j,例如Hibernate,包括sun公司自己的JAXM也用了Dom4j。
使用Dom4j開發,需下載dom4j相應的jar檔案。
(一)DOM4j解析xml檔案
//建立解析器:
SAXReader reader = new SAXReader();
//利用解析器讀入xml文件:
Document document = reader.read(new File("input.xml"));
//獲取文件的根節點:
Element root = document.getRootElement();(二)DOM4j節點操作
//1.取得某個節點的子節點.
Element element =ele.element(“書名");
List elementList =ele.elements(“書名");
List elementList =ele.elements();
//2.獲取節點的名字
node.getName();
//3.設定節點的名字
node.setName(String newName);
//4.取得節點的文字(標籤體)
String text=node.getText()
//5.設定節點的文字(標籤體)
node.setText("aaa");
//6.新增子節點.
ele.add(Element e);ele.addElement("age");
//7.刪除子節點節點.
parentElm.remove(childElm);
//8.獲取節點型別
node.getNodeType() ;
//9.獲取父節點
node.getParent();
//10.取得某節點物件的某屬性
Attribute attr= ele.attribute("aaa");
Attribute attr= ele.attribute(0);
List list = ele.attributes();
String value = ele.attributeValue("aaa");
Iterator it = ele.attributeIterator();
//11.設定某節點的屬性
ele.add(Attribute attr);
ele.addAttribute(name, value);
ele.setAttributes(List attrs);
//12.刪除某屬性
ele.remove(attribute);
/*13.在指定位置插入節點
1)得到插入位置的節點列表(list)
2)呼叫list.add(index,elemnent),由index決定element的插入位置。Element元素可以通過DocumentHelper物件得到。示例程式碼:
*/
Element aaa = DocumentHelper.createElement("aaa");
aaa.setText("aaa");
List list = root.element("書").elements();
list.add(1, aaa);(三)DOM4j屬性
//1.取得屬性的名、值
String name = attribute.getName();
String value = attribute.getValue();
//2.設定某屬性的名、值
attribute.setName();
attribute.setValue();(四)DOM4j字串和XML的轉換
//1.將字串轉化為XML
String text = "<members> <member>sitinspring</member></members>";Document document = DocumentHelper.parseText(text);
//2.將文件或節點的XML轉化為字串.
String xmlStr = node.asXML();(五)DOM4j將文件寫入XML檔案
方式一:
呼叫Node提供的write(Writer writer) 方法,使用預設方式將節點輸出到流中:
node.write(new FileWriter("book.xml"));亂碼問題:Dom4j在將文件載入記憶體時使用的是文件宣告中encoding屬性宣告的編碼集進行編碼,如果在此時使用的writer的內部編碼集與最初載入記憶體時使用的編碼集不同則會出現亂碼問題。FileWriter預設使用作業系統本地碼錶即gb2312編碼,並且無法更改。此時可以使用如下的方式自己封裝一個指定碼錶的Writer使用,從而解決亂碼問題。
OutputStreamWriter(FileOutputStream("filePath"),"utf-8");
方式二:
利用XMLWriter寫出Node:
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"));
writer.write(node); writer.close();
注意:使用這種方式輸出時,XMLWriter首先會將記憶體中的docuemnt翻譯成UTF-8格式的document再進行輸出,這時有可能出現亂碼問題。可以使用OutputFormat 指定XMLWriter轉換的編碼為其他編碼。
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GBK");
XMLWriter writer = new XMLWriter(newFileWriter("output.xml"),format);
Writer使用的編碼集與文件載入記憶體時使用的編碼集不同導致亂碼,使用位元組流或自己封裝指定編碼的字元流即可。
(六)DOM4j–DocumentHelper
createDocument();
createDocument(Element rootEle
createAttribute(Element owner, String name, String value));
createElement(String name);
Docuemnt parseText(String text);5. DOM4J編碼示例
入門示例:針對上面的book.xml列印第一本書的名字:
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Dom4jDemo1 {
public static void main(String[] args) throws Exception {
//1.獲取解析器
SAXReader reader = new SAXReader();
//2.解析xml獲取代表整個文件的dom物件
Document dom = reader.read("book.xml");
//3.獲取根節點
Element root = dom.getRootElement();
//4.獲取書名進行列印
String bookName = root.element("書").element("書名").getText();
System.out.println(bookName);
}
}示例2:對dom元素和屬性進行增刪改查的操作
import java.io.FileOutputStream;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class Demo4jDemo2 {
@Test
public void attr() throws Exception{
SAXReader reader = new SAXReader();
Document dom = reader.read("book.xml");
Element root = dom.getRootElement();
Element bookEle = root.element("書");
//bookEle.addAttribute("出版社", "傳智出版社");
// String str = bookEle.attributeValue("出版社");
// System.out.println(str);
Attribute attr = bookEle.attribute("出版社");
attr.getParent().remove(attr);
XMLWriter writer = new XMLWriter(new FileOutputStream("book.xml"),OutputFormat.createPrettyPrint());
writer.write(dom);
writer.close();
}
@Test
public void del() throws Exception{
SAXReader reader = new SAXReader();
Document dom = reader.read("book.xml");
Element root = dom.getRootElement();
Element price2Ele = root.element("書").element("特價");
price2Ele.getParent().remove(price2Ele);
XMLWriter writer = new XMLWriter(new FileOutputStream("book.xml"),OutputFormat.createPrettyPrint());
writer.write(dom);
writer.close();
}
@Test
public void update()throws Exception{
SAXReader reader = new SAXReader();
Document dom = reader.read("book.xml");
Element root = dom.getRootElement();
root.element("書").element("特價").setText("4.0元");
XMLWriter writer = new XMLWriter(new FileOutputStream("book.xml"),OutputFormat.createPrettyPrint());
writer.write(dom);
writer.close();
}
@Test
public void add()throws Exception{
SAXReader reader = new SAXReader();
Document dom = reader.read("book.xml");
Element root = dom.getRootElement();
//憑空建立<特價>節點,設定標籤體
Element price2Ele = DocumentHelper.createElement("特價");
price2Ele.setText("40.0元");
//獲取父標籤<書>將特價節點掛載上去
Element bookEle = root.element("書");
bookEle.add(price2Ele);
//將記憶體中的dom樹會寫到xml檔案中,從而使xml中的資料進行更新
// FileWriter writer = new FileWriter("book.xml");
// dom.write(writer);
// writer.flush();
// writer.close();
XMLWriter writer = new XMLWriter(new FileOutputStream("book.xml"),OutputFormat.createPrettyPrint());
writer.write(dom);
writer.close();
}
@Test
public void find() throws Exception{
SAXReader reader = new SAXReader();
Document dom = reader.read("book.xml");
Element root = dom.getRootElement();
List<Element> list = root.elements();
Element book2Ele = list.get(1);
System.out.println(book2Ele.element("書名").getText());
}
}